







一,windows下配置Prophet
1,创建python3.7的环境
1)首先在所在系统中安装Anaconda。可以打开命令行输入conda -V检验是否安装以及当前conda的版本。
2)conda list 查看安装了哪些包
3)创建Python虚拟环境。
使用 conda create -n your_env_name python=X.X(2.7、3.6等) anaconda 命令创建python版本为X.X、名字为your_env_name的虚拟环境。your_env_name文件可以在Anaconda安装目录envs文件下找到。

4) conda create -n Prophet python=3.7
验证是否安装正确,参照下图即可
检查python的版本
python --version
5)需要移除创建的环境的方法
- 移除环境
使用命令conda remove -n your_env_name(虚拟环境名称) --all, 即可删除。
- 删除环境中的某个包。
使用命令conda remove --name $your_env_name $package_name 即可。
6)设置国内镜像
如果需要安装很多packages,你会发现conda下载的速度经常很慢,因为Anaconda.org的服务器在国外。所幸的是,清华TUNA镜像源有Anaconda仓库的镜像,我们将其加入conda的配置即可:
| 1 2 3 4 5 6 |
|
2, Prophet(时间序列模型)的配置
pip install pystan==2.19.1.1
conda install -c conda-forge fbprophet

等更新完conda后,再输入:
conda install -c conda-forge fbprophet
运行出现错误,执行下面一句

参考博文:
Windows平台下安装prophet_iwtbs_kevin的博客-CSDN博客_prophet安装
Python机器学习008:安装prophet走过的坑_布衣书生-Python的博客-CSDN博客
安装是否成功测试
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
import matplotlib.pyplot as plt
from fbprophet import Prophet
from fbprophet.diagnostics import cross_validation
from fbprophet.plot import plot_cross_validation_metric
from fbprophet.diagnostics import performance_metrics导入以上的头文件不报错误,表示安装成功
二,linux下安装Prophet的环境
1,不同版本的annconda 的下载网址
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
2,安装annconda
linux下非root用户安装Anaconda_liangliang0927的博客-CSDN博客_非root用户安装anaconda
3,配置环境
conda config --add channels - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --set show_channel_urls yes
conda install pystan
安装后进行测试
import pystan
model_code = ‘parameters {real y;} model {y ~ normal(0,1);}’
model = pystan.StanModel(model_code=model_code)
y = model.sampling().extract()[‘y’]
