







文章目录
Deep Residual Learning for Image Recognition
图像识别中的深度残差学习网络
作者:Kaiming He, Xiangyu Zhang ,Shaoqing Ren, Jian Sun
单位:MSRA
发表会议及时间:CVPR 2016
一 论文研究背景、成果及意义
这篇论文跟Highway Network提出的思想大差不差
首个成功训练成百上千层(100层及900层)的卷积神经网络
他的思路是借鉴了LSTM,引入门控单元,将传统前向传播增加一条计算路径变成如下图(3)的公式,增加了额外训练参数W_T

研究意义:
- 简洁高效的ResNet受到工业界宠爱,自提出以来已经成为工业界最受欢迎的卷积神经网络结构
- 近代卷积神经网络发展史的又一里程碑,突破千层网络,跳层连接成为标配
二 摘要核心
首先提出了深度卷积网络难训练
本文方法:残差学习框架可以让深层网络更容易训练
本文优点:ResNet易优化,并随着层数增加精度也提升
本文成果:ResNet比VGG深8倍,但是计算复杂度更低,在ILSVRC-2015获得3.57%的top-error
本文其他工作:CIFAR-10上训练1000层的ResNet
本文其他成果:在coco目标检测任务中提升28%的精度,并基于ResNet夺得ILSVRC的检测、定位,COCO的检测和分割四大任务的冠军
2.1 CIFAR-10上对比浅层网络和深层网络的精度
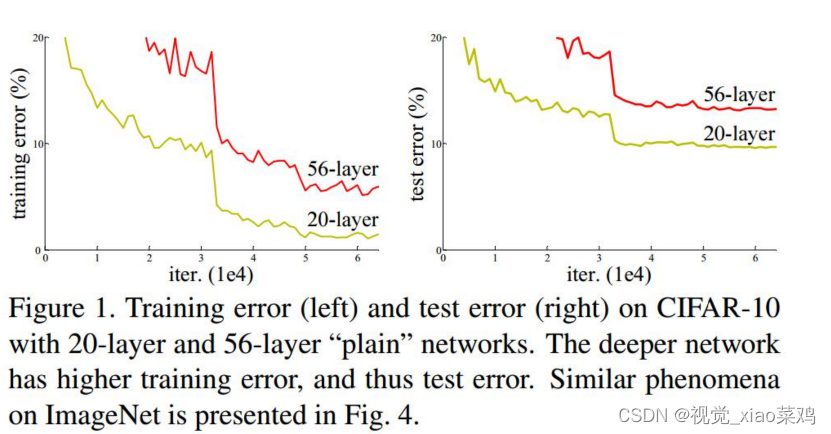
可以看出随着层数的增加,错误率不但没有下降,反而还更高了
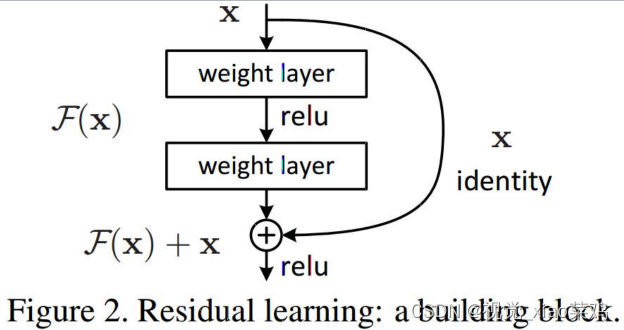
2.2 残差学习模块
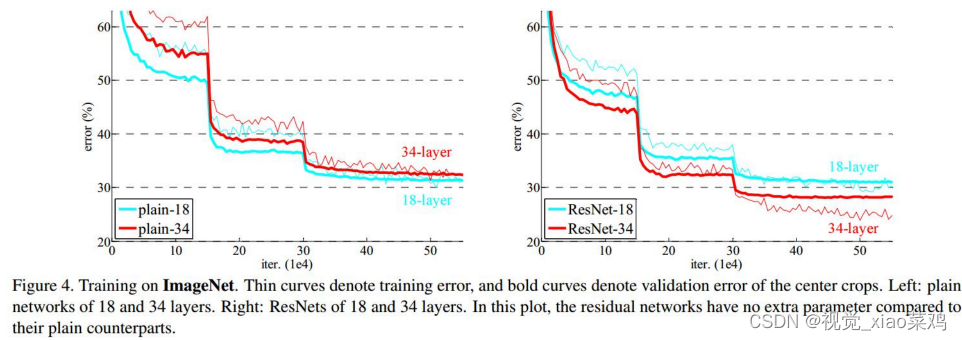
2.3 plain NetWork与ResNet的对比,ResNet完美解决plain存在的问题,即深层网络性能比浅层网络差
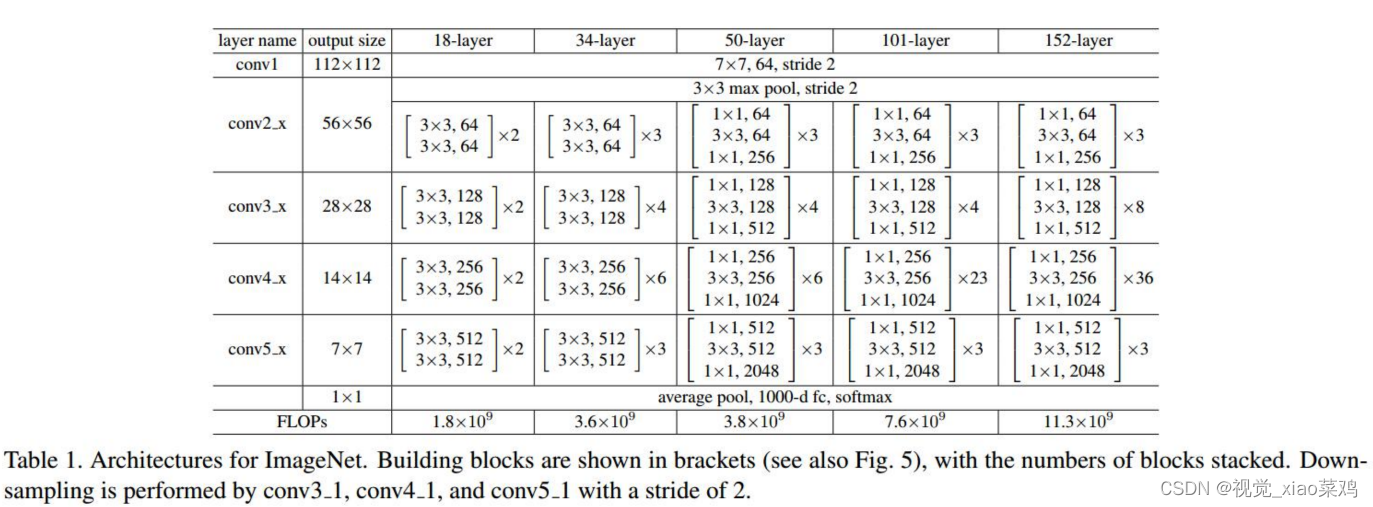
2.4 ResNet-18/34/50/101/152网络结构示意
三 论文重点解读
3.1 残差结构
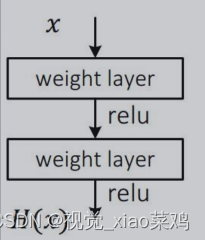
Residual learning:让网络拟合H(x)-x,而非H(x)
注:整个building block仍旧拟合H(x),注意区分building block与网络层的差异,两者不一定等价
Plain:Block_out = H(x)
H(x) Residual learning:Block_out = H(x) = F(x)+ x
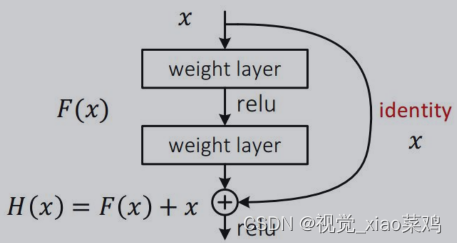
问:为什么拟合F(x)?
