




 本文简要梳理了注意力机制的发展,从RNN、LSTM、GRU到Encoder-Decoder框架,重点介绍了Transformer模型的self-attention计算过程、多头注意力和位置编码。这些技术在处理序列数据,尤其是解决长距离依赖问题上发挥了重要作用。
本文简要梳理了注意力机制的发展,从RNN、LSTM、GRU到Encoder-Decoder框架,重点介绍了Transformer模型的self-attention计算过程、多头注意力和位置编码。这些技术在处理序列数据,尤其是解决长距离依赖问题上发挥了重要作用。
最近在看注意力机制,开始是从Google 2017年的那篇Attention is all you need的论文读起,在大概了解了自注意力机制以后,还是有很多疑问,所以就查阅了很多资料,试图梳理一下注意力机制的发展脉络。下面列出的参考资料都是我认为很不错的内容,统一在开篇列出。本文并不涉及太多深入的讲解,更多的是想从宏观的角度出发,对注意力机制的发展过程做一个简要的梳理,比如每一个阶段遇到什么问题?是如何解决的?解决的方案本身又存在什么问题?正是这些问题推动了它的进一步的发展。
参考资料:
-
论文:
① [attention is all you need] https://arxiv.org/abs/1706.03762
② [A Survey on Visual Transformer] https://arxiv.org/abs/2012.12556
③ [Attention Mechanism. 2015.ICLR] https://arxiv.org/pdf/1409.0473.pdf
-
文章:
① https://mp.weixin.qq.com/s/hn4EMcVJuBSjfGxJ_qM3Tw
② https://samaelchen.github.io/deep_learning_step6/
