







 本文探讨了自监督学习如何通过学习输入样本的联合分布来增强完全监督模型的准确性,而不是传统的多任务学习方法。通过结合原始标签和自监督标签(如旋转、颜色排列),模型的训练不再要求变换不变性,从而提高性能。实验表明,这种方法在少样本、不平衡分类任务以及标准全监督设置中均能显著提高准确性。同时,提出了自蒸馏技术以加速推理过程而不牺牲性能。
本文探讨了自监督学习如何通过学习输入样本的联合分布来增强完全监督模型的准确性,而不是传统的多任务学习方法。通过结合原始标签和自监督标签(如旋转、颜色排列),模型的训练不再要求变换不变性,从而提高性能。实验表明,这种方法在少样本、不平衡分类任务以及标准全监督设置中均能显著提高准确性。同时,提出了自蒸馏技术以加速推理过程而不牺牲性能。
自监督学习通过仅给定输入信号构造人工标签来学习,最近已经获得了对无标签数据集的学习表示的相当大的关注,即,没有任何人类注释监督的学习。在本文中,证明了这种技术即使在完全标记的数据集下,也能显著提高模型的准确性。本文的方案训练模型来学习原始和自监督的任务,但不同于传统的多任务学习框架,传统的多任务学习框架优化其相应损失的总和。本文的主要思想是学习关于原始和自监督标签的联合分布的单个统一任务,即,通过输入变换的自监督来增强原始标签。这种简单而有效的方法允许通过在同时学习原始和自监督任务期间放松某个不变约束来更容易地训练模型。它还实现了组合来自不同增强的预测的聚合推断,以提高预测准确性。此外,本文提出了一种新的知识迁移技术,我们称之为self-distillation 自蒸馏,它具有在单个(更快的)推理中聚合推理的效果。本文的框架在各种完全监督的设置上的大的准确性改进和广泛的适用性,例如,少样本和不平衡分类场景。
(作者们用同样的内容又写了一篇论文“RETHINKING DATA AUGMENTATION: SELF-SUPERVISION AND SELF-DISTILLATION”
数据增强技术,例如翻转或裁剪,通过显式生成更多训练样本来系统地扩大训练数据集,已被广泛用于提高深度神经网络的泛化性能。在监督设置中,数据增强的常见做法是为同一来源的所有增强样本分配相同的标签。然而,如果扩充导致它们之间存在较大的分布差异(例如旋转),强制它们的标签不变性可能很难解决,并且通常会损害性能。
为了应对这一挑战,本文提出了一个简单而有效的想法,即 学习增强样本的原始标签和自监督标签的联合分布。联合学习框架更易于训练,并支持结合来自不同增强样本的预测的聚合推理,以提高性能。此外,为了加快聚合过程,本文还提出了一种自蒸馏类型的知识转移技术,将增强知识转移到模型本身。本文展示了本文的数据增强框架在各种完全监督的设置上的有效性,包括少头部和不平衡分类场景。
自监督:当缺少人类标注的标签时,该方法仅使用输入示例来构造人工标签,然后通过预测标签来学习它们的表示。一种最简单但有效的自监督学习方法是通过仅观察修改后的输入t(x)来预测哪个变换t应用于输入x,例如,t可以是patch置换 或旋转 。为了预测这种转换,模型应该区分什么是语义上自然的,因此,它学习输入的高级语义表示。
基于变换的自监督的简单性鼓励了其在无监督表示学习之外的其他目的的广泛适用性,例如半监督学习 、提高鲁棒性 、训练生成对抗网络 。先前的工作通常为原始任务和自监督任务 维护两个独立的分类器(但共享公共的特征表示),并同时优化它们的目标。然而,当处理完全标记的数据集时,这种多任务学习方法通常不会提供准确性增益。这启发我们探索以下问题:如何有效地利用基于变换的自监督来完成全监督分类任务?
