







“视觉语言预训练与三元组对比学习” 这篇论文与用于目标检测的自监督无较大联系,所以没有看完。
Vision-language视觉语言表征学习 通过 对比损失(例如,InfoNCE损失) 在很大程度上受益于 image-text alignment 图像-文本对齐。这种对齐策略的成功 归因于 其最大化图像与其匹配文本之间的互信息(MI)的能力。然而,简单地执行 跨模态对齐(CMA) 忽略了每个模态中的数据潜力,这可能导致降级的表示。例如,尽管基于CMA的模型 能够在嵌入空间中 将图像-文本对 紧密地映射在一起,但是它们不能确保来自相同模态的相似输入保持在附近。当预训练数据有噪声时,这个问题会变得更加严重。
在本文中,提出了 三重对比学习(TCL)的 视觉语言预训练,利用 跨模态 和 模态内 的自监督。除了CMA,TCL还引入了一个 模态内intra-modal 的对比目标,为表征学习提供了补充性的好处。为了利用 来自图像和文本输入的 局部 和 结构的 信息,TCL进一步 最大化图像/文本的 局部区域 和 它们的全局摘要之间的平均MI。据本文所知,本文是 第一个考虑局部结构信息的 multi-modality多模态表征学习。实验评估表明,本文的方法是有竞争力的,并在各种常见的下游视觉语言任务(如 图像-文本检索 和 视觉问题回答)上 实现最新的技术水平。
Introduction:
自监督 在 视觉 和 语言 表征学习中 都是一个活跃的研究课题。已经提出了许多方法,在具有挑战性的任务中表现出色 [4,6,9,14,16,36]。一种典型的方法是 以自监督的方式 对大量未标记数据的模型进行预训练,然后针对感兴趣的下游任务(例如,零样本学习 和 迁移学习)对其进行微调。在视觉中,可以使用 exemplar 示例 [12]、预测两个随机块 [10] 之间的相对位置 或 通过解决拼图 [28] 来进行自监督。在语言方面,掩码语言建模(MLM)被广泛用作自监督的首选方法。
受 单模态自监督 成功的启发,人们对自监督的视觉语言预训练 (VLP) 产生了浓厚的兴趣,这对于 视觉问答 (VQA)、图像文本检索 和 视觉蕴涵 等多模态任务至关重要。这些任务严重依赖于联合多模态嵌入,通常通过 对 视觉 和 语言 特征之间的交互 进行建模 来获得。
为了实现这一目标,在过去几年 [7, 13, 23, 24] 中,通过利用大量 图像文本对 提出了各种 VLP 框架,其中关键的见解是 将 fusion encoder 融合编码器 应用于 视觉和语言特征的连接 以 学习 联合的表示。虽然简单有效,但这种策略存在 视觉和语言特征 位于不同嵌入空间 的问题,这使得 特征融合 非常具有挑战性[22]。
