







众所周知,深度学习模型 容易受到 为恶意目的精心设计 且 人类感知系统无法察觉的对抗性示例的攻击。仅在良性示例上训练时,自动编码器已被广泛用于(自监督)对抗性检测,基于 对抗性示例 会产生更大的重构误差 的假设。然而,由于其训练中 缺乏对抗样本 以及 自编码器泛化能力太强,这种假设在实践中并不总是成立。
为了缓解这个问题,本文探索 通过在自动编码器结构下 解耦图像的表示 来检测对抗性示例。通过 将输入图像解耦为 类特征 和 语义特征,我们在判别器网络的辅助下,在 正确配对的类/语义特征 和 错误配对的类/语义特征上 训练自动编码器,以重建 良性示例 和 反例。这模仿了对抗样本的行为,并且可以 减少自动编码器 不必要的泛化能力。本文将本文的方法与 不同对抗性攻击和不同受害者模型(30 种攻击设置)下的最先进的自监督检测方法进行比较,对于大多数攻击设置,它在各种测量(AUC、FPR、TPR)中表现出更好的性能。值得注意的是,与其他基于自动编码器的检测器不同,本文的方法可以抵抗自适应对手。
2013 年,开创性工作 [9] 报告说,在模型测试期间,深度神经网络很容易被 对输入添加微小扰动 的对抗性攻击 所愚弄。从那时起,对抗性攻击和防御引起了广泛的研究关注[1-8]。一方面,攻击者不断开发新策略来构建对抗样本;另一方面,防御者正在努力应对所有现有和即将发生的攻击 [10]。
大多数现有的防御方法 [5-8, 11] 都经过监督训练,这些方法 在防御 最初训练的对抗性攻击 时效果很好。然而,人们普遍认为,监督方法不能很好地推广到来自(现有的)看不见的攻击的对抗样本,更不用说来自 新的攻击的例子了。
与有监督的防御相比,基于自监督的防御只需要良性示例进行训练。作为一个典型的例子,[12, 13] 中的工作利用自动编码器 (AE) 的编码器来绘制良性示例的流形,然后使用解码器网络进行重建,如图 1(a) 所示。由于流形仅从良性示例中学习,并且 AE 被训练以最小化良性示例的重构错误 (RE),因此对抗性示例的编码可能是分布外的,并且相关的 RE 更大。
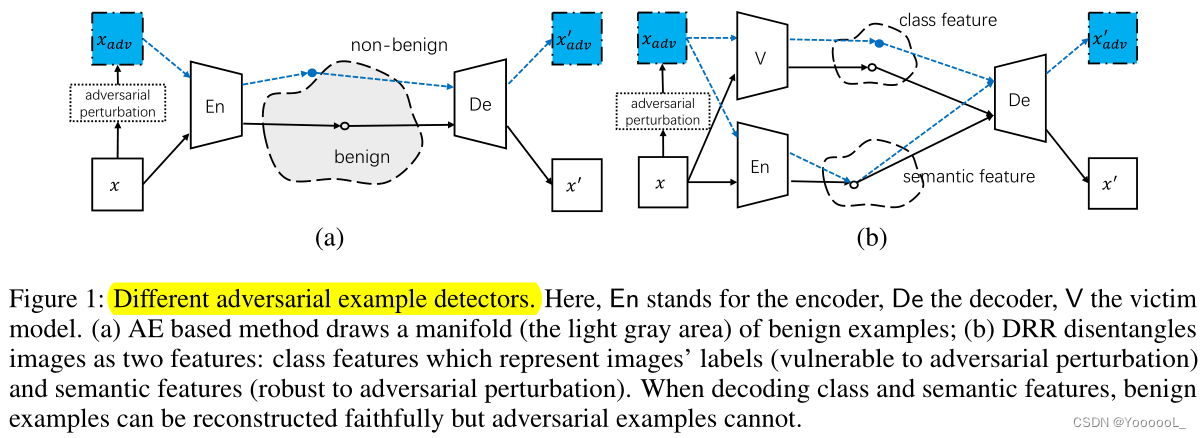
很快就意识到这并不总是正确的,因为 AE 具有很强的泛化能力 [14]:具有各种小扰动的示例可以用小的 RE 重构。如果扰动的例子是良性的,这是可取的。然而,对抗性示例只是良性示例的特定扰动版本,恶意扰动在许多攻击中也可以变得非常小(即,现在它们的编码将位于图 1(a)的浅灰色区域)。发生这种情况时,所有 RE 都混合在一起,并导致检测过程中的 高的假负样本或 假正样本率 (FNR/FPR)。为了细化 AE 绘制的流形的体积 并减少其对 对抗性示例的不必要的泛化能力,存在许多变体 [15-18],这将在第 2.2.节中详细介绍。
作为该问题的更好解决方案,本文提出了一种 基于自监督的解耦合表示的重建 (DRR) 方法来检测对抗性示例。 DRR 具有监督防御的优势,即使它在训练中无法访问任何对抗性示例。这是通过对一类特殊的示例(本工作中的反例)进行编码和解码来模仿对抗性示例的行为来实现的,这是从一个示例重构语义特征和从一个不相关示例重构类特征。基本原理基于对抗性示例的事实:它们会导致错误分类而不改变语义(包含在其良性对应物中)。















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