训练深度神经网络 (DNN) 通常需要大量训练样本。当训练样本数量较少时,DNN 变得容易过度拟合,导致测试样本出现高泛化错误。这种过度拟合问题是 DNN 研究的核心,文献中研究了许多正则化技术(Srivastava 等人,2014 年;Huang 等人,2016 年;Gastaldi,2017 年)。最明确和易于使用的正则化技术可以说是数据增强(Zhong 等人,2017 年;DeVries 和 Taylor,2017 年;Zhang 等人,2018 年;Cubuk 等人,2019 年),其目的是通过改变现有的训练集来增加训练集的数量。
在监督学习场景中,数据增强通常是通过使用不影响其语义的多个转换来增强每个样本来完成的。因此,训练期间的数据增强迫使 DNN 对增强变换具有不变性。然而,根据转换的类型,学习变换不变属性可能会很困难或与原始任务竞争,因此可能会损害性能。例如,对于某些细粒度的图像分类任务(例如,鸟类的种类),颜色信息在类别区分中可能是至关重要的,在这种情况下应避免使用颜色变换进行数据增强。
学习不变性并不总是有用的证据可以在许多关于自监督学习的近期著作中找到(Gidaris 等人,2018 年;Zhang 等人,2019 年;Doersch 等人,2015 年;Noroozi 和 Favaro,2016 年),其中模型使用由输入转换构建的人工标签进行训练,例如,旋转图像的旋转度,没有任何人工注释标签。这些工作表明,仅通过学习预测此类转换就可以学习高级表示。这表明,在尝试学习传统数据增强下的变换不变属性时,可能会丢失一些有意义的信息。
虽然自监督最初侧重于无监督学习,但最近有许多尝试将其用于其他相关目的,例如半监督学习(Zhai 等人,2019 年)、鲁棒性(Hendrycks 等人,2019 年)和对抗性生成网络(陈等人,2019 年)。他们通常为 原始任务 和 自监督任务 维护两个独立的分类器(但共享共同的特征表示)。然而,这种多任务学习策略也迫使执行原始任务的初级分类器在自监督方面具有不变性。因此,以这种方式使用自监督标签可能会损害性能,例如,在完全监督的设置中。这启发本文重新审视和探索具有自监督的数据增强方法。
Contributions:
多任务学习方法迫使原始任务的主要分类器相对于自监督任务的变换是不变的。例如,当使用旋转作为自监督时,将每个图像旋转0、90、180、270度,同时保留其原始标签,主分类器被迫学习对旋转不变的表示。强制这种不变性可能会导致任务的复杂性增加,因为转换可能会在很大程度上改变样本的特征和/或用于识别目标的有意义的信息,例如图像分类{6对9}或{鸟对蝙蝠}。因此,这可能会损害整体表示学习,并降低主要的全监督模型的分类精度。
本文主要关注完全监督的学习设置,即不仅假设所有训练样本的原始/主要标签,而且还假设增强样本的自监督标签。本文的主要想法简单直观(参见图 1(a)):维护单个联合分类器,而不是之前的自监督文献中通常使用的两个单独的分类器。例如,如果 原始任务 和 自监督任务分别是 CIFAR10(10 个标签)和旋转(4 个标签),本文将学习 40 个标签的所有可能组合的联合概率分布。这种方法假设原始标签和自监督标签之间没有关系,因此不会强制转换具有任何不变性。此外,由于本文为每个转换分配了不同的自监督标签,因此可以通过在测试时聚合所有转换来进行预测,如图 1(b) 所示。这可以使用单个模型提供(隐式)整体效果。最后,为了加快评估过程,本文还提出了一种新的自蒸馏型知识迁移技术,将聚合预测的知识迁移到模型本身。
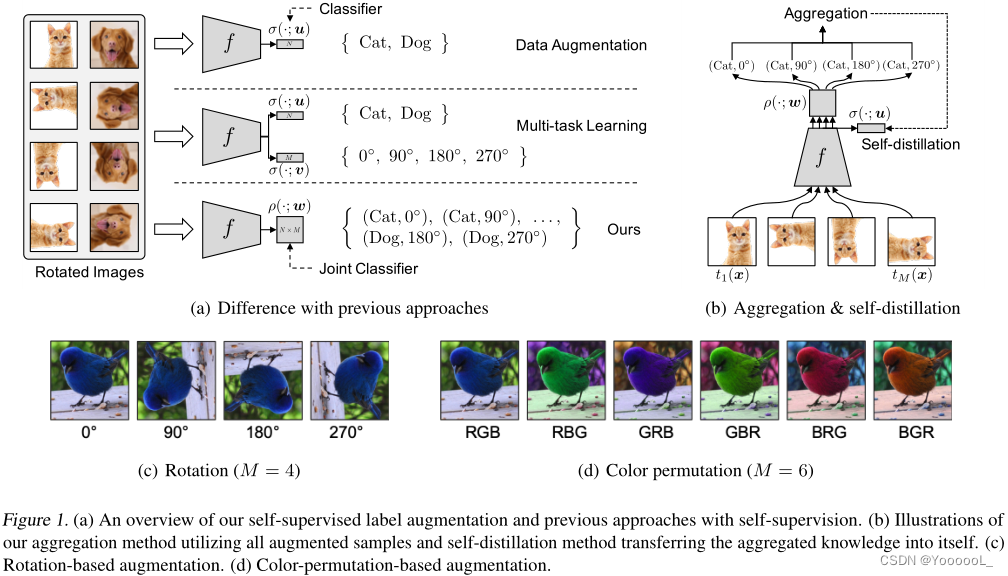
为了应对这一挑战,本文提出了一个简单而有效的想法(见图1(a)),即学习关于原始和自监督标签的联合分布的单个统一任务,而不是先前自监督文献中通常使用的两个独立任务。例如,当在CIFAR10(10个标签)上用旋转的自监督(4个标签)进行训练时,我们学习所有可能组合的联合概率分布,即40个标签。
这种标签增强方法,我们称为自监督标签增强 (SLA),在不假设原始标签和自监督标签之间的关系的情况下,不会强制转换具有任何不变性。此外,由于本文为每个转换
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









