






神经机器翻译(NMT)是一种将一序列的文字从一种语言翻译成另一种语言的自动任务。近年来,有自注意力机制 Transformer 模型的发展对复杂语言建模任务产生了深远的影响,这些任务的目标是预测句子中下一个即将出现的分词,而 NMT 是其中一个典型的应用例子。
在开源社区中有很多 NMT 模型,而在实际使用场景中直接用它们来翻译文本却富有挑战性。一些常见的难点包括:
- 误译
- 缺乏语义准确性
- 缺乏特定领域的知识
- 不能处理专有名词或生僻词
这些问题的其中一个根因是训练模型的数据与实际使用场景中的数据分布不匹配。这意味着模型微调是一个必要的步骤。
NVIDIA NeMo 是一个端到端的平台,它可在任何地方开发和定制生成式人工智能,包括大型语言模型、多模态、视觉以及语音 AI 等应用。该平台提供了用于训练和检索增强生成(RAG)工具、大模型护栏工具、数据管理工具和各种预训练模型。NeMo 为企业提供了一种简单、经济、快速的方式来使用生成式 AI。
(更多 NVIDIA NeMo 介绍可点击查看: NVIDIA NeMo 是什么?一文拆解 NeMo 框架及组件)
在这篇文章中,我们将介绍使用 NeMo 的前提条件,使用 NeMo 进行预训练模型推理,并评估预训练模型的性能。此外,在第二部分中,我们将介绍如何定制数据集、数据处理和微调模型的过程。
前提条件
通过 NGC 目录,您可以访问 GPU 加速的软件,这些软件可以在本地、云端或边缘部署,从而加快端到端的工作流程。该目录提供了极高性能的容器、预训练模型和各个行业专用的 SDK。
在本教程中,我们使用 NGC 目录中的 NeMo framework 容器 24.01 对 NMT 模型进行微调。
在启动容器之前,我们推荐您先配置基础环境:
- NVIDIA RTX 5000 Ada GPU(32GB 显存)
- 操作系统:Ubuntu 22.04
- 获取最新的 NVIDIA GPU 驱动程序
- 安装Docker Engine
- NVIDIA Container Toolkit
- 获取 NVIDIA NGC NeMo framework 容器 的访问权限
生成 NGC API 密钥,然后登录 Docker NGC Registry:
| docker login http://nvcr.io Username: $oauthtoken Password: |
使用以下命令启动 NeMo 框架容器:
docker run --runtime=nvidia -it --rm -p 8888:8888 -p 6006:6006 --shm-size=16g --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/nemo:24.01.framework机器翻译介绍
自 20 世纪 50 年代以来,机器翻译一直是受关注的研究领域。在 2010 年前,基于规则和基于统计的机器翻译是主流的研究方向。基于规则的方法可通过分析源语言和目标语言的形态、句法和语义从而生成翻译。后来,基于统计的机器翻译通过使用统计模型来预测目标词的概率分布而逐步取代了前者。
随着深度神经网络在 2010 年代的进步,NMT 已成为如今最流行的翻译方法。在研究发展的进程中,NMT 的翻译质量得益于递归神经网络(RNN)、长短期记忆网络(LSTM)、基于注意力机制的编码器-解码器网络和仅有解码器的 LLM 模型。
这篇文章使用了两种 NMT 模型作为示例,分别是 NVIDIA NeMo NMT 和基于大语言模型训练的 ALMA-NMT,展示了如何在定制数据集上微调模型的过程。
NVIDIA NeMo NMT 模型
NeMo 使您能够轻松高效地创建、定制和部署新的生成式人工智能模型。它还为不同的自然语言处理(NLP)任务提供了预训练模型,如 NMT、自动语音识别(ASR)和文本到语音(TTS)。NeMo NMT 模型是一系列的双语翻译模型,它们具有基于自注意力机制的编码器-解码器结构,其中编码器中有 24 层,解码器中有 6 层。它们在 NeMo 上使用公开的翻译数据集进行训练。
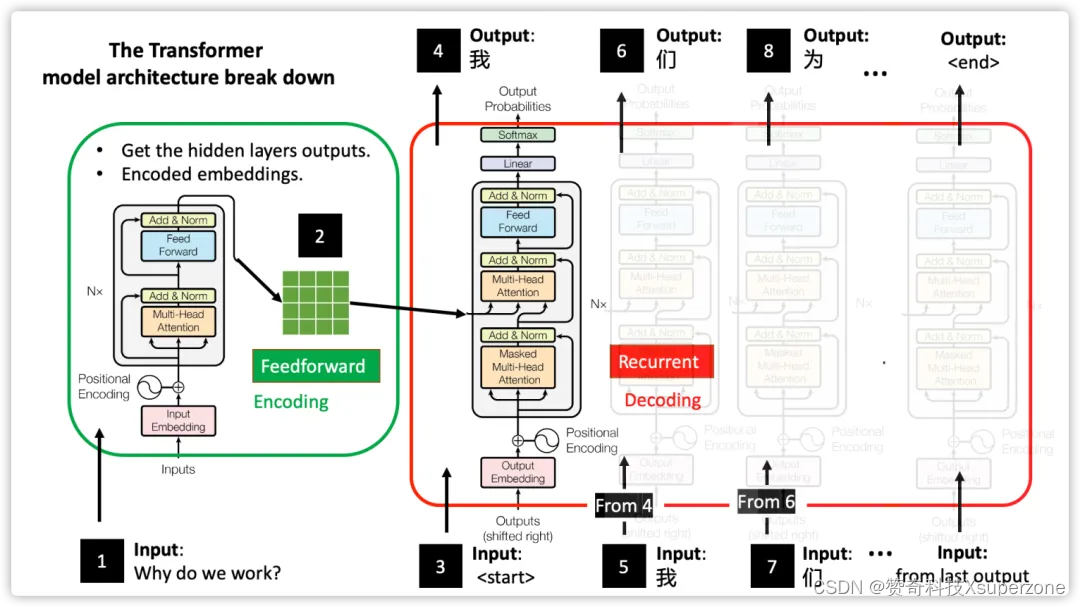
图 1:基于自注意机制的编码器-解码器 Transformer 架构的翻译过程
图片来源: The Annotated Transformer: English-to-Chinese Translator)
ALMA NMT 模型
ALMA 是一种基于大语言模型(仅有解码器)的多语言翻译模型。它对预训练 LLM 模型,如 Llama 2 ,进行单语语料库继续训练(第 1 阶段)。接着,通过使用双语数据集并应用 低秩适配器(LoRA) 进行微调,以进一步提高性能(第 2 阶段)。