③ https://www.jianshu.com/p/b2b95f945a98
④ https://zhuanlan.zhihu.com/p/50915723
⑤ https://blog.csdn.net/qq_32241189/article/details/81591456
⑥ https://blog.csdn.net/u014595019/article/details/52826423
⑦ http://jalammar.github.io/illustrated-transformer/
⑧ https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html#self-attention
⑨ https://samaelchen.github.io/deep_learning_step6/
-
视频:
① https://www.bilibili.com/video/BV1Wv411h7kN?p=23
② https://www.bilibili.com/video/BV1Wv411h7kN?p=24
③ https://www.bilibili.com/video/BV1Wv411h7kN?p=27
1. Background:
对于卷积神经网络CNN来说,不论是图像分类、目标识别或者其他任务,每个输入的数据都是独立的,不同输入之间是没有联系的。但是在某些场景中,我们的数据就可能是有相互依赖关系的,这就是序列数据,比如在机器翻译中,语音识别或者视频处理等任务中,数据的前后会存在一定的依赖关系。
针对这种有上下文依赖关系的数据,提出了RNN这种网络结构,RNN的核心思想即是将数据按时间轴展开,每一时刻数据均对应相同的神经单元,且上一时刻的结果能传递至下一时刻。至此便解决了输入输出变长且存在上下文依赖的问题。
1.1 RNN:
最简单的RNN示例图:
