







 本文介绍了SimCLRv2在半监督学习中的应用,展示大模型在少量标记样本下能带来显著的性能提升。通过无监督预训练、有监督微调和蒸馏三个步骤,使用1%和10%的ImageNet标记图像,ResNet-50分别达到73.9%和77.5%的top-1准确率,远超标准监督训练。研究发现,更大的网络在预训练和微调中对于未标记数据的利用更有效,且通过蒸馏可以将知识转移至更小的网络,保持高精度。
本文介绍了SimCLRv2在半监督学习中的应用,展示大模型在少量标记样本下能带来显著的性能提升。通过无监督预训练、有监督微调和蒸馏三个步骤,使用1%和10%的ImageNet标记图像,ResNet-50分别达到73.9%和77.5%的top-1准确率,远超标准监督训练。研究发现,更大的网络在预训练和微调中对于未标记数据的利用更有效,且通过蒸馏可以将知识转移至更小的网络,保持高精度。
从少量标记样本中学习,同时充分利用大量未标记数据的一种范式是无监督的预训练,然后是监督的微调。虽然这个范例以 task-agnostic 任务不可知 的方式使用了未标记的数据,但与计算机视觉的常见半监督学习方法相比,本文表明它对于ImageNet上的半监督学习非常有效。
本文的方法的一个关键组成是 在预训练和微调期间使用大的(深度和广度)网络。我们发现,标签越少,这种方法(使用未标签数据的任务无关性)从更大的网络中获益越多。经过微调后,通过第二次使用未标记的示例,可以进一步改进大网络,并将其浓缩为一个小得多的网络,分类精度损失很小,但以 task-specific 特定于任务的方式进行。
本文提出的半监督学习算法可以归纳为三个步骤:
1. 使用SimCLRv2对大型ResNet模型进行无监督预训练,
2. 对少数标记实例进行有监督微调,
3. 用未标记实例 提炼蒸馏 和迁移 任务特定的知识。
该程序仅用1%的标签(每类≤13个带标记的图像),使用ResNet-50实现了73.9%的ImageNet top-1精度,标签效率比以前的先进水平提高了10倍。在10%的标签下,使用我们的方法训练的ResNet-50实现了77.5%的top-1准确率,优于所有标签的标准监督训练。
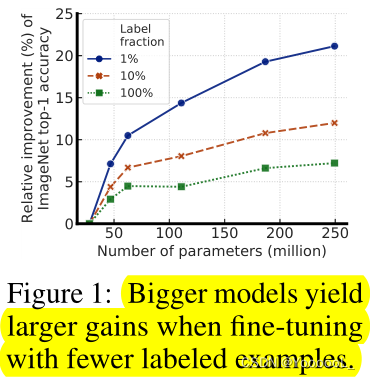
图1:当使用较少的标记示例进行微调时,更大的模型产生更大的收益。
在充分利用大量未标记数据的同时,仅从少数标记样本中学习是机器学习中长期存在的问题。半监督学习的一种方法包括无监督或自监督的预训练,然后是监督微调[3,4]。
这种方法在预训练期间以与任务无关的方式利用未标记的数据,监督标签仅在微调期间使用。虽然这种方法在计算机视觉中很少受到关注,但它已经在自然语言处理中占据主导地位,首先在未标记的文本(如维基百科)上训练一个大型语言模型,然后在少数标记样本上微调模型[5-10]。
计算机视觉中常见的另一种方法是在监督学习期间直接利用未标记的数据,作为一种正则化形式。这种方法 以特定于任务的方式使用未标记数据,以鼓励不同模之间或不同数据增强下的未标记数据的类别标签预测一致性。
受视觉表征的自监督学习[16–20,1]的最新进展的激励,本文首先对ImageNet上半监督学习的“无监督预训练,监督微调”范式进行了全面的研究[21]。在自监督的预训练期间,使用没有类别标签的图像(以任务不可知的方式),因此表示不直接适合特定的分类任务。通过这种对未标记数据的任务不可知的使用,我们发现网络大小很重要:使用大的(深度和广度)神经网络进行自监督的预训练和微调极大地提高了准确性。除了网络规
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