与基于编解码器的模型相比,仅有解码的模型将 NMT 视为下游任务,将指令提示作为模型输入的一部分。在预训练和继续训练阶段,对模型进行训练在单语语料库上进行,并以预测下一个输出分词为目标,而双语数据集仅在 LoRA 微调阶段中使用。
NMT 模型定制流程
博客中使用了两种 NMT 模型,因为它们代表了两种类型的微调方式:
- NeMo NMT 模型:使用 NeMo 框架训练和微调而成。
- ALMA 模型:在 HuggingFace 和 GitHub 上的开源项目,它在微调中采用了 Accelerate 库。
两种方式都有一个相同的定制化流程,但由于训练框架的差异,在特定步骤上有细微的不同。
接下来的章节会遵循模型微调流程的顺序进行叙述:
- 运行预训练 NMT 模型。
- NMT 模型评估。
在文章的 第 2 部分 中,我们涵盖以下步骤:
- 数据收集。
- 数据预处理流程。
- 模型微调。
- 微调模型评估。
模型定制化的第一步是调研社区上公开的模型,并使用从实际使用场景中收集或模拟生成的一小部分数据集去评估其初始性能。当您发现这些模型都不满足需求时,就需要进行定制化开发。
数据收集和预处理是定制中必须的步骤,数据质量对最终的微调模型有着巨大的影响。收集的数据应该遵循真实使用场景的分布。它们应该经过预处理以去除异常值,有时也需要进行归一化。
下一步是在预训练的模型之上使用处理后的数据集进行微调。在本教程中,我们将使用双语数据集演示 NeMo NMT 微调和 ALMA 模型 LoRA 微调(第 2 阶段)。最后,对微调后的模型再次进行模型评估。
模型定制是一个迭代的过程,直到在实际使用场景中达到满意的性能。
运行预训练的 NMT 模型
当您进入 NeMo framwork 容器后,您可以对各种预训练的 NMT 模型运行推理,并测试它们的初始性能。
运行预训练 NeMo NMT 模型推理
在 NeMo 容器中下载预训练的 NeMo NMT 模型并运行推理十分简单。在此,我们用了 英文到简体中文的翻译模型 作为例子。
在 NeMo 框架容器中运行以下 Python 脚本:
from nemo.collections.nlp.models import MTEncDecModel
model = MTEncDecModel.from_pretrained("nmt_en_zh_transformer24x6")
translations=model.translate(["AI is powering change in every industry"], source_lang="en", target_lang="zh")
print(translations)
执行结果如下:
[“AI 正在推动每个行业的变革”]
开推断预训练的 ALMA NMT 模型
ALMA 在 HuggingFace 上提供了经过 LoRA 微调后的模型。为了在 NeMo framework 容器中运行这个模型,需要安装额外的 peft 依赖,以便加载 LoRA 权重。
| pip install peft |
以下是 ALMA 的推理代码示例:
import torch
from peft import PeftModel
from transformers import AutoModelForCausa
from transformers import LlamaTokenizer
# Load base model and LoRA weights
model = AutoModelForCausalLM.from_pretrained("haoranxu/ALMA-7B-Pretrain", torch_dtype=torch.float16, device_map="auto")
model = PeftModel.from_pretrained(model, "haoranxu/ALMA-7B-Pretrain-LoRA")
tokenizer = LlamaTokenizer.from_pretrained("haoranxu/ALMA-7B-Pretrain", padding_side='left')
# Add the source sentence into the prompt template
prompt_template = "Translate this from English to Chinese:\nEnglish: {}\nChinese:"
prompt = prompt_template.format("AI is powering change in every industry")