其网络结构本质上是一个小的全连接循环神经网络,它的训练过程与一般的DNN网络训练方法类似,采用BP算法完成权重参数更新。而且需要注意的是 对于RNN网络来说,不同输入的对应的参数是共享的。
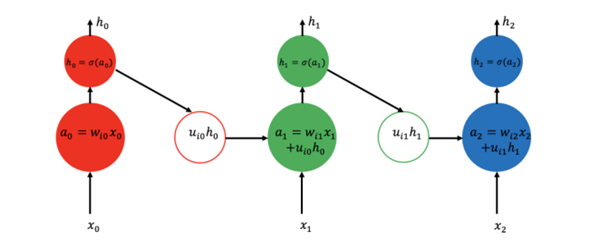
1.2 Deep RNN:
深层循环神经网络(Deep RNN)是循环神经网络的一种变种。为了增强模型的表达能力,可以在网络中设置多个循环层,将每层循环网络的输出传给下一层进行处理。对于普通的RNN,每一时刻的输入到输出之间只有一个全连接层,即在输入到输出的路径上是一个很浅的神经网络,因此从输入中提取抽象信息的能力将受到限制。而对于Deep RNN如下图所示,在每一时刻的输入到输出之间有多个循环体,网络因此可以从输入中抽取更加高层的信息。和卷积神经网络类似,每一层的循环体中参数是一致的,而不同层中的参数可以不同。
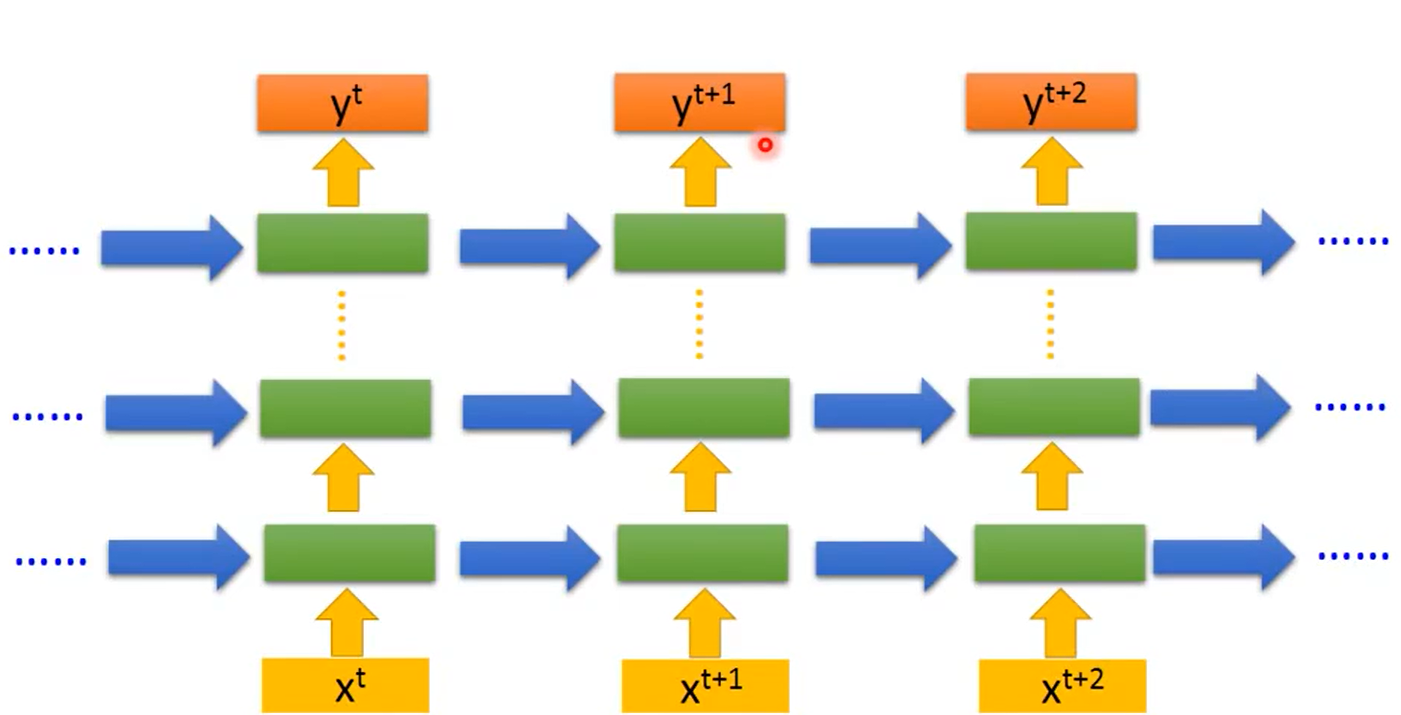
1.3 Bidirectional RNN:
对于一般的RNN网络,在t时刻的输出是考虑前面t-1个时刻的输入以及当前时刻的输入xtx_txt确定的。而在某些应用中,例如语音识别,由于协同发音和词与词之间的语义依赖,当前声音作为音素的正确解释可能取决于未来几个音素。因此,网络当前时刻t输出的预测值yty_tyt可能依赖整个输入序列,所以就出现了双向RNN这个结构。
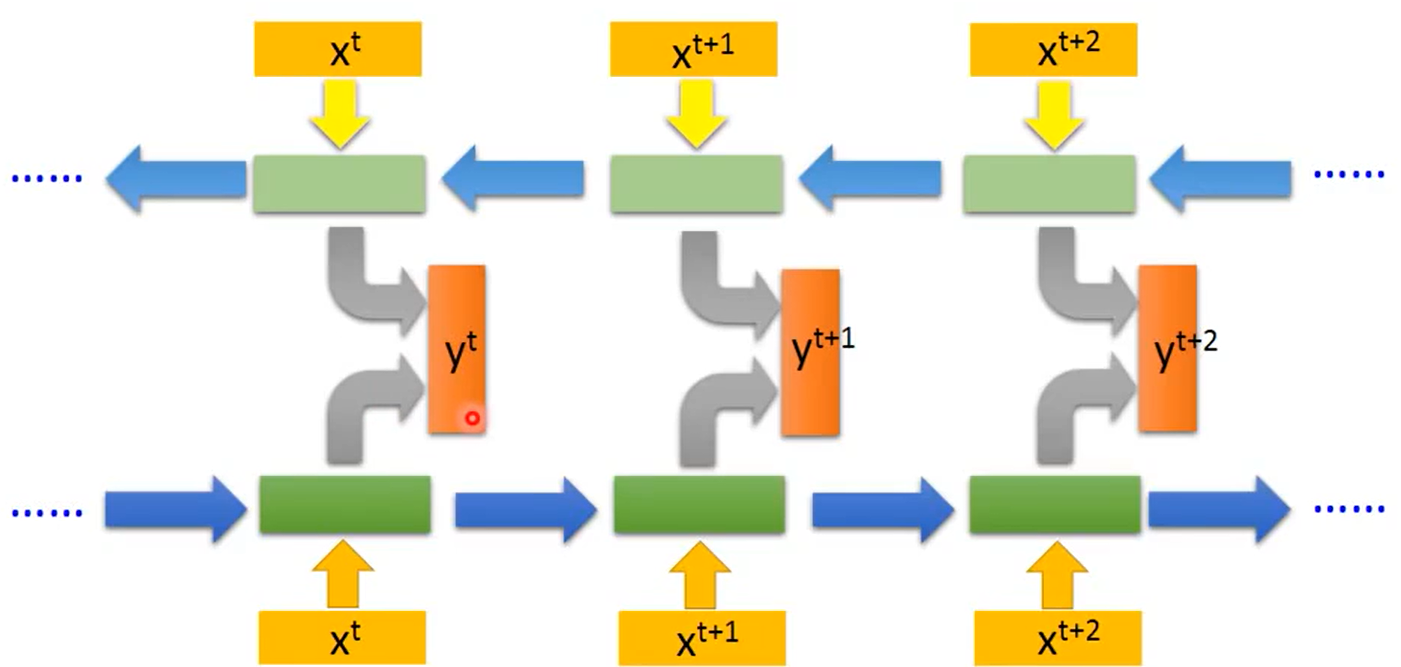
相比于单向的RNN,Bidirectional RNN的每一个输出都考虑了整个sequence的信息。
1.4 RNN的不足:
虽然RNN对于序列数据给出了较好的解决方案,然而对于较长的序列输入,为解决长期依赖问题,我们一般需要较深的神经网络,但是同一般的深度网络一样,RNN也存在优化困难的问题,即训练时间长,同时,在方向传播过程中,随着网络层数的加深,也会出现梯度消失和梯度爆炸的问题。对于梯度消失问题,由于相互作用的梯度呈指数减少,因此长期依赖信号将会变得非常微弱,而容易受到短期信号波动的影响,对此可行的解决方法包括网络跨层连接、ESN、回声状态网络或引入leaky unit。而对于梯度爆炸问题,我们一般采取梯度截断的方法。