y.mean()
输出结果接近0则为正确
安装fbprophet
pip install fbprophet
安装后进行测试
from fbprophet import Prophet
会提示出错误,缺少安装包plotly
使用命令进行安装
pip install plotply
然后再进行测试

三,windows和linux环境下的服务器链接的方法
使用Pycharm2021专业版远程连接服务器_anyanyanyway的博客-CSDN博客_pycharm2021远程连接服务器跑代码
四,时间序列预测模型测试笔记
1,Prophet 适用条件
并非所有的预测问题都可以通过同一种程序(procedure)解决。Prophet 是为我们在 Facebook 所遇到的业务预测任务而优化的,这些任务通常具有以下特点:
1)有至少几个月(最好是一年)的每小时、每天或每周观察的历史数据;
2)有多种人类规模级别的较强的季节性趋势:每周的一些天和每年的一些时间;
3)有事先知道的以不定期的间隔发生的重要节假日(比如国庆节)。
4)缺失的历史数据或较大的异常数据的数量在合理范围内;
5)有历史趋势的变化;
6)对于数据中蕴含的非线性增长的趋势都有一个自然极限或饱和状态。
1,简单用例说明
1)首先使用一些原始数据,调用prophet方法的fit方法进行模型的拟合
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
df = pd.read_csv('example_wp_log_peyton_manning.csv')
new_df = df[0:2896]
print(new_df)
m = Prophet()
m.fit(new_df)执行后的结果为:

2)在一个数据框上进行预测,该数据框可以延展到指定的天数,默认情况下,它还将包括历史记录中的日期,因此我们也会看到模型是否合适。
future = m.make_future_dataframe(periods=10)
future.tail()3) 预言,这里产生一个新的数据框,包括一个带有预测的列,以及用于组件和不确定性区间的列,这里加入了计时操作,由于要考虑到时间的问题
import time
starttime = time.time()
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
endtime = time.time()
dtime = endtime - starttime
print("程序运行时间:%.8s s" % dtime) #显示到微秒
print(forecast)4)显示方法
如果想查看预测的成分分析,可以使用 Prophet.plot_components 方法。默认情况下,将展示趋势、时间序列的年度季节性和周季节性。如果之前包含了节假日,也会展示出来。
#数据的显示,您的预测数据框来绘制预测
fig1 = m.plot(forecast)
#只查看预测组件将看到时间序列的趋势
# 年度季节性和每周季节性。如果你包括假期,你也会在这里看到。
fig2 = m.plot_components(forecast)
fig2.show()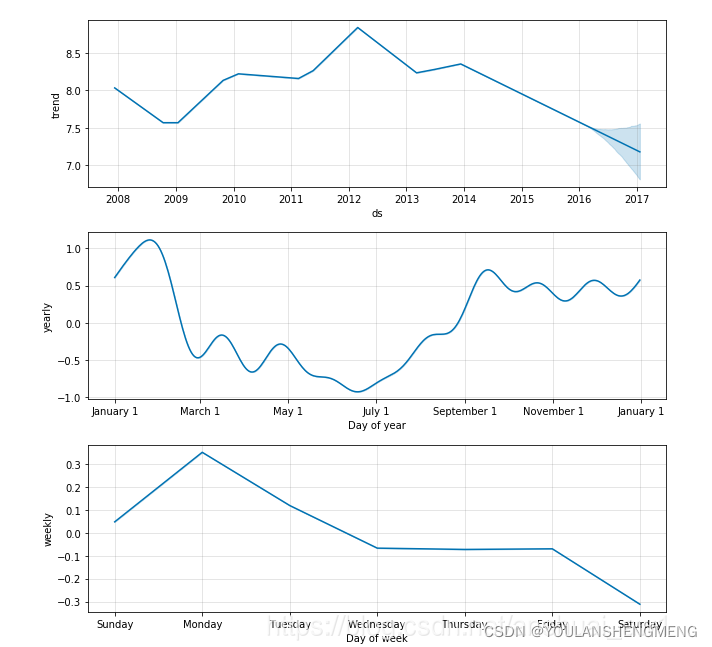
注: 一个很核心的问题是我们应该怎么样理解上图的3个子图。通过对forecast这个Dataframe分析我们就可以得到结论。
print(forecast.columns)
