







 本文针对自监督对比学习中的不变性假设进行了讨论,指出在某些任务中,特定的不变性可能产生负面影响。作者提出Leave-one-out Contrastive Learning (LOOC)框架,通过构建独立的嵌入空间学习变化和不变因子,避免对下游任务先验不变性知识的依赖。实验表明,LOOC在处理不同数据增强时能更好地捕捉关键信息,提高任务性能。
本文针对自监督对比学习中的不变性假设进行了讨论,指出在某些任务中,特定的不变性可能产生负面影响。作者提出Leave-one-out Contrastive Learning (LOOC)框架,通过构建独立的嵌入空间学习变化和不变因子,避免对下游任务先验不变性知识的依赖。实验表明,LOOC在处理不同数据增强时能更好地捕捉关键信息,提高任务性能。
WHAT SHOULD NOT BE CONTRASTIVE IN CONTRASTIVE LEARNING
一、背景介绍:
现在的自监督对比学习方法,大多通过学习对不同的数据增强保持不变,从而学习到一个好的视觉表征。这里就隐含地假设了一组特定地表示不变性,(比如颜色不变性),但是如果下游任务不满足这种假设条件时,(比如区分黄色轿车和红色轿车),这种方法可能就会对任务起到反作用。
对于数据增强来说,我们在网络中引入的每一种增强都是鼓励网络对该种变换保持不变性。

如上图所示,自监督对比学习依赖于(a)中描述的数据扩充来学习视觉表征。然而,目前的方法通过鼓励神经网络对信息不太敏感来引入感应偏差,可能有帮助也可能有伤害。如(b)所示,旋转不变嵌入对某些花卉类别有帮助,但可能会损害动物识别性能;相反,颜色不变性通常似乎有助于粗粒度的动物分类,但会损害许多花卉类别和鸟类类别。
所以本文提出一种对比学习框架,它不需要特定地、任务相关地不变性的先验知识,通过构造独立的嵌入空间来学习捕获视觉表示的变化和不变因子,每个嵌入空间对除一个增广外的所有增广都是不变的。目的就是想在对比学习的框架中能够捕获到个体变换的因素。而无需假定下游不变性的先验知识。
二、理论方法:
**对比学习通过最大化数据样本的相似性和相异性来学习表示,这些数据样本分别被组织成相似和相异对。**也就是我们说的正样本对和负样本对。
我们一般使用的数据增强策略是通过一个数据增强模块,其中包含了几个数据增强的原子操作,比如随机裁剪,颜色、翻转等。对于一个样本图像 I I I,经过数据增强后得到随机视图 I ~ \widetilde{I} I , 正样本对是对同一模板图进行数据增强得到的,负样本对可以是对不同样本图进行数据增强得到的。然后经过特征提取网络,再经过projection head 提取表示 进一步映射到一个特征空间中进行度量。比如 InfoNCE损失函数:
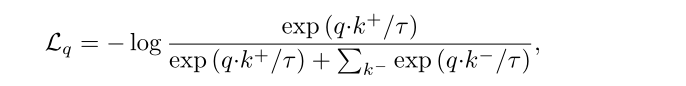
该论文研究不同的任务可能适用不同的增强策略,比如,颜色在鸟类的细粒度分类中起着重要作用,再比如,旋转增强对于花和汽车的分类是有差异的,花旋转后可能会比较相似,但是汽车可能就完全不相似了。
本文提出了一个框架 Leave-one-out Contrastive Learning (LOOC),称为多元强化对比学习框架。该框架可以有选择地防止因扩充而导致的信息丢失。
- 多个 embedding space
- 每个embedding space对某一个增强不是不变的,而是专注于单个增强
每个embedding space专用于单个增强,共享层将包含增强变化和不变信息,我们通过几个嵌入空间共同学习一个共享表示。我们要么单独将共享表示,要么将所有空间的连接转移到下游任务。

以翻转和颜色的数据增强来看,首先参考图像 I I I被扩充为两个视图q、k。它们是经过了不同但有规律的数据增强得到的。视图 q q q和 K 0 K_0 K0分别经过两组独立的数据增强操作,或者可以理解为互斥。就是不同角度的旋转和不同颜色的增强。其他的几个视图分别是相对于视图 q q q来说只有一处增强不同,其他数据增强操作保持一致。 I q I_q Iq和 I
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2151
2151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