RNN非常擅长处理输入是序列数据的问题,但是它有一个问题就是不能并行化计算。
我在这里对长期依赖问题做了一个简单的推导,如下图所示:

通过链式求导的计算过程就可以发现,越是早期的输入,越是会累积更多的梯度相乘,这种连乘就会导致早期的输入对当前时刻产生的影响越微弱。
1.5 LSTM:
针对长期依赖的问题,LSTM采用了一种新的网络结构,每一个LSTM单元不仅接受此时刻的输入数据 xtx_txt和上一时刻的状态信息yt−1y_{t-1}yt−1 ,其还需建立一个机制能保留前面远处结点的重要信息不会被丢失。通过设计“门” 结构实现保留信息和选择信息功能(遗忘门、输入门),其实从宏观上来理解就是通过这种机制让网络遗忘以前不重要的信息,而能够保留之前重要的信息。
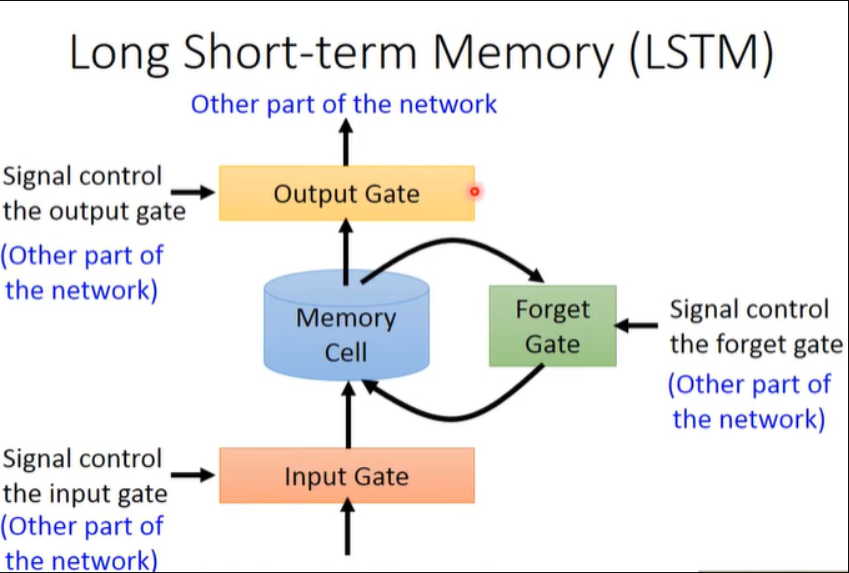
1.6 GRU:
LSTM结构比较复杂,所以研究人员也在考虑如何简化它,GRU与LSTM最大的区别是其将输入门和遗忘门合并为更新门(更新门决定隐状态保留放弃部分)
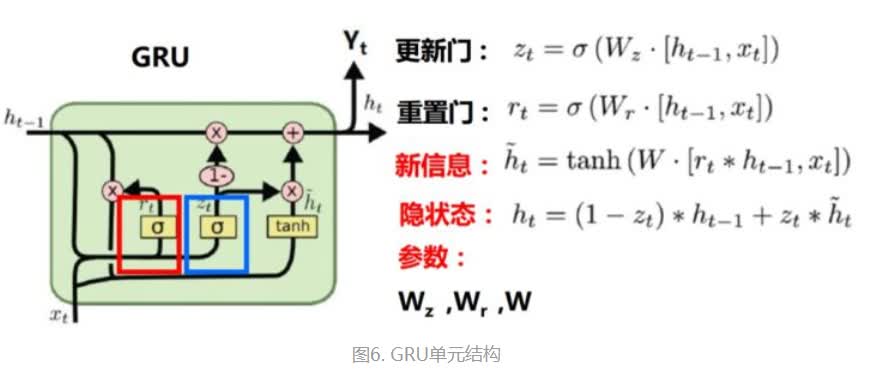
1.7 Encoder-Decoder框架:
在上面的讨论中,我们均考虑的是输入输出序列等长的问题,然而在实际中却大量存在输入输出序列长度不等的情况,如机器翻译、语音识别、问答系统等。这时我们便需要设计一种映射可变长序列至另一个可变长序列的RNN网络结构—Encoder-Decoder框架。
简单来说,一个RNN解决不了的问题,我们用两个RNN试一试,当然这里并不是说必须要用RNN,还可以有基于CNN、基于Transformer的Seq2Seq模型。
