







Deep Learning Face Representation by Joint Identification-Verification
这篇论文主要是针对人脸识别,分为两个任务:
- face identification task
- face verification task
前者目的是增大类间间距,即不同人的差距;后者是为了减小类内差距,即相同人在不同环境下的差异。
在网络的设计中,最终生成的DeepID2是由conv3和conv4融合得到的,反映了不同层的特征信息。其中conv4设置了权重在神经元间不共享,即不同位置的卷积核不同(locally-connected layer)。

Identification
这个任务采用的是传统的softmax n分类器,直接跟在DeepID2后面,以交叉熵为损失函数。

Verification
目的是让从同一个人提取的DeepID2特征类似,从而降低类内的差距。其约束条件可以是L1、L2范数或余弦相似度,其计算分别为:
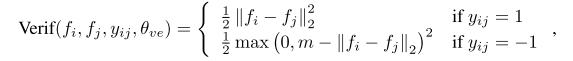
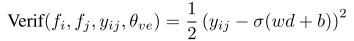
值得注意的是,公式中出现了两个图片输入(
fi
、
fj
),当为同类时,
yij=1
否则为-1,从而提供了类内与类间两种损失。
梯度更新

梯度更新有一点疑惑的是最后更新参数不应该是使用参数的梯度去相减吗?
Text-Attentional Convolutional Neural Network for Scene Text Detection
这一篇是讲文字识别(其实是找到哪里是文字)。为了解决这一个看起来简单的问题,加了两个较为复杂的辅助任务。
网络结构

看到这个输入我是有点震惊的,网络输入是32*32的图片,主要任务是输出是否为字符,辅助任务是字符分割和字符分类(感觉是辅助带大哥飞啊= =)。
整个网络解决了三个问题:where(区域回归,或是字符分割)、what(字符分类)、whether(是否为字符),其中前两个较为困难,最后的也是最主要的比较简单。
loss设计
总体的loss为:
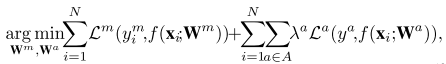
针对于每个任务,具体的loss为(这里又觉得少了后括号):
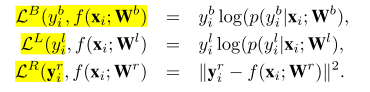
输出分别为:
- b:text、notext二分类
- l:0-9,a-z,A-Z所有字符的62分类
- r:分割区域,32*32大小,取值范围{0,1}的二进制mask
辅助任务的只在训练过程中进行,测试中停止。
Embedding Label Structures for Fine-Grained Feature Representation
这一篇主要是对triplet loss的改进,变成了四元组损失。
triplet loss
文中说,传统的softmax是
“squeeze” the data from the class into a corner of the feature space
而没有注重类内、类间的关系。
triplet loss 可以说又是第一篇论文二输入的一次改进,输入分别为:参考原始图像(
ri
),与参考图像同类别图像(
pi
),与参考图像不同类别图像(
ni
)。并且设置一个边界m,使类似图像的距离(L2范数)加上m小于不同类图像的距离。
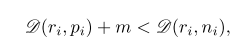
其实我觉得右边可以改成
(D(ri,ni)+D(pi,ni))/2
,这样是不是数据利用率高一些呢。
最终选择hinge loss:

缺点是如果有N张图片,那么triplet将会有
N3
量级的三元组合,训练速度很慢。
整个任务使用了softmax与triplet的组合:
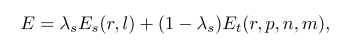
四元组

其实就是把类划得更细了,加入了细粒度的标签与特征。
p+i
与原图大类、小类都一样,而
p−i
是大类相同,小类不同(颜色、年份等)。
公式表示为:
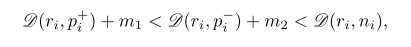
loss表示为:
















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









