






作为一个长期和各种漏洞的自动化检测 / 挖掘方案作斗争的技术崽,在编写 “扫描器” 的时候,我们将会遇到很多问题,比如
- 如何保证自己的 Payload 无害?
- 如何平衡发包和 “检测率” 之间的矛盾关系?
- 如何尽可能少的触发 WAF?
- 授权情况下(或可无视 WAF)如何尽可能的多的分析安全问题?
- 漏洞的不同表现形式有没有 “最佳实践”?
我将在这篇文中尝试对上面的问题做一些我自己的回答:
按漏洞检测行为分类:
漏洞的分类其实是一个很奇怪的话题,很多漏洞本质是一样的,包括 SQL 注入,模版注入,代码注入,XSS 甚至于命令注入,反序列化,都是把 “用户输入作为代码” 执行了。如果接受这种思考模式,那么我们可以发现这些漏洞的利用一水的简单:构造 Payload => 请求 => 检查漏洞触发的行为。
虽然我们分类漏洞可以按:“触发场景分类”,“触发语言分类”,“框架分类”,但是我们本节将要提出一个 “另类” 的漏洞分类方式,“漏洞检测行为分类”。
可能这个词听起来有点陌生,我们把漏洞检测分如下情况大家就很容易明白了
- Payload 导致漏洞有明确回显特征字符串,回显跟随字符串变化
- 比如 {{2*2}} 如果回显了 4,说明是一个 SSTI
- 如果 `expr 2 + 2` 回显了 4 说明可能是个 *unix 命令注入
- 如果 Payload 就是一个 name' 直接返回 SQL 报错,说明 SQL Error Based 是存在可能性的
- Payload 导致漏洞有回显,但是特征不明显,但是仍然可以构造布尔判断:
- 比如 {{2*2}} 的页面和 4 是相同的,但是和 {{2+3}} 输出的 5 又不相同,也可以说明 SSTI
- 如果 SQL 注入的 name=tom'and'1'='1 与 name=tom'and'2'='1 结果不相同(不相似),且前者与 name=tom 非常相似,我们认为这是一个可能的 “SQL Injection Boolean Based”
- 无本文回显,无法构造出网请求,可以构造延时请求:
- 最常见的就是 TimeBased SQL Injection,我们构造 name=tom'and/**/sleep(3) # 如果注入成功的话,将会 sleep 至少 3 秒(可以思考为什么要说 “至少”?)
- 除此之外,benchmark 通常与 sleep 齐名,但是一般情况下并不推荐用这种方案做。
- 值得注意的是,一般来说,在模版注入中如果可以执行 sleep 一般意味着已经可以执行任意代码了,可以使用更加 “精准” 的检测方式,不一定非要用 “sleep” 这种方式。毕竟模版设计的时候,从来不太想让用户 “阻塞”。
- 无文本回显,但可以构造出网请求
- DNS 出网:例如大家最熟悉的 log4j2 判断常用的 DNSLog 方式
- TCP / HTTP 出网判断:随机端口触发https://m.freebuf.com/sectool/320955.html?hmsr=joyk.com&utm_source=joyk.com&utm_medium=referral (替换成公众号文章)
- ICMP 出网:尝试命令执行 ping 192.168.1.1 来判断 ICMP 是否可以出网,从而判断命令到底执行了没有,或者能否构造 ICMP 隧道?
- 特殊补充:无文本 / 无回显 / 无出网 / 无 DNS
- 这种情况并不代表这个漏洞 “无法检测”:案例:Java 反序列化经常会用到的 “回显链” 就是一种特殊的 Payload 可以把一个不出网无回显的漏洞转变为 “有回显且特征明显”。
为什么这样分类?
