






- 微软研究院
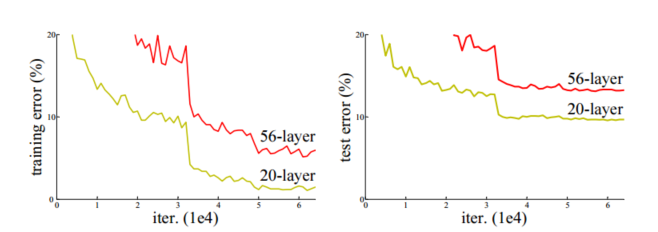
- 关注“退化”问题:之前的认知一直是认为网络层数越高效果越好,但通过实验发现ResNet随着网络层不断的加深,模型的准确率先是不断的提高,达到最大值(准确率饱和),然后随着网络深度的继续增加,模型准确率毫无征兆的出现大幅度的降低。
- 主要工作:提出一个深度残差学习框架,引入恒等映射,通过计算残差来缓解层数过高产生的退化问题
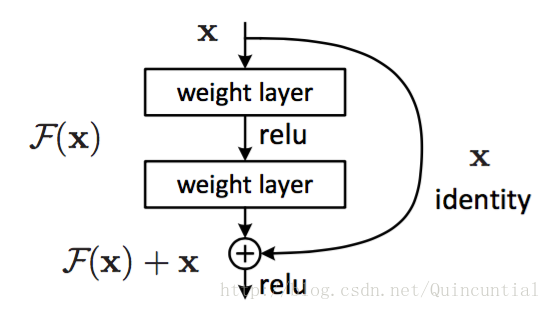
- 残差学习(Residual Learning)
- H(x) = F(x) + x(x为输入,H(x)为输出,F为残差函数F(x)=H(x)-x)
- 将使用非线性层去逼近H(x),改为去逼近H(x)-x,会使得更容易学习
- 为什么残差更容易学习?效果更好?
- 直观上看残差更小,更易学习
- 理论来讲,残差结构其实是多个更浅的网络的集成,所以它的有效深度没有看起来表面的那么深,因此优化也没有那么难。为什么残差连接的网络结构更容易学习? - 知乎 (zhihu.com)
- 神经网络无非是一个复杂的函数映射关系
- 吴恩达:
- 一个网络结构越深,那么它在训练集上训练网络的效率会有所减弱,残差块使用了一个快捷连接,将a[l]值直接传递到更深的网络,所以残差块学习恒等式函数更简单,也就意味着即使增加了了中间几层,效率并不比更简单的神经网络低。由此解决了“网络的深度使其学习效率降低的问题”。
- 为什么残差更容易学习?效果更好?
- 退化问题表明了:使用非线性层去近似恒等映射可能是有困难的,但是如果使用残差学习,求解器就可以通过简单的将多个非线性层连接的权重推向0来拟合恒等映射
- 为什么要想办法近似恒等映射?
- 相当于如果是恒等映射,增加层数则网络效率不会改变,但此时增加层数也没有任何优化。如果使用残差结果直接将恒等映射结构送入更深的网络(前面的网络已经实现达到该效果需要的98%工作),中间增加的层数只要求其尽量优化(优化2%)。
