







 本文详细介绍了目标跟踪领域的SiamFC算法,该算法利用深度学习提取特征,结合全卷积网络实现端到端的目标跟踪。文章讨论了从经典跟踪算法到深度学习跟踪算法的发展,并阐述了SiamFC的网络结构、数据处理和实验结果,展现了其在目标跟踪任务中的优势。
本文详细介绍了目标跟踪领域的SiamFC算法,该算法利用深度学习提取特征,结合全卷积网络实现端到端的目标跟踪。文章讨论了从经典跟踪算法到深度学习跟踪算法的发展,并阐述了SiamFC的网络结构、数据处理和实验结果,展现了其在目标跟踪任务中的优势。
一、背景介绍:
[参考资料]:
- https://zhuanlan.zhihu.com/p/148516834
- https://www.jiqizhixin.com/articles/2017-05-14
目标跟踪的方法一般分为两种模式: 生成式模型和鉴别式模型
生成式模型:
早期的一些目标跟踪算法都属于是生成式模型跟踪算法的研究,比如: Meanshift、Particle Filter(粒子滤波)、基于特征点的光流法等等。**此类方法首先建立目标模型或者提取目标特征, 在后续帧中进行相似特征搜索,逐步迭代实现目标定位。**比如Meanshift方法是一种基于概率密度分布的跟踪方法,首先会对目标建模,例如利用目标的颜色分布来描述目标,然后计算目标在下一帧图像上的概率分布,从而迭代得到局部最密集的区域。Meanshift 适用于目标的色彩模型和背景差异比较大的情形。
但是这类方法也存在明显的缺点, 就是图像的背景信息没有得到全面的利用.且目标本身的外观变化有随机性和多样性特点, 因此, 通过单一的数学模型描述待跟踪目标具有很大的局限性.具体表现为在光照变化, 运动模糊, 分辨率低, 目标旋转形变等情况下, 模型的建立会受到巨大的影响, 从而影响跟踪的准确性; 模型的建立没有有效地预测机制, 当出现目标遮挡情况时, 不能够很好地解决。
鉴别式模型:
鉴别式模型是指**将目标模型和背景信息同时考虑在内, 通过对比目标模型和背景信息的差异, 将目标模型提取出来, 从而得到当前帧中的目标位置。 **也有文中指出该模式是利用分类来做跟踪的方法。即把跟踪的目标作为前景,利用在线学习或离线训练的检测器来区分前景目标和背景,从而得到前景目标的位置。
相关滤波的跟踪算法始于 2012 年 P.Martins 提出的 CSK 方法,作者提出了一种基于循环矩阵的核跟踪方法,并且从数学上完美解决了密集采样(Dense Sampling)的问题,利用傅立叶变换快速实现了检测的过程。在训练分类器时,一般认为离目标位置较近的是正样本,而离目标较远的认为是负样本。相关滤波系列的方法发展很快,比如 CSK 作者引用的 MOSSE 方法,后续他又提出了基于 HOG 特征的 KCF 方法。后续还有考虑多尺度或颜色特征(Color Name 表)的方法以及用深度学习提取的特征结合 KCF 的方法(比如 DeepSRDCF 方法)等。从它的发展过程来看,考虑的尺度越来越多,特征信息也更加丰富,当然计算时间也会相应增加,但总体上说,相关滤波系列的跟踪方法在实时性上优势明显,采用哪种改进版本的方法视具体的应用而定。相关滤波的方法也有一些缺陷,比如目标的快速移动,形状变化大导致更多背景被学习进来等都会对 CF 系列方法造成影响。虽然后续的研究也有一些针对性的改进,比如改进边界效应,改善背景更新策略或提高峰值响应图的置信度等,但普适性还需要进一步研究,特别是对不同的应用针对性地调整。
