







 文章介绍了一种方法,通过提示(prompt)使语言模型生成带API标签的文本,然后用这些数据对模型进行微调,使其能执行API调用。该方法解决了无标签数据的问题,特别在数学计算方面显示了显著改进。模型经过自我学习和迭代,可实现能力的提升,类似技术可能已被应用到产品中,如Office的Copilot。
文章介绍了一种方法,通过提示(prompt)使语言模型生成带API标签的文本,然后用这些数据对模型进行微调,使其能执行API调用。该方法解决了无标签数据的问题,特别在数学计算方面显示了显著改进。模型经过自我学习和迭代,可实现能力的提升,类似技术可能已被应用到产品中,如Office的Copilot。
aim
此文章的意图在于:
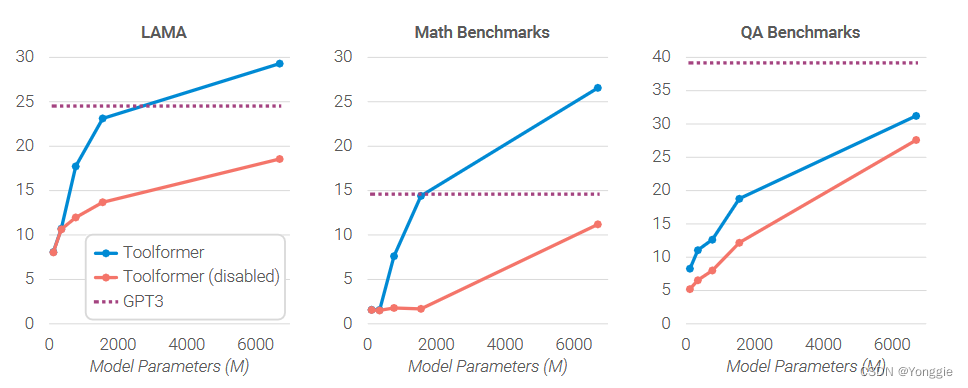
To equip a language model 𝑀 with the ability to use different tools by means of API calls.
也就是是一个类似于chatGPT一样的模型能够获得调用API的能力。
方法概括
文章所使用的方法是有监督学习。
但是我们并没有类似下方带有标签的训练数据,这要怎么做呢?

本篇文章就采用了一个方法能够自己自足。
他直接使用Prompt的方式让语言模型自己生成带有API标签的文本数据。

上图的意思是直接对大语言模型(你就把他当做chatgpt就行了)输入命令,我让大语言模型做一个API的生成器,然后用他返回的结果当做带标签的数据。
然后根据这些已有的API标签,进行API调用接口并返回结果。然后根据返回的结果的好坏去筛选,最后再根据新生成的带有API标签的数据集对大语言模型进行最后的微调,就可以生成能够使用API调用接口的大语言模型了。
简单地说,就是想论文描述的那样:
 就这么几步,就可以实现标签数据的自给自足。
就这么几步,就可以实现标签数据的自给自足。
你甚至还可以从最后一步再次跳到第一步,再次上述步骤,自己做自己的teacher,教会自己student进行“自我升级”。
更多的
文章所调用的API一共只有五个,但是他的方法可以泛化到更多的API。
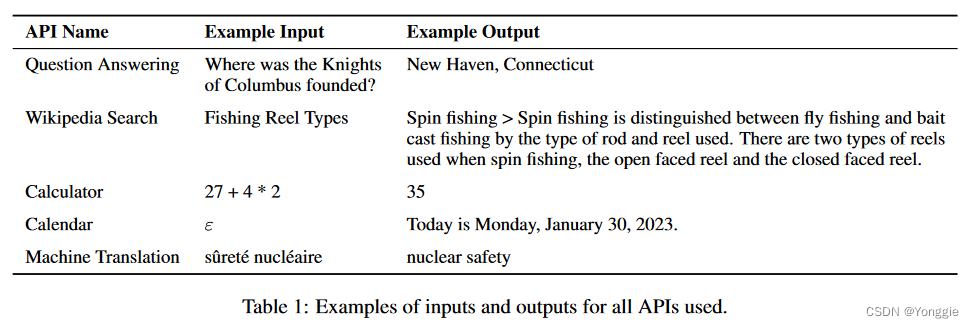 在实验结果上可以看到。本篇文章的模型对比PPT 3。有长足的进步,尤其是在数学能力方面一直被诟病的。大约模型不能够进行数学给你算。的缺点也被大幅改进了。
在实验结果上可以看到。本篇文章的模型对比PPT 3。有长足的进步,尤其是在数学能力方面一直被诟病的。大约模型不能够进行数学给你算。的缺点也被大幅改进了。
像现在很多的产品估计已经早早的使用了,这样子的技术方法,比如office的copilot(可能哈,自己猜的)。
更具体
其实更具体的还是得看论文,我这有个自制的小视频,里面也稍微讲了些
详见:https://www.bilibili.com/video/BV1vN411A7pV/

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