这种分类手段对漏洞检测来说意义非凡,我们可以通过构造 “不同的” Payload,对参数进行漏洞检测,在进行漏洞检测的过程中,这些参数影响了应用的行为。
有了这样的抽象与分类基础,我们可以预判或枚举不同的行为对应的不同检测方法,预测一个 Payload 的触发方式和检测方式,迅速判断一个 “漏洞” 能否被规模化检测,还是只能通过 Fuzz 来检测。
Payload 是改变 “检测行为” 的核心
在读者接受上面 “按漏洞表象” 分类检测的思想之后,我们再更加深入的分析黑盒漏洞检测的问题,发现就算是同一个漏洞的触发点,不同的 Payload 的形态其实也完全不一样:
非常典型地,我们以大家很熟悉的 Java 反序列化来举例子
- 如果 ysoserial 生成反序列化流,执行 ping http://xxx.dnslog.cn 或者 curl http://xxx.dnslog.cn 就是大家常用的 DNSLog 来检测漏洞。
- 如果使用 Java 构造回显链,则是通过反序列化过程执行了 Java 代码,把执行的结果寻找并 “放” 回了原触发请求。
- 甚至于说 ping 192.168.1.1 可以通过目标 IP 是否收到对应的 ICMP 数据包来判断。
当我们明白了这个道理之后,可以再仔细思考一下 “Payload 应该如何构造以达到更好的检测效率” 的问题。
衡量漏洞检测方法的标准
类似但是不同于机器学习方法的衡量指标,如何衡量一个漏洞检测方法?
- 漏报率(越低越好):本应该检测出来,但是没有检测出来的漏洞。
- 误报率(越低越好):本应该实际上没有漏洞,但是报告了漏洞。
- 召回率(越高越好):衡量漏洞检测方法是否稳定复现检测某个漏洞,用来表示漏洞检测算法的稳定性。
- 复杂度(越低越好):构造检测所需要的条件,例如需要反连平台支持等
一般来说,上述三个指标对于我们提到的 “漏洞检测” 分类法是有不同优势的,我们以 10 分为满分检测方案:
| 漏报率评分 | 误报率评分 | 召回率评分(排除网络因素) | 复杂度评分 | 总体表现(10分) | 缺陷 | |
|---|---|---|---|---|---|---|
| 有特征回显(包括回显链) | 9(SSRF 自身机器的触发场景无法处理) | 10 | 10 | 10 | 9.75 | |
| 布尔回显 | 8 (取决于把应用响应布尔化的算法) | 8 (取决于把应用响应布尔化的算法) | 10 | 8 (算法复杂) | 8.5 | 布尔化算法是核心,例如(页面相似度比较) |
| 无回显(仅延时检测) | 8(对生产环境限制敏感) | 6(对生产环境敏感,网络波动影响大) | 8(基本稳定,计算/Sleep不够稳定) | 9 (需注意不要危害业务) | 7.75 | Sleep / benchmark 遇到 Bad SQL 会有很大的问题不同的 SQL 语句注入位置 Sleep 的时间不一样,需要特殊构造 Payload |
| 多协议出网反连 | 9(受限于目标的出网限制) | 9(Token 类似的机制可以极大程度减少误报) | 10 | 4(需要反连平台配置,对反连平台要求高) | 8 | 多种协议的 Payload 都需要尝试一下,按通用型来排布和危害来排布需要仔细考虑。 |
凭借经验,我们构造了上面一个评分表:我们发现,从漏洞检测角度来说:
- 有特征回显(回显链)是最优检测方法
- 作为备选方案:依赖算法的布尔回显与反连检测也是可以接受
- 不到万不得已,不要使用延时检测来检测漏洞
如何构造优秀的 Payload
当我们熟悉了上面提到的话题,读者应该对 “优秀的漏洞检测算法” 有了一个初步的认知,那么我们从理论拉回实践:如何构造优秀的 Payload?