# Tokenize
input_ids = tokenizer(prompt, return_tensors="pt", padding=True, max_length=40, truncation=True).input_ids.cuda()
# Inference
with torch.no_grad():
generated_ids = model.generate(input_ids=input_ids, num_beams=5, max_new_tokens=256, do_sample=True, temperature=0.6, top_p=0.9)
结果如下:
['Translate this from English to Chinese:\nEnglish: AI is powering change in every industry\nChinese: 人工智能正在推动各行各业的变革’]
提示模板 "Translate this from English to Chinese:\nEnglish: {}\nChinese:" 被用作 LLM 的指令,LLM 的输出会把这个提示语句补充完整。您还必须对输出进行后处理,以提取实际翻译结果。
NMT 模型评估
我们可通过对预训练模型的评估更深入了解模型的表现和以及对微调结果的有所预期。
通常,机器翻译质量的评估采用双语评估替补(BLEU)算法,该算法通过比较 n-gram 匹配来衡量生成的翻译文本和参考文本之间的相关性。其评估分数范围从 0 到 1,分数越高,表示两者相关性越大。
NeMo 框架容器已安装了 sacrebleu 库,可用于基准测试并得出 BLEU 分数:
| sacrebleu reference.txt -i generated.txt -m bleu -b -w 4 |
这个 generated.txt 文件是机器生成的翻译,而 reference.txt 是参考译文。这两个文件每一行都是一一对应的关系。在这个执行命令时,使用了以下参数:
- -m bleu 表示使用 BLEU 标准来评估模型性能。
- -b 表示仅输出 BLEU 的评估分数。
- -w 4 表示显示小数点后4位。
您可以从实际使用场景中收集定制一个双语数据集作为评估集,使用上一章中提及的推理代码为数据集生成翻译,并评估预训练的模型性能。
对于 NeMo NMT 模型,NeMo 框架提供了用于逐行翻译文件的脚本。以下命令将预训练的英文到中文的 NeMo 翻译模型,并评估其对 input_en.txt 文件的性能。
# Download the pretrained en-zh NeMo model
mkdir -p model/pretrained_ckpt
wget -O en_zh_24x6.zip --content-disposition "https://api.ngc.nvidia.com/v2/models/nvidia/nemo/nmt_en_zh_transformer24x6/versions/1.5/zip"
unzip en_zh_24x6.zip -d model/pretrained_ckpt
rm en_zh_24x6.zip
# Translation script
python /opt/NeMo/examples/nlp/machine_translation/nmt_transformer_infer.py \
--model model/pretrained_ckpt/en_zh_24x6.nemo \
--srctext input_en.txt \
--tgtout pretrained_nemo_out_zh.txt \
--source_lang en \
--target_lang zh \
--batch_size 200 \
--max_delta_length 20
sacrebleu reference.txt -i pretrained_nemo_out_zh.txt -m bleu -b -w 4
- input_en.txt 记录了英文文本。
- pretrained_nemo_out_zh.txt 记录了模型输出的中文翻译。
- reference.txt 为参考译文。
下期预告
在第二部分中我们将指导您完成数据定制的过程并使用 LoRA 微调模型,感兴趣的小伙伴,欢迎关注我。
*本文转载自 NVIDIA
*与NVIDIA产品相关的图片或视频(完整或部分)的版权均归NVIDIA Corporation所有















 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