Encoder-Decoder框架是机器翻译(Machine Translation)模型的产物,其于2014年Cho et al.在Seq2Seq循环神经网络中首次提出。Seq2Seq模型的基本思想非常简单一一使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度(注意是固定维度,下文的注意力集中机制将在此做文章)的编码中;再使用另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。这两个循环神经网络分别称为编码器(Encoder)和解码器(Decoder)。
这只是大概的思想,具体实现的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合。比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等
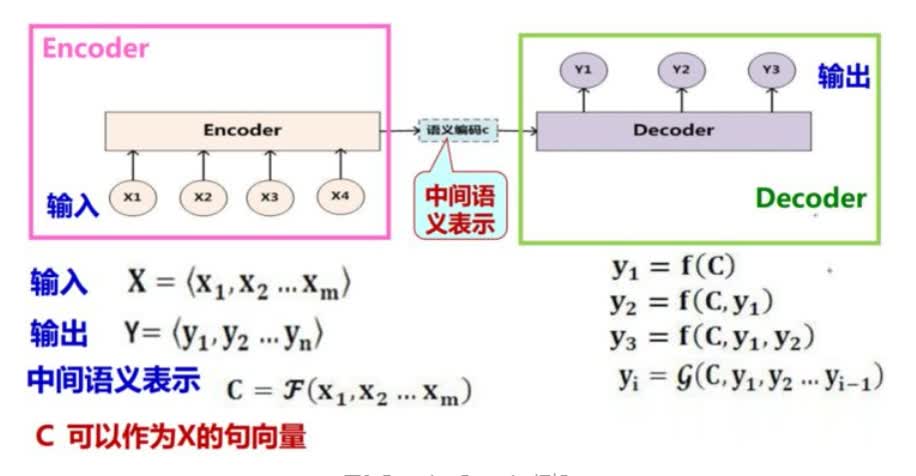
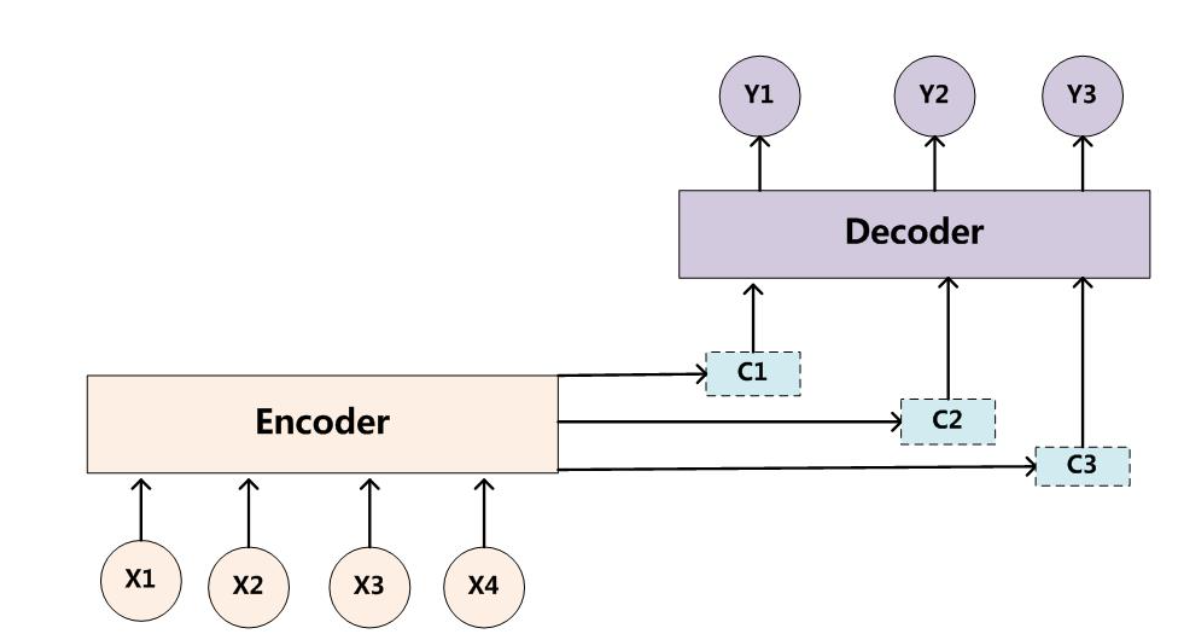
针对Encoder-Decoder框架,我们在网络中间计算出的语义表示是一个固定长度的向量,那么对于不同长度的输入数据,这个固定长度的向量是否都能够很好的表示每个输入的语义信息呢?答案是不能。Encoder-Decoder框架在输入长度比较大的序列数据,会出现性能显著下降的问题。其实这就是因为用固定长度的向量去概括长句子的所有语义细节十分困难。
为了克服这一个问题,发表在ICLR 2015的论文[NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE]提出了自适应的选择编码向量的部分相关语义细节片段进行解码翻译的方案。也就是首次提出了注意力机制。
2014年Sutskever等人提出seq2seq模型(Encoder-Decoder框架)首次实现了End-to-End的机器翻译。2015年,Bahdandu等人发明了注意力机制缓解了长句子性能急剧下降的问题,并将其简单的应用于多种语言的翻译任务中。
