







背景
最近要做一个文本到graph的数据集,里面有不少不同字但同义的小文本段,想简单用文本相似度的方式把他们归到一类里面。
方式
- 直接调用hanlp的sentence sim,帮忙解决
- 直接用hugging face的transformer的高级api,也是直接端到端帮忙解决。
- 用中文transformer做sentence embedding,后用距离函数设定阈值解决。
Hanlp
根据这里,pip install hanlp后,直接
import hanlp
sts = hanlp.load(hanlp.pretrained.sts.STS_ELECTRA_BASE_ZH)
sentence_list=make_sentence_list()
# sentence_list=[
# ('看图猜一电影名', '看图猜电影'),
# ('无线路由器怎么无线上网', '无线上网卡和无线路由器怎么用'),
# ('北京到上海的动车票', '上海到北京的动车票'),
# ]
res=sts(sentence_list)
print(res)
transformer end2end
pip install transformer后,
本来想偷懒直接用pipeline的,
from transformers import AutoModelForTokenClassification,AutoTokenizer,pipeline
model_id='uer/sbert-base-chinese-nli'
scorer=pipeline("sentence-similarity",model=model_id)
但是报错,嘻嘻:
"Unknown task sentence-similarity, available tasks are ['audio-classification', 'automatic-speech-recognition', 'conversational', 'document-question-answering', 'feature-extraction', 'fill-mask', 'image-classification', 'image-segmentation', 'image-to-text', 'ner', 'object-detection', 'question-answering', 'sentiment-analysis', 'summarization', 'table-question-answering', 'text-classification', 'text-generation', 'text2text-generation', 'token-classification', 'translation', 'visual-question-answering', 'vqa', 'zero-shot-classification', 'zero-shot-image-classification', 'translation_XX_to_YY']"
行吧,再偷懒下,看看能不能autotokenizer和automodel解决
根据我的这篇教程,找到对应任务后选择model id。
找到后,只有两个模型……好家伙,够少的。怎么连个example也没有……
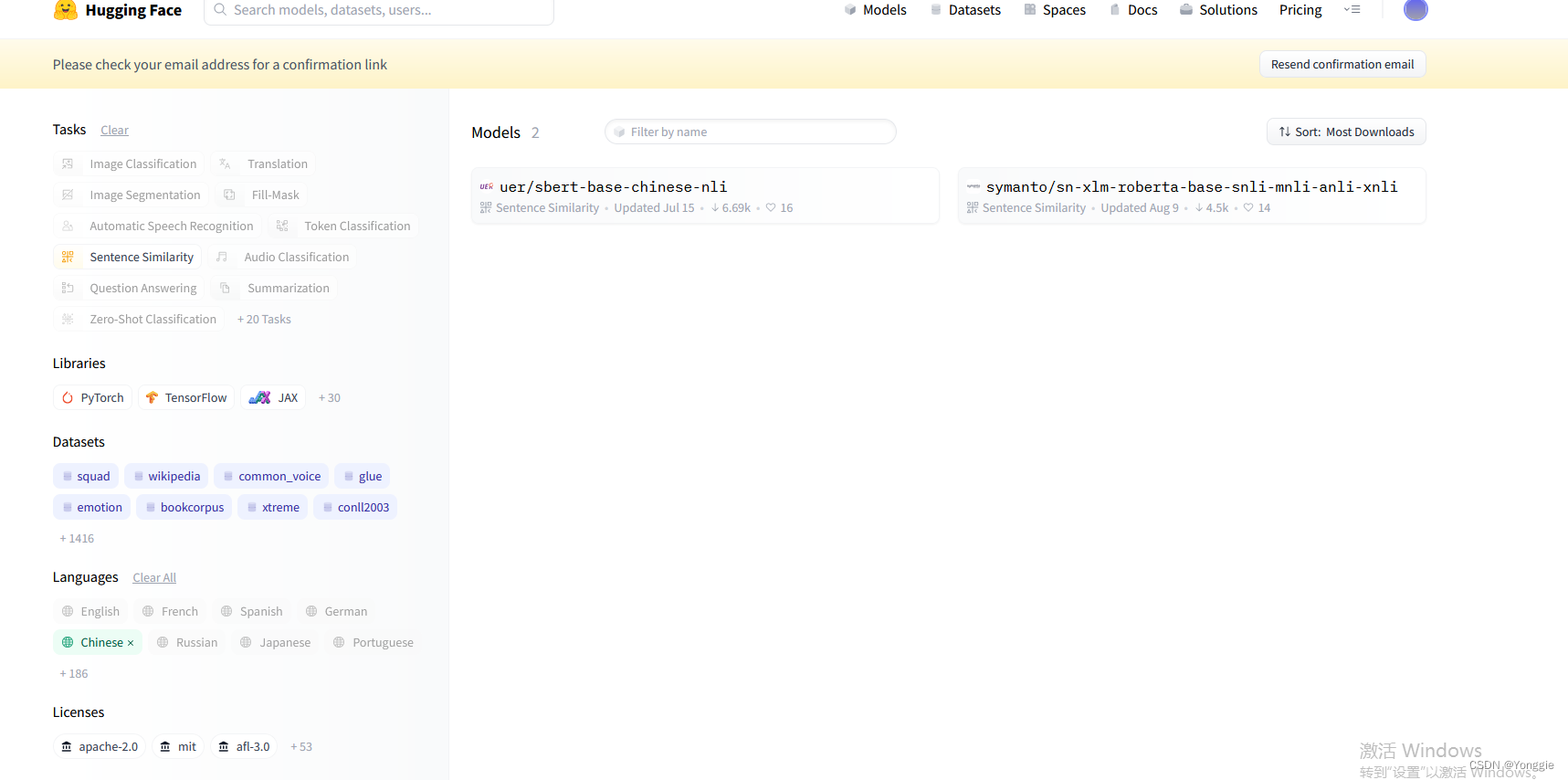
随便选择一个,然后看下其他语言的sentence similarity的example:
import torch
from scipy.spatial.distance import cosine
from transformers import AutoModel, AutoTokenizer
# Load the model
tokenizer = AutoTokenizer.from_pretrained("johngiorgi/declutr-small")
model = AutoModel.from_pretrained("johngiorgi/declutr-small")
# Prepare some text to embed
text = [
"A smiling costumed woman is holding an umbrella.",
"A happy woman in a fairy costume holds an umbrella.",
]
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# Embed the text
with torch.no_grad():
sequence_output = model(**inputs)[0]
# Mean pool the token-level embeddings to get sentence-level embeddings
embeddings = torch.sum(
sequence_output * inputs["attention_mask"].unsqueeze(-1), dim=1
) / torch.clamp(torch.sum(inputs["attention_mask"], dim=1, keepdims=True), min=1e-9)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
woc,明面上写的是end2end,结果还是只返回sentence embedding……
根本是假的端到端……
transformer sentence embedding
既然是假的端到端,那没必要选择特定task的model了。
例子上一部分已经给出来了,很棒!换个model id就行了,看看?
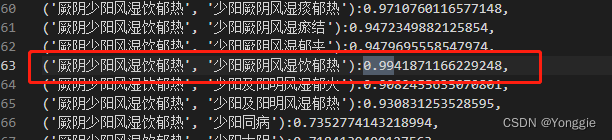
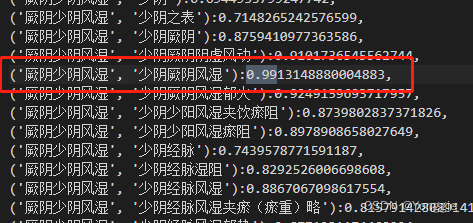

















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