猜测与突破边界
边界是很多 Payload 能触发的关键节点,能跳出边界其实很多时候是 Payload 能够执行的关键节点。
在测试过程中,我们需要扫描某些漏洞,其实要熟悉他的场景,寻找边界作为突破口,笔者列出一些场景大家可以感受一下可能有哪些边界,这些边界的闭合应该是怎么样的
例如在 SQL 中,常见的边界为
- 空格
- /**/
- 字符串单引号闭合
- 双引号(因为涉及到转义问题,双引号并不常用)
- 括号(多条件逻辑查询)
- 反引号(用于标注类明)
- 注释
- 分号(堆叠多语句)
类似的, XSS 中我们常见的字符串边界为:
- 尖括号与闭合标签
- 双引号单引号(跳出属性值)
- 换行(JS 中跳出当前语句)
- 反引号,代替括号边界执行等
- ...
除此之外,我们经常来绕过某些正则或者其他限制的标点符号或者不可见自负都是非常好的测试边界:
在 Yakit Fuzz 中,我们可以通过 {{range(00,ff)}} 直接生成所有字符,来尝试 break 边界,或者通过 {{range(00,20)}} 以及 {{range(80,ff)) 来定向不可见自负来绕过边界。或者使用 {{punc}} 生成所有标点符号来突破边界
构造有回显的特征 Payload
为了方便大家理解,我们简单总结了一下常见的几个场景:
1、非法输入报错 -> 检测错误信息:
这种情况常见于基于报错的 SQL 注入中,比如如果我们输入了一个 ' 如果页面出现了 SQL 的Syntax Error 之类的内容,我们暂时可以认为我们的输入破坏了 SQL 语句的边界
在 Yakit 中的,我们使用了一套很常见的,报错注入检测规则 SQL Injection Detection (Zero Protection)
DBMS_ERRORS = {
"MySQL": [`SQL syntax.*MySQL`, `Warning.*mysql_.*`, `valid MySQL result`, `MySqlClient\.`],
"PostgreSQL": [`PostgreSQL.*ERROR`, `Warning.*\Wpg_.*`, `valid PostgreSQL result`, `Npgsql\.`],
"Microsoft SQL Server": [`Driver.* SQL[\-\_\ ]*Server`, `OLE DB.* SQL Server`, `(\W|\A)SQL Server.*Driver`, `Warning.*mssql_.*`, `(\W|\A)SQL Server.*[0-9a-fA-F]{8}`, `(?s)Exception.*\WSystem\.Data\.SqlClient\.`, `(?s)Exception.*\WRoadhouse\.Cms\.`],
"Microsoft Access": [`Microsoft Access Driver`, `JET Database Engine`, `Access Database Engine`],
"Oracle": [`\bORA-[0-9][0-9][0-9][0-9]`, `Oracle error`, `Oracle.*Driver`, `Warning.*\Woci_.*`, `Warning.*\Wora_.*`],
"IBM DB2": [`CLI Driver.*DB2`, `DB2 SQL error`, `\bdb2_\w+\(`],
"SQLite": [`SQLite/JDBCDriver`, `SQLite.Exception`, `System.Data.SQLite.SQLiteException`, `Warning.*sqlite_.*`, `Warning.*SQLite3::`, `\[SQLITE_ERROR\]`],
"Sybase": [`(?i)Warning.*sybase.*`, `Sybase message`, `Sybase.*Server message.*`],
}2、构造数字计算 -> 检测计算结果
构造数学运算其实是非常好的解决方案,当我们找到注入点为 id=1 的时候,我们如果构造输入 id=53456-53455 的时候,两个页面相同,但是当构造 id=53456 的时候,页面又不同。我们有理由相信数字运算被执行了!