2. Attention Mechanism:
Attention Mechanism最早引入至自然语言中是为解决机器翻译中随句子长度(超过50)增加其性能显著下降的问题,现已广泛应用于各类序列数据的处理中。
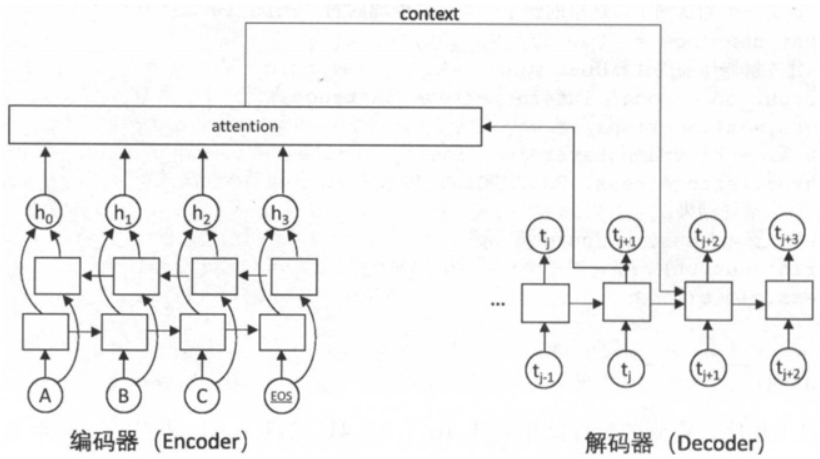
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。
注意力机制的主要亮点在于对于seq2seq模型中编码器将整个句子压缩为一个固定长度的向量c ,而当句子较长时其很难保存足够的语义信息,而Attention允许解码器根据当前不同的翻译内容,查阅输入句子的部分不同的单词或片段,以提高每个词或者片段的翻译精确度。具体做法为解码器在每一步的解码过程中,将查询编码器的隐藏状态。对于整个输入序列计算每一位置(每一片段)与当前翻译内容的相关程度,即权重。再根据这个权重对各输入位置的隐藏状态进行加权平均得到“context”向量(Encoder-Decoder框架向量c ),该结果包含了与当前翻译内容最相关的原文信息 。同时在解码下一个单词时,将context作为额外信息输入至RNN中,这样网络可以时刻读取原文中最相关的信息,而不必完全依赖于上一时刻的隐藏状态。对比社seq2seq,Attention本质上是通过加权平均,计算可变的上下文向量c 。【挑重点】
在注意力机制之后,针对机器翻译领域得到了进一步的发展,2016年谷歌针对多语言翻译任务提出了一种新的解决方案:single model to translating multiple languages,更为强大的是其模型能够实现Zero-shot translation. 2016年Google提出了GNMT,主要是针对网络的性能和翻译质量做进一步改进.
