







本篇介绍现有主要算子含义和使用注意是想
懂的都懂,下文算子基本按照源码顺序罗列.如果有其他关于tsfresh的问题,欢迎留言讨论,后续可能会再写tsfresh的其他系列文章.
部分算子示例: github_jupyter_notenook
基础算子
1.sum_values(x)
2.median(x)
3.mean(x)
4.length(x)
5.standard_deviation(x) 标准差
6.variance(x) 方差
7.skewness(x) 偏度值
8.kurtosis(x) 峰度值
9.maximum(x)
10.minimum(x)
简单复合算子
一.本身无时序概念算子
1.variance_larger_than_standard_deviation(x)
方差是否大于标准差
2.ratio_beyond_r_sigma(x, r)
值>(均值+r*标准差) 的比例
3.large_standard_deviation(x, r)
std(x) > (r * (np.max(x) - np.min(x)))
4.has_duplicate、has_duplicate_max(x)、has_duplicate_min(x)
最X值是否重复
5.abs_energy(x)
方差和
6.variation_coefficient(x)
变异系数:标准差/均值,表示数据离散程度
7.
count_above_mean(x)
count_below_mean(x)
大于/小于均值的个数
8.
a.percentage_of_reoccurring_values_to_all_values(x)
重复值在原数据量中占比(0~1)
b.percentage_of_reoccurring_datapoints_to_all_datapoints
重复值在去重后总数中占比
c.sum_of_reoccurring_values(x)
sum_of_reoccurring_data_points([2, 2, 1]) = 2
重复值_value求和
d.sum_of_reoccurring_data_points(x)
重复值求和
sum_of_reoccurring_data_points([2, 2, 1]) = 4
9.quantile(x, m)
计算x的m分位数对应的值, m(0~1)
10.value_count(x, value)
计算x中value出现的次数
11.range_count(x, min, max)
值在(min, max)内的个数
12.count_above(x,t) ;count_below(x, t)
值大于/小于t的占比
二.本身有时序概念算子
1.mean_abs_change(x)
mean(距离前时序差值绝对值)
2.absolute_sum_of_changes(x)
距离前时序差值绝对值求和
3.
longest_strike_below_mean(x)
longest_strike_above_mean(x)
计算x中值大于/小于均值的最长连续序列长度
4.
last_location_of_maximum(x)
last_location_of_minimum(x)
first_location_of_maximum(x)
first_location_of_minimum(x)
第一次/最后一次最大值/最小值出现的相对位置 (0~1)
5.number_peaks(x, n)
满足以n作为峰值的峰数.
number_peaks([3, 0, 0, 4, 0, 0, 13],4)
返回结果 2
复杂复合算子
1.fft_coefficient(x, param)
译:傅里叶变换系数
基于快速傅里叶变换算法计算一维离散傅里叶序列的系数
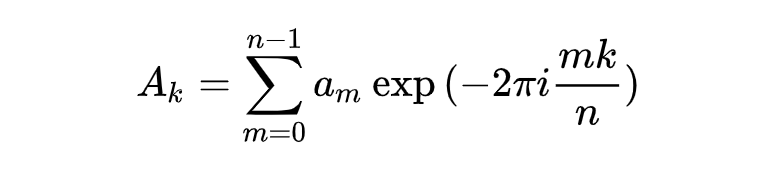
2.number_cwt_peaks(x, n)
检测指定宽度范围内的峰值数量
调用scipy.find_peaks_cwt()
3.cwt_coefficients(x, param)
Ricker小波分析
4.三个线性回归相关算子
linear_trend(x, param)
根据x的索引作为ols的X,x值作为y,进行线性拟合,返回slope、intercept等值.
agg_linear_trend(x, param)
先将数据分组,然后agg计算组内的特征值,然后进行最小二乘计算,当chunk_size=1时,就和linear_trend一致

linear_trend_timewise(x, param)
要求x的index必须是秒级别的datatime, 然后汇总到计算小时单位进行一个回归拟合.
一些使用感悟和补充
基本的算子在处理一般的时序任务即可,高级的傅立叶变化、小波分析、熵等算子更适用于精细的信号检测等场景.
本人知识水平有限,少量专业算子没有进行整理,感兴趣的看客欢迎留言讨论或者直接阅读源码即可.
















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