答:提供building block更容易学到恒等映射(identity mapping)的可能
问:为什么要恒等映射?
答:让深层网络不至于比浅层网络差
网络退化问题:
越深的网络拟合能力越强,因此越深的网络训练误差应该越低,但是实际相反
原因:并非过拟合,而是网络优化困难
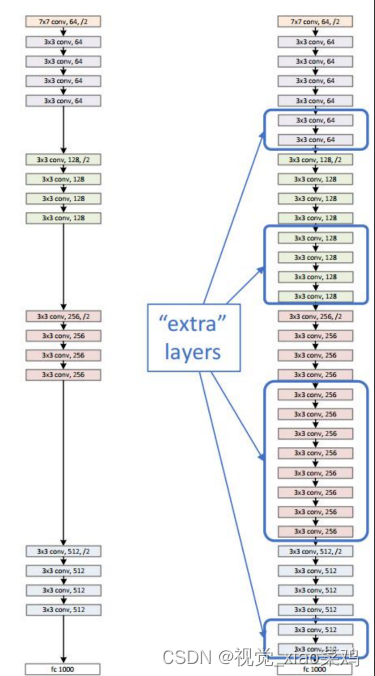
可以看下面图例:
左图是18层网络,右图是34层网络,蓝色框可以认为是额外增加层
若蓝色框里的网络层能够学习到很等映射,34层网络至少能与18层网络有相同性能
3.2 Shortcht mapping
Identitiy与F(x)结合形式探讨:
- A 全零填充:维度增加的部分采用0来填充
- B 网络层映射:当维度发生变化时,通过网络层映射(例如1*1卷积)特征图至相同维度
- C 所有Shortcut均通过网络层映射(1*1卷积)
Shortcut mapping 有利于梯度传播

3.3 ResNet结构
划分为6个stage
conv1 迅速降低分辨率 但是维度增加
4阶段残差堆叠
池化+Fc层输出
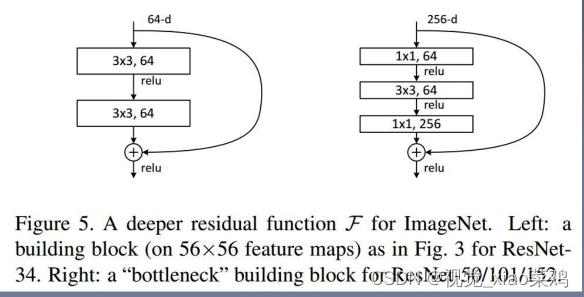
Basic:两个33卷积堆叠
Bottleneck:利用11卷积减少计算量
Bottleneck: 第一个11下降1/4通道数 第二个11提升4倍通道数
3.4 预热训练(训练亮点)
避免一开始较大的学习率导致模型的不稳定,因而一开始训练时用较小的学习率训练一个epochs,然后恢复正常学习率
四 实验结果分析
验证residual learning可解决网络退化问题,可训练更深网络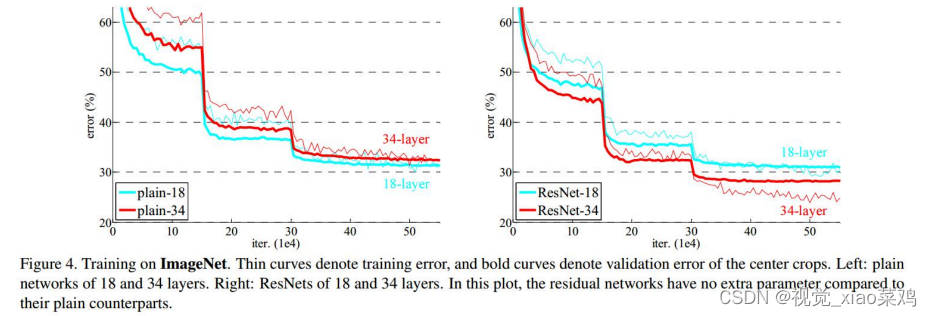
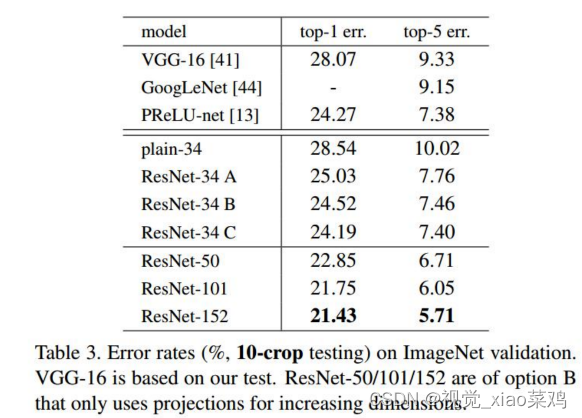
横纵对比,shortcut策略(ABC)及层数 就是上一小节提出来ABC三种填充方式
五 论文总结
关键点&创新点 • 引入shortcut connection,让网络信息有效传播,梯度反传顺畅,使得数千层卷积神经网络都可以收敛 注:本文中:shortcut connection == skip connection == identity mapping
启发点 :
- 大部分的梯度消失与爆炸问题,可通过良好初始化或者中间层的标准化来解决。 An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers (1 Introduction p2)
- shortcut connection有很多种方式,本文主要用的是恒等映射,即什么也不操作的往后传播 In our case, the shortcut connections simply perform identity mapping. (1 Introduction p6)