3. Transformer:
虽然GNMT在多语言的翻译问题上取得了很好的效果,然而由于其网络结构是基于传统的RNN、LSTM等序列建模的方式,其很难实现并行,训练时间较长。Google于2017年提出了一种全新的Attention Mechanism即Transformer.
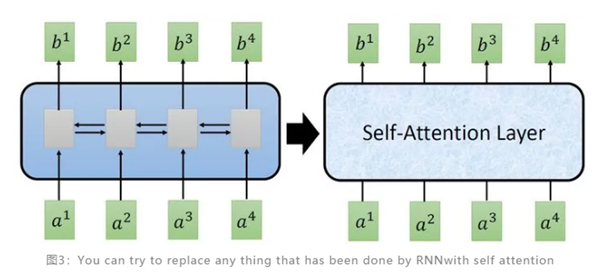
从上图可以看出,我们希望self-attention能够在处理每一个输入的数据时能够考虑整个序列信息,同时最重要的是它可以并行计算,来提升训练速度。
self-attention与RNN的不同:
-
self-attention 考虑整个输入的信息,而RNN只考虑了左边的输入信息
双向RNN可以看作是考虑了整个输入信息
-
RNN很难考虑早期的输入信息
-
RNN不能并行处理
3.1 self-attention计算过程:
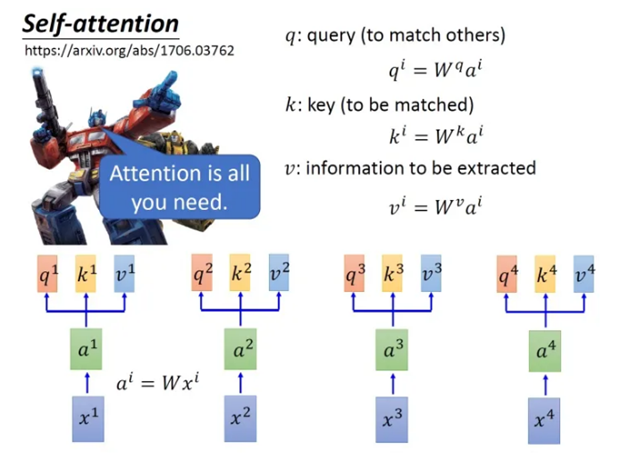
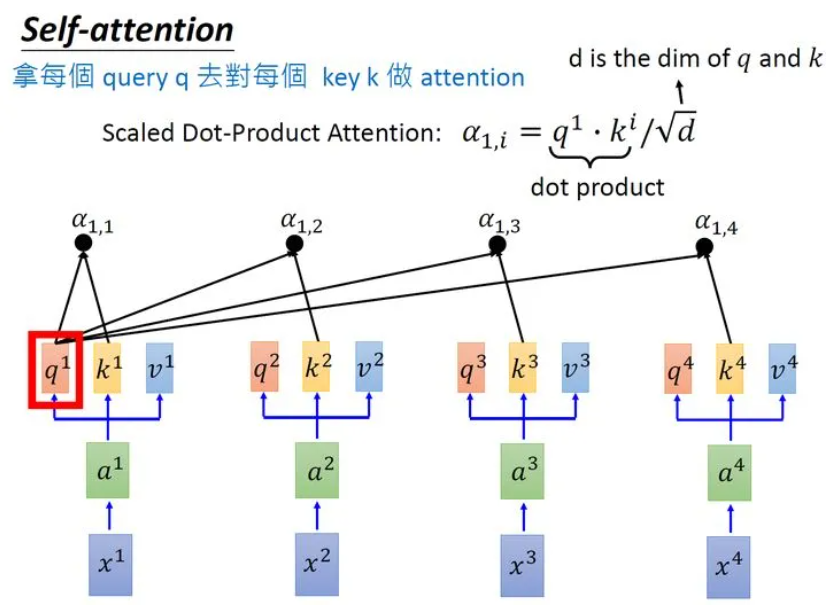
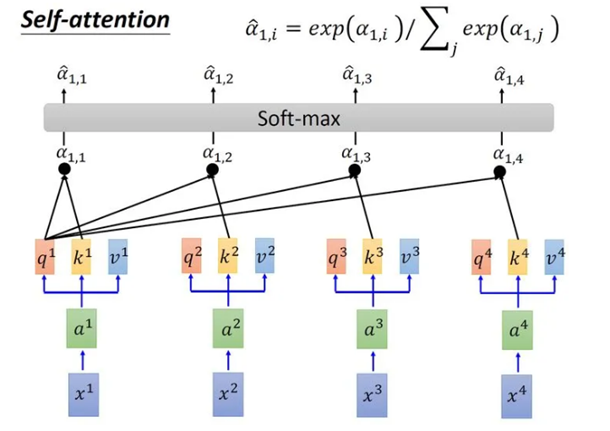