实际上,加减乘除并不是随便用在里面就好, + * / 这三个字符通常会作为某些语法的保留字符,也经常被用于分隔或者标记或者连接。反而减号用的最少,所以减法计算应该是更容易构造的用法。
实际在构造的时候,有很多种检测方法,我们可以看如下案例列表,我们列出一些常见的表达式的执行与实际情况:注意,我们仍然非常推荐使用减法运算来计算,不仅是因为 + / * 经常作为保留字符,同时 2022-01-12 这类也是很好的迷惑手段。它既可以作为数学运算,也可以很好地与日期进行混淆。
| 场景 | 计算表达式 | 备注 |
|---|---|---|
| *unix shell | expr 123 - 20 - 3 | 空格不可省略 |
| echo ${random-`expr 123 - 2 - 1`} | 利用变量赋值来构造 Linux Payload | |
| echo 123-1-1|bc | Bc 比较简单,但是这个用法需要用到管道符号。 | |
| echo $((123-23-3)) | 常规表达式计算 | |
| echo $[123-23-3] | 常规表达式计算 | |
| Windows 计算表达式 | set /a 123-20-3 | CMD 可用 |
| 表达式模版注入:Jinja2 / Tornado | {{2023-20-3}} | Jinja2 / Tornado |
| {% raw 2023-20-3 %} | Tornado 表达式计算 | |
| 兼容注入 EL 表达式 | ${2023-20-3} | EL 常用表达式 |
| JSP 表达式 | <%=123-20-3 %> | JSP 表达式 |
| PHP 表达式 | <?=123-23-1?> | |
| Java FreeMaker 表达式 | ${(123-23-1)?c} | 本质上是 FreeMaker 对 数字内建函数 中 c 的调用 |
| ${123123.456456?string["0"]} | 这是取整数的操作,结果为 123123,并且不应该包含 456456 | |
| Java Velocity 表达式 | #set($random=123-12-12)$random | 包含两步,创建变量 + 输出结果 #set 指令没有 #end 语句。 |
| EJS | <%- 123-12-1 %> | EJS 不转义 |
| <%= 123-12-1 %> | EJS 转义(HTML 编码等) |
3、字母字符串计算 -> 检测计算结果
和数字一样,我们期待的回显可以通过随机的表达式运算得到结果,同样的地方,我们也可以通过构造字母运算来获得回显。
具体的方案笔者就不再赘述了,实际上针对上面的内容,大家可以随时自行补充对应模版的字符串运算。
4、利用自身状态回显
这是一个非常典型的且有趣的的回显方法:
- Java 反序列化回显链是这种类型的回显,例如:在 Tomcat 回显链:通过ThreadLocal Response回显或者 Weblogic 的思路也基本类似。
- SSRF 自身端口打出内容也是这类回显。不过相对来说,虽然 SSRF 可以打出特定内容,但是我们并不能知道这个“特定内容”到底是什么,同时受限于 HTTP 协议,这并不是一个容易的事情。
构造布尔特征 Payload
布尔化算法
布尔特征 Payload 的精髓在于,如何把不规则的输入变为可衡量的 True / False。
我们常见有很多手段和需要注意的点去做这个事情:
- 直接对前后 HTTPResponse 的 Body 做相似度计算,设置一个阈值,常见于 0.98
- 混合了状态码的不同的 Body 类型的相似度算法不一样,例如如果前后状态码都不同,大概率也是不相同了
- 数据中通常有关联很多奇怪且无用的特征,基于页面比较的算法可以通过泛化等手段屏蔽这些问题
诚然,这件事情做起来并不简单,我们可以假定构造一个算法:把上面的因素作为整体权重:
| 相似度对比项目 | 权重 | 理由/备注 |
|---|---|---|
| 状态码 | 0.3 | 如果两个页面状态码不同,基本代表从根基上就存在比较大的问题,权重比较大时应该的 |
| URL(Schema+Path+URI) | 0.2 | URL 相同但是状态码不同,可能是确实请求内容不同导致响应出现分叉。 |
| Body | 0.4 | 根据 Content-Type 决定的对比方法不同:JSON 适合排序后对比XML 和 HTML 类的适合两种对比选项:带 *ML 标签的文本直接相似度计算对比 + 取出所有 strings 进行对比(SQLMAP 预处理) |
| Header | 0.1 | Headers 中各种项对权重应该也是应该有影响的。当然不同的 Header 的影响机制也不相同:我们可以认为:Set-Cookie 和 Content-Type 比重很高,我们暂定 0.33 与 0.33,其他头共同占 0.34同时我们也应该排除 GZIP 和 Base64 的影响 |
我们通过以上思考,初步构建了一个页面相似度的对比技术方案:当然这大概率不是最终技术方案,我们应该在这个基础上去实现算法,并且在实战中改进这个算法。
>= yak-1.0.14-sp1 的版本中,我们使用 judge.CompareRaw 可以调用这个方法,直接对两个数据包进行对比,获得一个浮点数。
我们发现,我们可以计算两个数据包(HTTP 流)的相似度,这是一个百分比或者一个浮点数,最小值为 0,最大值为 1。我们常用:
- 可以把 >=0.95 认为是 “相同”,这对应的布尔值中的 “True”。
- 可以把 >= 0.85 认为是 “相似”,在特定场景下也可以对应 “True”
- 在 >=0.7 的时候,我们认为他们是 “基本相似”,一般在宽松的场景下可以认为 “True”
- 其余情况,我们可以认为 “不相同”
如何利用布尔化算法进行判别?