# Index(['ds', 'trend', 'yhat_lower', 'yhat_upper', 'trend_lower', 'trend_upper',
# 'additive_terms', 'additive_terms_lower', 'additive_terms_upper',
# 'weekly', 'weekly_lower', 'weekly_upper', 'yearly', 'yearly_lower',
# 'yearly_upper', 'multiplicative_terms', 'multiplicative_terms_lower',
# 'multiplicative_terms_upper', 'yhat'],
# dtype='object')通过对数据的分析,我们就可以知道:
①图1是根据trend画出来的,图2是根据weekly画出来的,图3是根据yearly画出来的。
②因为是加法模型,
有:forecast['additive_terms'] = forecast['weekly'] + forecast['yearly'];
有:forecast['yhat'] = forecast['trend'] + forecast['additive_terms'] 。
因此:forecast['yhat'] = forecast['trend'] +forecast['weekly'] + forecast['yearly']。
如果有节假日因素,那么就会有forecast['yhat'] = forecast['trend'] +forecast['weekly'] + forecast['yearly'] + forecast['holidays']。
节假日因素,对于那些是节假日的天数,forecast['holidays']才会有值,不是节假日的天数,forecast['holidays']为0。
③因为是加法模型,'multiplicative_terms', 'multiplicative_terms_lower', 'multiplicative_terms_upper'这3列为空。
因此,基于上面的分析,weekly中的Monday为0.3的意思就是,在trend的基础上,加0.3;Saturday为-0.3的意思就是,在trend的基础上,减0.3。因此,这条线的高低也在一定程度上反应了“销量的趋势“。
注:许多方法的细节可以通过help(Prophet) 或者 help(Prophet.fit) 来获得。
最终的代码为:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
#数据的读入,输入的数据的时间是从2007年12月10号到2016年1月20日
#一共是2905天
df = pd.read_csv('example_wp_log_peyton_manning.csv')
# new_df = df[0:2896]
print(df)
#使用原始的进行拟合,通过对一个 Prophet 对象进行实例化来拟合模型
#调用拟合模型进行拟合
m = Prophet()
m.fit(df)
#在一个数据框上进行预测,该数据框可以延展到指定的天数,默认情况下,它还将包括历史记录中的日期,因此我们也会看到模型是否合适。
#这仅仅是一个数据框,比如要求10天
#通过使用辅助的方法 Prophet.make_future_dataframe 来将未来的日期扩展指定的天数,得到一个合规的数据框。
#这里假定预测数据集365天,所以结果打印出来是ds的结束是2017,01,19
#一共是3275天,即将未来的日期扩展指定的天数
#这样做会自动包含历史数据的日期,因此我们也可以用来查看模型对于历史数据的拟合效果。
future = m.make_future_dataframe(periods=365)
future.tail()
print(future)
#预言,这里产生一个新的数据框,包括一个带有预测的列,以及用于组件和不确定性区间的列
starttime = time.time()
#predict 方法将会对每一行未来 future 日期得到一个预测值
#预测 forecast 创建的对象应当是一个新的数据框,其中包含一列预测值 yhat ,以及成分的分析和置信区间。