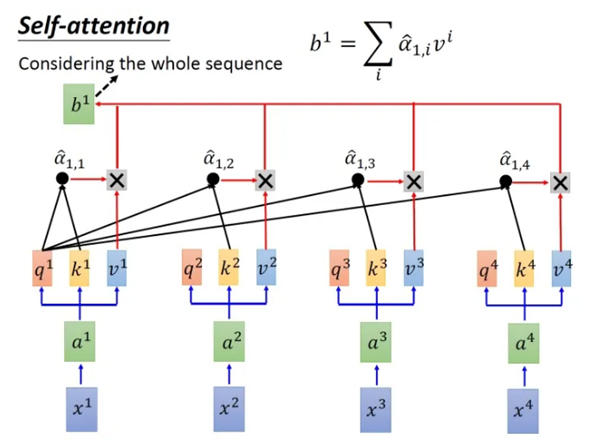
3.2 Multi-head:
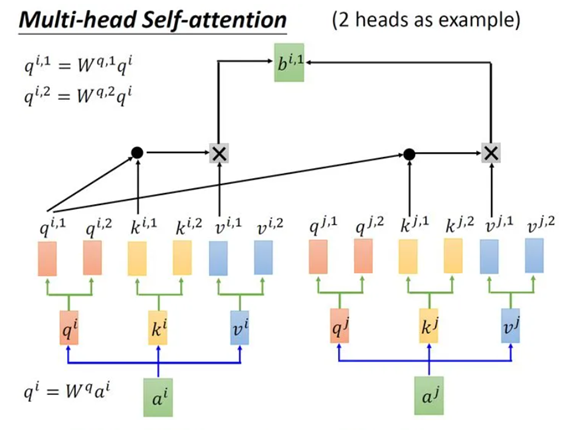
多头注意力的提出,主要是考虑了不同输入之间的相关性可能不只是一种,还存在其他的相关性,所以尝试使用不同的矩阵对来表示不同的相关性。
3.3 Positional Encoding:
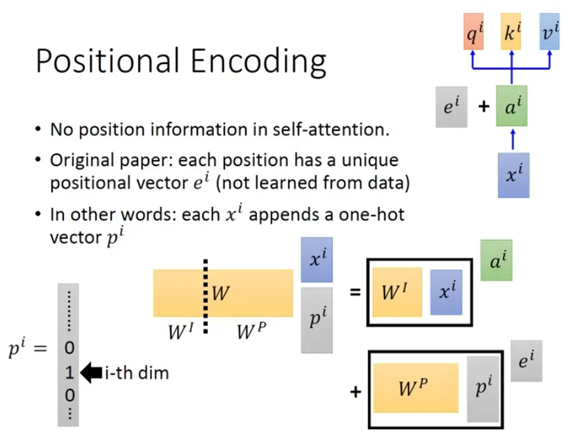
从上面的计算过程中,你会发现所有的输入之间似乎并没有体现出位置的差异,有一句话是这么说的“天涯若比邻”。所以我们需要在网络中体现出位置的差异,在Attention is all you need这篇论文中,作者就提出了位置编码的解决方案,通过给每一个输入添加一个位置信息来代表位置的差异。而这个位置编码是如何产生的呢?可以是手工设计也可以是学习出来的,所以这里也是一个可调整的空间。

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