- highway network的shortcut connection依赖参数控制,resnet不需要 These gates are data-dependent and have parameters, in contrast to our identity shortcuts that are parameter-free.(2 Related Work p4)
- 恒等映射形式的shortcut connection是从网络退化问题中思考而来 This reformulation ( H(x ) = F(x) + x )is motivated by the counterintuitive phenomena about the degradation problem.(3.1 Residual learning)
- 借鉴VGG,本文模型设计原则:1.处理相同大小特征图,卷积核数量一样;2.特征图分辨率降低时,通道数翻倍 two simple design rules: (i) for the same output feature map size, the layers have the same number of filters; and (ii) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer. (3.3 Network Architectures p2)
- 当特征图分辨率变化时,shortcut connection同样采用stride=2进行处理 For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2. (3.3 Network Architectures p4)
- bottleneck 中两个1*1卷积分别用于减少通道数和增加/保存通道数 The three layers are 1×1, 3×3, and 1×1 convolutions, where the 1×1 layers are responsible for reducing and then increasing (restoring). (4.1 Imagenet Classification Deeper Bottleneck Architectures )
- 模型集成采用6种不同深度的ResNet结构,可以借鉴其思路
- cifar-10数据集上的ResNet-110, 第一个epochs采用较小学习率,来加速模型收敛
- cifar-10数据集上,ResNet-1202比110要差,原因可能是过拟合,而不是网络退化


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