- 有点像泰勒展开
- 为什么要想办法近似恒等映射?
- 快捷恒等映射(identity function by shortcut)
- 恒等映射(identity function):F(x)=x
- 快捷连接(shortcut connection):跳过一个层或者多个层的连接
- 每隔几个层,resnet会使用残差学习,像y = F(x,Wi)+x这样构建块
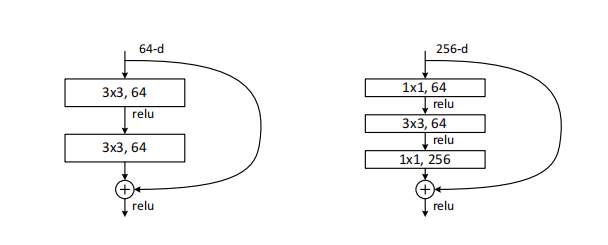
- 不同层数的resnet采用不同残差映射,resnet-18和34用的是左,resnet50以上用的右边。理论上讲,相同输入右边结构需要的参数比左边少得多,减少运算
- 虚线残差结构
- 论文中只说了会通过一个1*1的卷积来实现降维,实际上应该是这样,在conv2,conv3,conv4的第一层都需要使用虚线结构,因为这几层有调整输入矩阵channel的任务
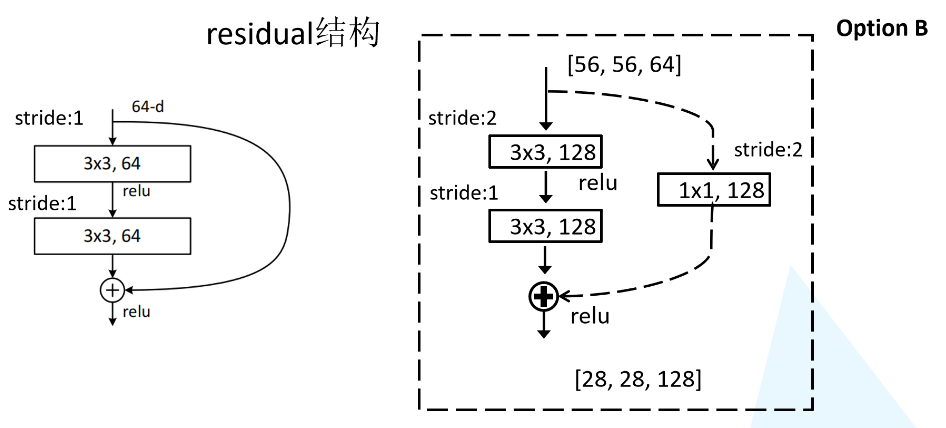
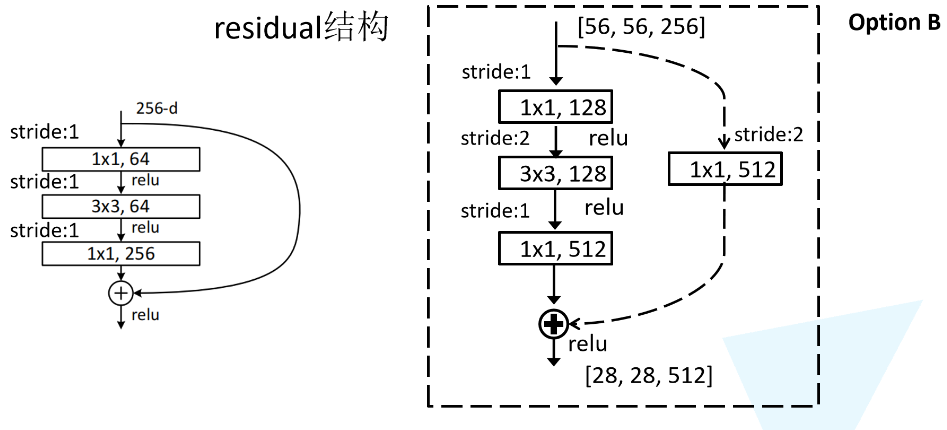
- 论文中只说了会通过一个1*1的卷积来实现降维,实际上应该是这样,在conv2,conv3,conv4的第一层都需要使用虚线结构,因为这几层有调整输入矩阵channel的任务
- 网络结构
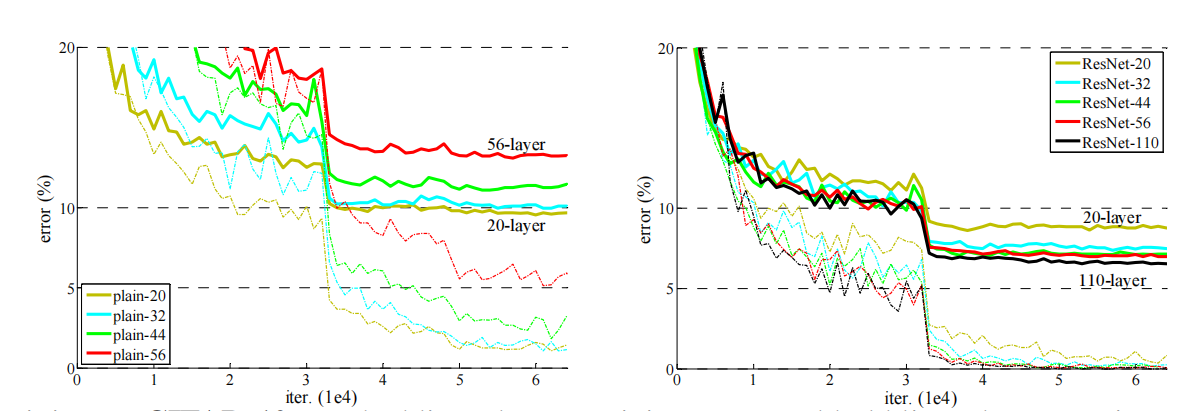
- plain network和residual network对比
- 比如34-layer residual network:在conv2,conv3,conv4的第一层都使用一个1*1的卷积来实现降维

- 实验结果















07-10
 1073
1073
1073
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