为了缓解这个问题,最新的技术[22] 将学习过程分解为两个阶段:
- i)首先通过 使用 对比损失(即InfoNCE [29])来对齐 跨模态特征 来 将匹配的图像-文本对的嵌入拉到一起,同时将不匹配对的嵌入分开;
- 然后 ii) 将 融合编码器 应用于 对齐的图像和文本表示 以学习 联合的嵌入。
具体来说,阶段 1 旨在 通过 InfoNCE 损失 最大化匹配的图像-文本对 (I, T ) 之间的互信息 (MI),这是由 I 和 T 表示相同语义的两个“视图” 这一事实所激发的。然而,阶段 1 的局限性在于:简单地执行跨模态对齐(CMA)并不能完全保证学习到的特征的表达能力,而这对于联合多模态表示学习至关重要。主要原因是I和T无法完全地描述对方。例如,(图 1 A)中的文本仅关注配对图像中的显著对象,而忽略了其他详细和细粒度的信息。为了对齐 I 和 T ,CMA 仅捕获同时出现的特征。 [19] 也证明了这一点,其中基于 CMA 的特征在图像-文本检索上的性能 远高于 模态内检索(图像-图像和文本-文本)。此外,预训练数据集通常是从网络上收集的,并且本质上是嘈杂的。这导致学习退化的表示,其中 跨模态特征 无法捕捉某些关键概念。
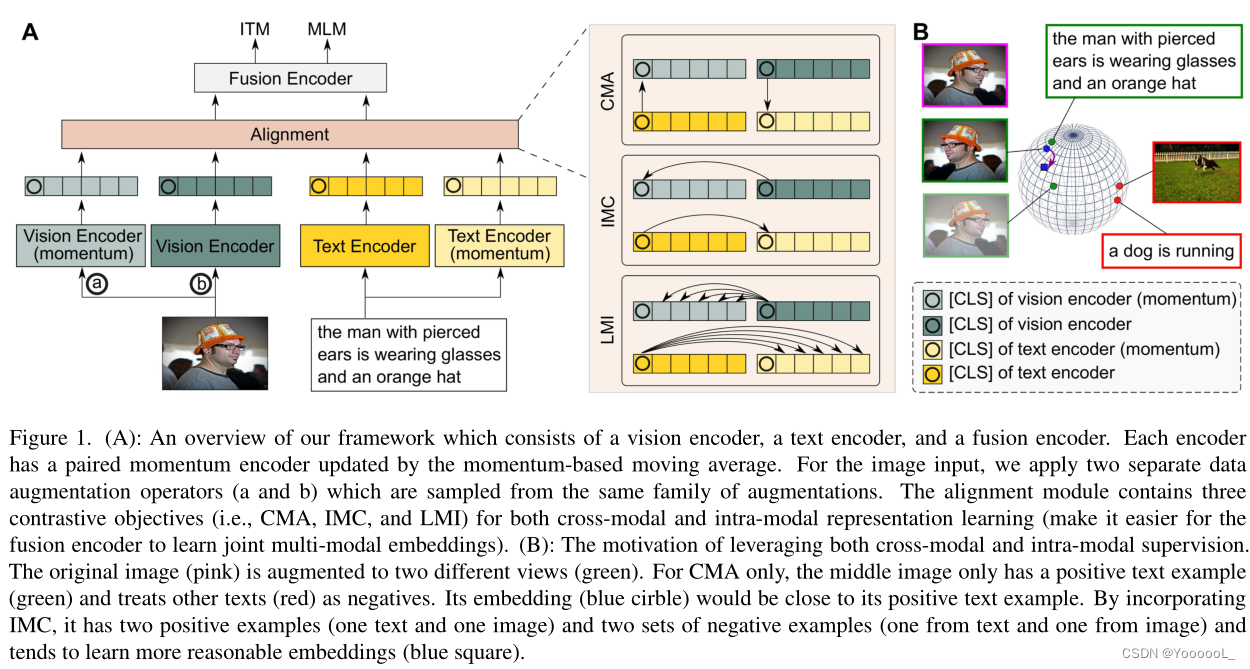
图1:本文框架的概述,它由 视觉编码器、文本编码器 和 融合编码器 组成。每个编码器都有一个由基于动量的移动平均值更新的成对动量编码器。对于图像输入,本文应用了两个独立的数据增强算子(a 和 b),它们是从同一个增强家族中采样的。对齐模块包含三个对比目标(即 CMA、IMC 和 LMI),用于跨模态和模态内表示学习(使融合编码器更容易学习联合多模态嵌入)。 (B):利用跨模式和模式内监督的动机。原始图像(粉红色)被增强为两个不同的视图(绿色)。仅对于 CMA,中间图像只有一个正面文本示例(绿色),并将其他文本(红色)视为负面。它的嵌入(蓝色圆圈)将接近它的正面文本示例。通过结合 IMC,它有两个正例(一个文本和一个图像)和两组负例(一个来自文本,一个来自图像),并且倾向于学习更合理的嵌入(蓝色方块)。















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