案例:CVE-2022-22965 (Spring-Core-RCE JDK9+)检测的探讨:
目前检测主要有三种方法:
- 写文件 + 连接 WebShell 的 “利用” 法
- 报错法 :
- class.module.classLoader.URLs[0] 类型报错
- class.module.class.module.class.module ...* 抽象类加载报错
- class.module.classLoader.DefaultAssertionStatus 类型报错
- DNS 反连检测:class.module.classLoader.resources.context.configFile=http://*.http://dnslog.cn/test&class.module.classLoader.resources.context.configFile.content.aaa=xxx
从表面上看,第一种会对业务产生影响不太推荐使用,第三种对基础设施略有要求,我们最理想的检测方案是 “报错法” 进行检测。
为什么是报错,而不是 “特征字符串” 回显?
这是因为执行成功我们并不能看到 “特征” 是啥,也无法知道回显的位置,回显的结果特征也并不够明显,不是我们确定的计算结果,而是 “报错结果”
然而报错是可以被 Spring 框架全局拦截重定向到主页的。基于这种考虑实际上报错法的漏报还是挺多,甚至在构造不合理的时候,误报也会存在。
但是如果我们认为目标一定会返回报错结果,基于这个考虑,我们如何利用布尔化来判断漏洞是否存在?其实道理很简单,构造实验组和对照组,使用控制变量法。
- 正常的请求记录为 Positive 请求(P1)
- 为了确定稳定,正常请求应该有多个(P2/P3)
- 打出 Payload 请求设置为 A
那么如果,我们可以认为 P1 / P2 / P3 互相都相同 (相似),当发送 Payload 后对应的 A 请求与其他(P1/P2/P3)都不应该相同(相似)。我们可以因此区分出一个 “不同的 Payload”。
更具体的来说,我们以class.module.classLoader.DefaultAssertionStatus 来举例,我们需要发送三个请求:
- P1: class.module.classLoader.DefaultAssertionStatus=True
- P2: class.module.classLoader.DefaultAssertionStatus=False
- A: class.module.classLoader.DefaultAssertionStatus=123
P1 / P2 都是不应该有错误的请求,A 是应该报错的请求。那么如果有漏洞的话,应该符合我们我们实验的流程。
P1 和 P2 极其相似,A 与 P1 和 P2 都不相似。
当然,P1 / P2 如果可以还能增加另一个对照组,原请求啥也不做的 “结果”(P3)以更好区分。