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
endtime = time.time()
dtime = endtime - starttime
print("程序运行时间:%.8s s" % dtime) #显示到微秒
print(forecast)
#如果想详细看forecast都有哪些列,可以执行下列的语句
print(forecast.columns)
# Index(['ds', 'trend', 'yhat_lower', 'yhat_upper', 'trend_lower', 'trend_upper',
# 'additive_terms', 'additive_terms_lower', 'additive_terms_upper',
# 'weekly', 'weekly_lower', 'weekly_upper', 'yearly', 'yearly_lower',
# 'yearly_upper', 'multiplicative_terms', 'multiplicative_terms_lower',
# 'multiplicative_terms_upper', 'yhat'],
# dtype='object')
#数据的显示,您的预测数据框来绘制预测,这里的这种显示,会将
fig1 = m.plot(forecast)
fig1.show()
#只查看预测组件将看到时间序列的趋势
# 年度季节性和每周季节性。如果你包括假期,你也会在这里看到。
fig2 = m.plot_components(forecast)
fig2.show()
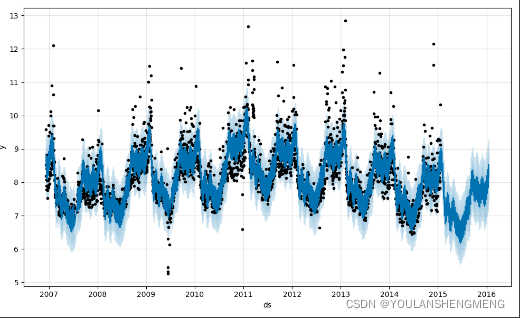
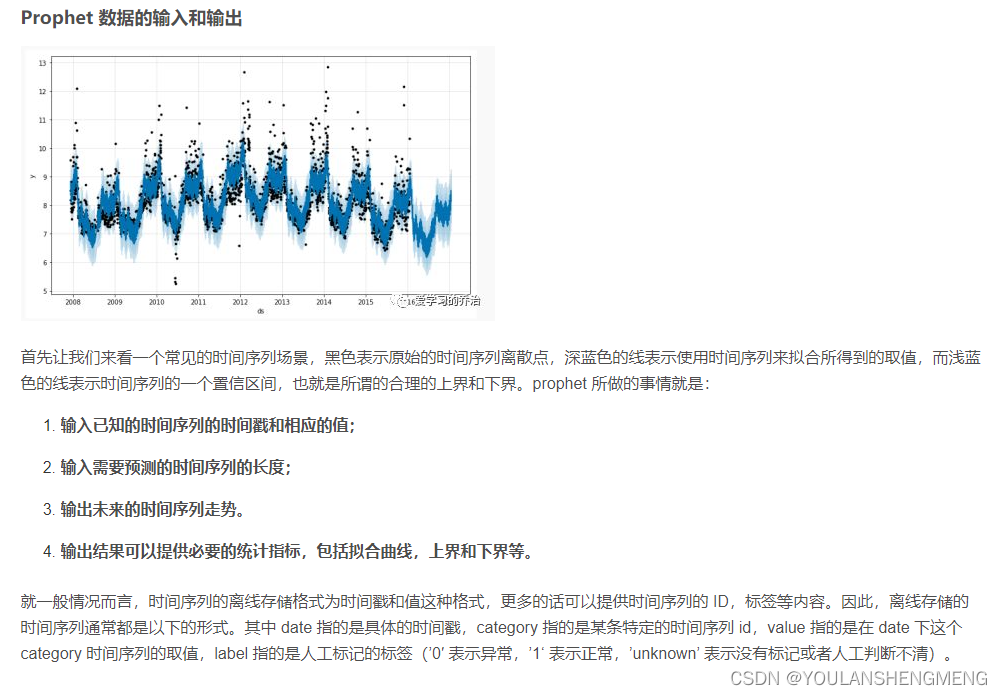
2,prophet方法的其他用处
1,饱和预测(可以预测到什么时候到达饱和值,上限是由专家设定的)
默认情况下, Prophet 使用线性模型进行预测。当预测增长情况时,通常会存在可到达的最大极限值,例如:总市场规模、总人口数等等。这被称做承载能力(carrying capacity),那么预测时就应当在接近该值时趋于饱和。
Prophet 可使用 logistic 增长 趋势模型进行预测,同时指定承载能力。下面使用 R 语言的维基百科主页 访问量(取对数)的实例来进行说明。
import pandas as pd
from fbprophet import Prophet
#读入经过LOG处理后的数据
df = pd.read_csv('example_wp_log_R.csv')
print(df)
#新建一列 cap 来指定承载能力的大小。
# 本实例中假设取某个特定的值,通常情况下这个值应当通过市场规模的数据或专业知识来决定。
df['cap'] = 8.5
print(df)
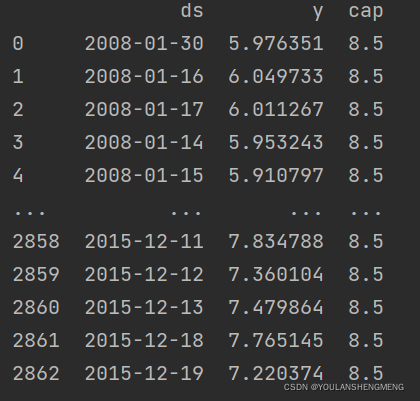
值得注意的是数据框的每行都必须指定 cap 的值,但并非需要是恒定值。如果市场规模在不断地增长,那么 cap 也可以是不断增长的序列。
通过一个新增的参数来指定采用 logistic 增长:
m = Prophet(growth='logistic')
m.fit(df)可以创建一个数据框来预测未来值,不过这里要指定未来的承载能力。我们将未来的承载能力设定得和历史数据一样,并且预测未来 3 年的数据。
future = m.make_future_dataframe(periods=1826)
future['cap'] = 8.5
fcst = m.predict(future)总的代码为:
import pandas as pd
from fbprophet import Prophet
#读入经过LOG处理后的数据
df = pd.read_csv('example_wp_log_R.csv')
print(df)