基于深度学习的方法,在大数据背景下,利用深度学习训练网络模型,得到的卷积特征输出表达能力更强;深度学习还有一大优势就是端到端的输出。
【总结】:目标跟踪的方法经历了从经典跟踪算法 -> 基于核相关滤波的跟踪算法 -> 基于深度学习的跟踪算法
传统目标跟踪的问题是通过学习对象的外观模型来解决的,只使用视频本身作为的训练数据。效果不错,但它们只用在线的方法本质上限制了它们所能学习的模型的丰富性。随着深度学习的在计算机视觉中的应用,大家也想尝试用深度卷积网络来解决目标跟踪问题,但是我们一般会通过一个大型监督数据集来训练一个网络,所以缺乏这种大规模的数据集和另一个实时性的要求就成为了一个限制。这对上面提到的限制,在这篇论文提出的时候已经有下面的一些相关的工作了:
- 把深度网络当作一个特征提取器,然后应用到相关滤波的跟踪框架中。
- 针对特定目标,采用在线SGD微调网络,用于当前目标跟踪任务。
但是这两种方法都有不足,第一种没有充分利用端到端的学习优势,第二种速度慢。
作者在本篇论文中提出了全卷积孪生网络,在初始离线阶段,深度卷积网络被训练于应对更加一般的相似性学习问题,然后在跟踪期间简单地在线评估该函数。
二、网络结构:
如何实现目标跟踪? 我们可以用相似性学习来解决这个问题。相似性的度量有很多类,比如距离、相关系数、角度(余弦相似度)等等。这篇论文使用的卷积运算,后面会介绍。我们学习一个函数 f ( z , x ) f(z,x) f(z,x),该函数将样本图像z和候选图像x进行比较,如果两个图像描述的内容很相近,就获得高分,否则获得低分。
具体到这篇论文是如何实现的呢?在训练阶段,我们会有两个不同的输入,输入z代表样本图像,输入x代表搜索图像,这两个输入的尺寸是不一样的,是从一个视频段的每一帧图像中随机选取一帧作为样本图像,然后在距离此帧图片不超过100帧的范围内随机选取另一帧是搜索图,然后对这两张图片进行裁剪以及平均颜色填充,等比例缩放等操作得到不同尺度的图片对。在这个过程中,目标所在位置始终都是图像的中心位置。经过卷积神经网络进行特征提取,也就是这里的 φ \varphi φ所代表的函数的作用。对于所提取到的特征图进行相似性计算,相似性计算有很多种方式,这里的相似性计算采用的是卷积的操作,最终得到一个相似性得分。
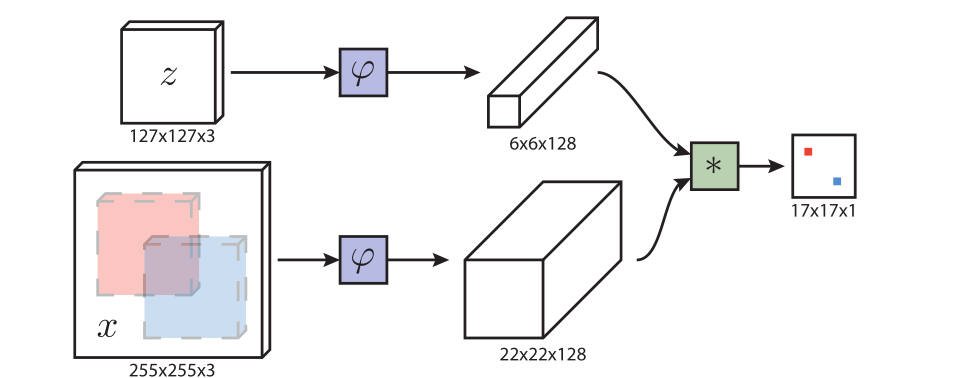
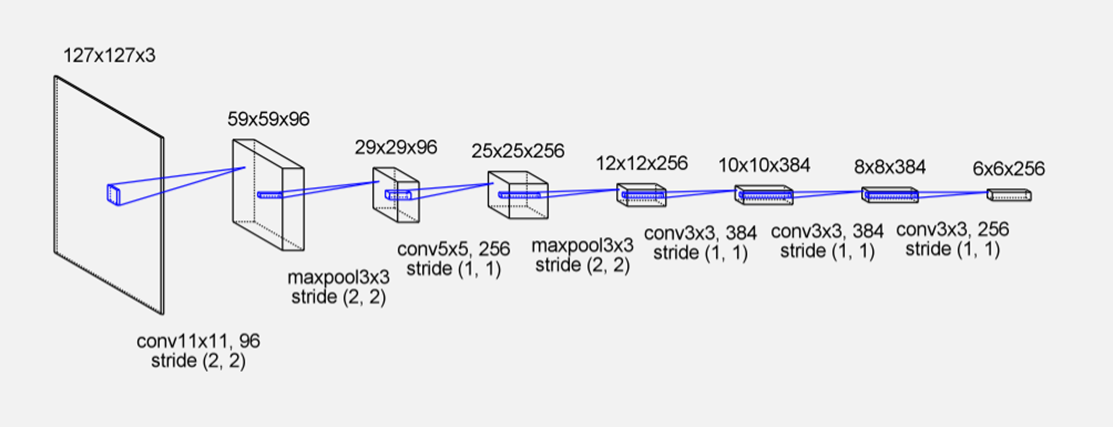
论文提出的全卷积孪生网络结构,它可以实现端到端的训练,上面提到的 φ \varphi φ 就是一个神经网络,卷积神经网络的具体构造是在AlexNet的基础上做的调整,比如说没有了padding操作,它采用了五层的卷积操作,前两层有最大池化,激活函数采用RELU等等。
卷积的理解:(参考: https://www.cnblogs.com/shine-lee/p/9932226.html)
卷积和相关:
相关是将滤波器在图像上滑动,对应位置相乘求和;卷积则先将滤波器旋转180度(行列均对称翻转),然后使用旋转后的滤波器进行相关运算。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