案例二:设计一个布尔类型的 SQL 检测方案
当我们明白基础的布尔化检测原理之后,重新看一个经典的案例:Boolean-Based SQL Injection,我们以 id=1 为触发点来设计实验方案:
- id=1 为 P1
- id=1 and 1=1/**/ 为 P2
- id=1 and 2=1 为 Negative (N1)
那么最基础的,我们可以认为
- P1 与 P2 相同/相似
- P1 与 N1 不相同
- P2 与 N1 不相同。
经历这三个判别,可以初步进行筛选出 N1 是 “有问题的”。那么继续更深层的验证可以扩充 Positive 组,我们可以测试 id=1 and 1=2023-2020-1-1 来判断等式,这也是为了能 “更好判别” 的其他构造。
当然,我们粗筛之后,能获得 “如何突破边界” 等问题,可以把上述结果转换成更简单的办法,比如 union select 1,2,3,4,5... --%20 这类可控回显来更精准检测。
小总结
实际上,我们上面设计的 “实验方案” 并不是完全零误报零漏报的,大家在实现的时候,需要充分考虑剪枝算法的情况以及网络因素导致的 “不稳定” 的问题。
多协议出网反连检测漏洞:
目前多协议出网检测主要也分为三大协议:
- UDP 反连检测:以 DNS 协议为代表
- TCP 反连检测:RMI / LDAP / HTTP / 随机端口反连检测
- ICMP 反连:以特定长度的 ICMP 包作为依据,ping -s [len] http://example.com
这块儿其实并不复杂,甚至可以说是挺简单的构造方式了,但是大家并不用拘泥于具体的 Payload 应该是什么样子,或者具体的协议应该是啥,我们以两个比较 “稀有” 的反连触发方式来介绍这部分内容。
TCP 通杀:免特征 Token 的无监听端口随机反连
实际上对于除了 DNS 之外的大多数场景来说,绝大多数反连的 “检测” 都是以 TCP 作为基础协议的,我们可以通过对基于 TCP 协议进行实现从而实现多种应用写的复杂兼容:
- 常见的 HTTP 反连检测,我们一般使用 Path 作为 Token 的标注位置,来区分 “到底是哪个漏洞触发”:http://example.com/[token]
- 常见的 RMI 类似 jndi:rmi://http://example.com/[token]
- ...
但是实际上,上面的各种用例都是需要用户具体监听某个端口来实现的,在于 @奶权 师傅的交流中,我们实现了一种更 “通用的” 检测手段,并成功把它进行了工程化实现:
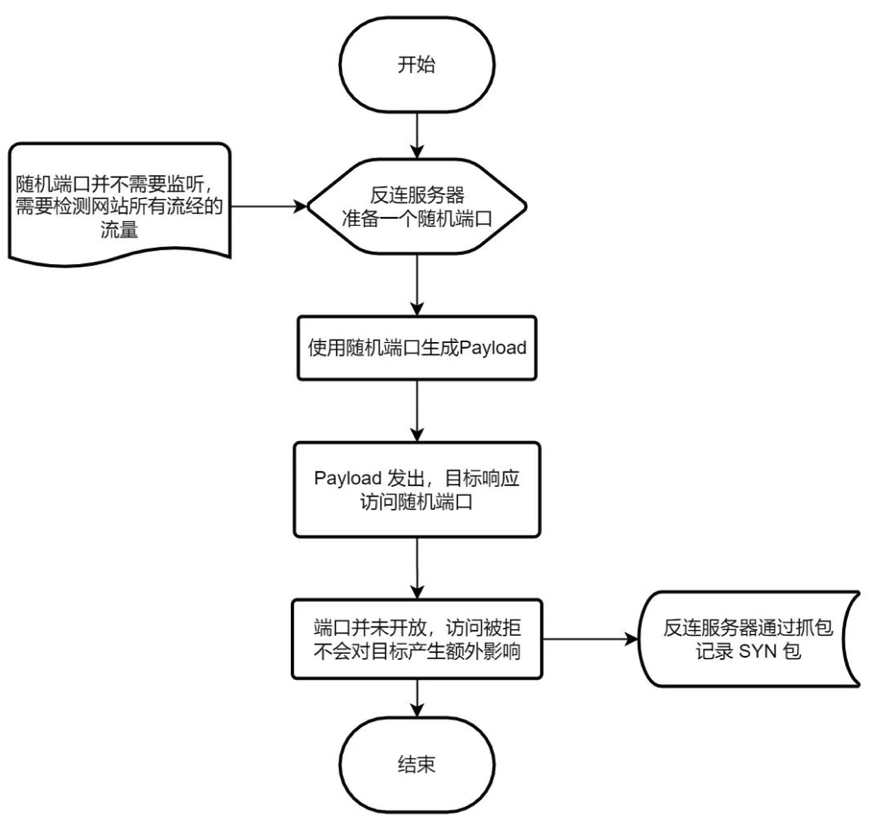
跳出五行三界:ICMP 反连以及隧道
类似的,受上面提出的方案的启发,我们抛开 TCP 不说,ICMP 协议也是可以有类似的技术方案的,只是不同的是,ICMP 不涉及端口,那么如何以类似的方式来触发 ICMP 反连然后区分这个 ICMP 连接 / 数据包,对应的是 “哪个漏洞”?