#新建一列 cap 来指定承载能力的大小。
# 本实例中假设取某个特定的值,通常情况下这个值应当通过市场规模的数据或专业知识来决定。
df['cap'] = 8.5
print(df)
#指定预测模型的方法
#通过一个新增的参数来指定采用 logistic 增长,第一个例子是默认的拟合方法m = Prophet()
m = Prophet(growth='logistic')
m.fit(df)
#我们可以创建一个数据框来预测未来值,不过这里要指定未来的承载能力。
# 我们将未来的承载能力设定得和历史数据一样,并且预测未来 3 年的数据。
future = m.make_future_dataframe(periods=1826)
future['cap'] = 8.5
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
2,预测饱和减少(可以预测什么时候达到结束)
logistic增长模型还可以处理饱和最小值,方法与指定最大值的列的方式相同:
#读入经过LOG处理后的数据
df = pd.read_csv('example_wp_log_R.csv')
print(df)
#新建一列 cap 来指定承载能力的大小。
# 本实例中假设取某个特定的值,通常情况下这个值应当通过市场规模的数据或专业知识来决定。
# 给数据增加一些维度
df['y'] = 10 - df['y']
df['cap'] = 6
df['floor'] = 1.5
print(df)
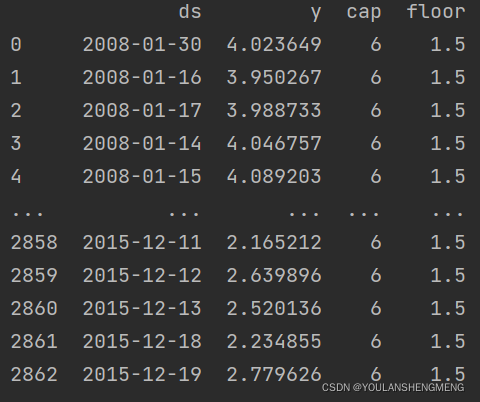
预测的流程和上面的流程是一致的,总的代码如下:
import pandas as pd
from fbprophet import Prophet
#读入经过LOG处理后的数据
df = pd.read_csv('example_wp_log_R.csv')
print(df)
#新建一列 cap 来指定承载能力的大小。
# 本实例中假设取某个特定的值,通常情况下这个值应当通过市场规模的数据或专业知识来决定。
# 给数据增加一些维度
df['y'] = 10 - df['y']
df['cap'] = 6
df['floor'] = 1.5
print(df)
#指定预测的方法
m = Prophet(growth='logistic')
m.fit(df)
#创建预测的数据框,同时指出要预测的时间段长度,同时将要预测的内容和数据设定对齐
#设定预测还是三年以后
future = m.make_future_dataframe(periods=1826)
future['cap'] = 6
future['floor'] = 1.5
#预测并且显示
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
3,fbprophet优点
(1)大规模、细粒度数据
能进行大范围预测,并且给出置信区间;数据时间粒度可以很小,支持小时、天、月数据。
(2)自动处理缺失值数据
遇到有缺失的数据时其它预测方法需要先进行插值填补预处理,而fbprophet可以自己处理缺失值数据。
(3)更灵活,支持季节、节假日调节
有些突变点往往是由特别的节假日期引起的,fbprophet支持输入这些日期以及前后影响的时间窗口,预测的时候自动适这些日期。
(4)趋势预测+趋势分解
拟合的有两种趋势:线性趋势、logistic趋势;趋势分解有很多种:Trend、年、周、天趋势、以及节假日效应。
(5)模型参数易解释
模型参数很好理解,可以让分析师根据业务经验调节参数来增强某部分假设提高准确率,使模型与业务达到理想的融合。
(6)拟合速度快
(7)操作简单
不仅环境搭建简单,而且只要十几行代码即可完成整个预测过程。

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