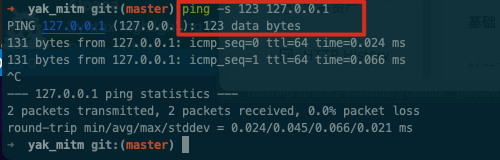
我们使用最简单的触发方式:ping命令,当我们设置 -s 参数时,我们可以实现为 ICMP 指定数据包类型,那么也就是说,我们可以预先设置一个随机值作为 ping 的数据包大小,如果 ping 过来的数据包大小刚好符合我们设置的 “随机值”,那么可以变相说明我们的反连成功了。
我们如果把上述的过程使用一个简单的图描述出来,过程其实非常容易让人理解
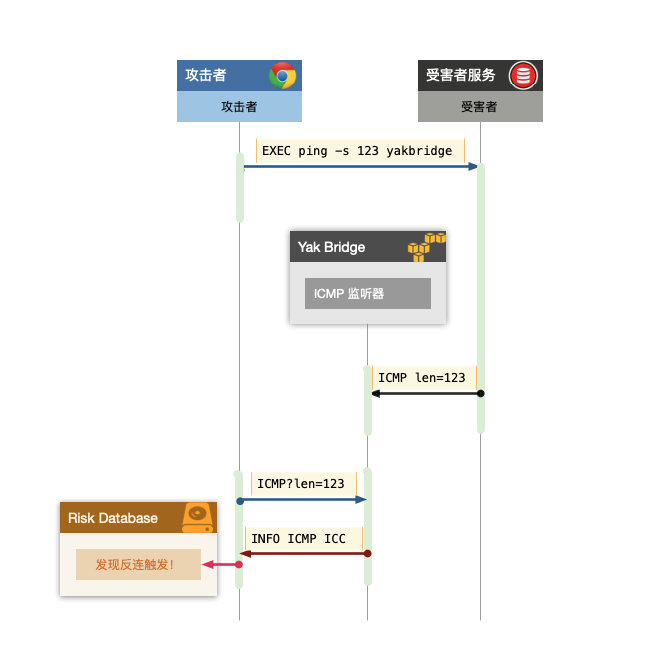
WHY?
我们为什么要做这件事?很多时候,当出网 TCP 和 UDP 都无法行得通的时候,ICMP 隧道可以用来传输一定的数据,那如何测试 ICMP 隧道是可以通道外网呢?用本文提出的这类方法是比较快速可以达成这个目标的方案了。
总结
在文中,我们略去了 “时间注入” 相关的检测,理由在 “漏洞检测行为分类” 中已经介绍了,在此就不再赘述。
本文对具体的技术方案其实并没有做过多的技术探讨,旨在抛砖引玉。感谢在实际和 Yakit 用户交流与实现过程中,大家提供的帮助,希望本文可以作为大家 “漏洞检测” 技术方案的部分理论依据。
Yak官方资源
Yak 语言官方教程:
https://yaklang.com/docs/intro/
Yakit 视频教程:
https://space.bilibili.com/437503777
Github下载地址:
https://github.com/yaklang/yakit
Yakit官网下载地址:
https://yaklang.com/
Yakit安装文档:
https://yaklang.com/products/download_and_install
Yakit使用文档:
https://yaklang.com/products/intro/
常见问题速查:
https://yaklang.com/products/FAQ















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









