






聚类概述
定义

距离的定义
计算聚类过程中点和cluster的距离,有以下几种方式:

算法的分类

启发式算法
概述
启发式算法有两种方法,从下而上或者从上而下。
以从下而上为例,一开始每一个obes就是一个cluster,然后根据距离,不断地结合两个更近的cluster到一个cluster,达到一定的收敛条件后停止。

KEY POINTS

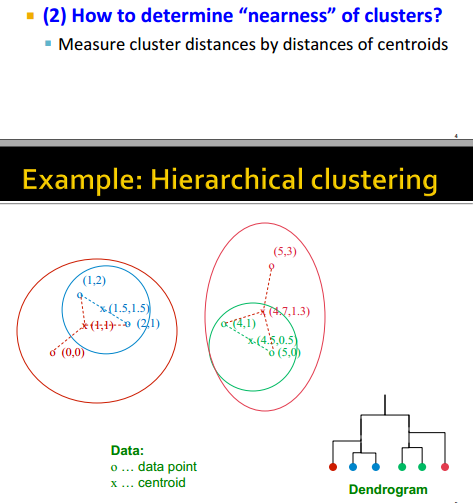
如何代表cluster

如何决定距离远近
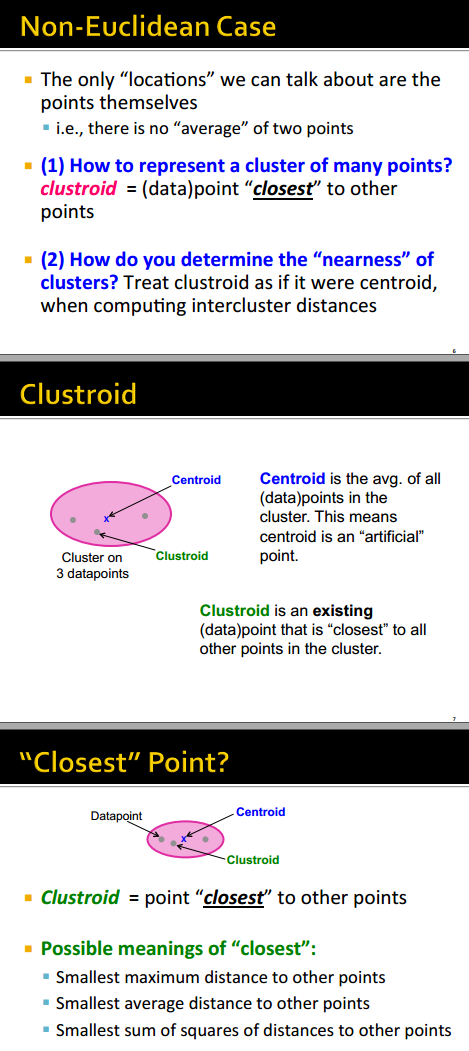
没有欧氏距离怎么办
终止条件

总结

K-MEANS算法
特点
- 假设欧氏距离,也就是欧式空间是存在的
- 一开始必须确定k
- 初始集群先随机选择centroid点,个数等于k(朴素的方法是随机选择,但是容易产生距离太近属于一个cluster的点,影响分类结果)。
过程
首先先选择k个初始点当做群的中心,然后数据集中的所有点根据与群中心的远近划分属于哪个群。然后在根据群的性质取群的中心点,然后再次划分所有点属于的群,不断往复,直到群的中心不发生变化,达到稳定的状态停止。
KEY-POINTS
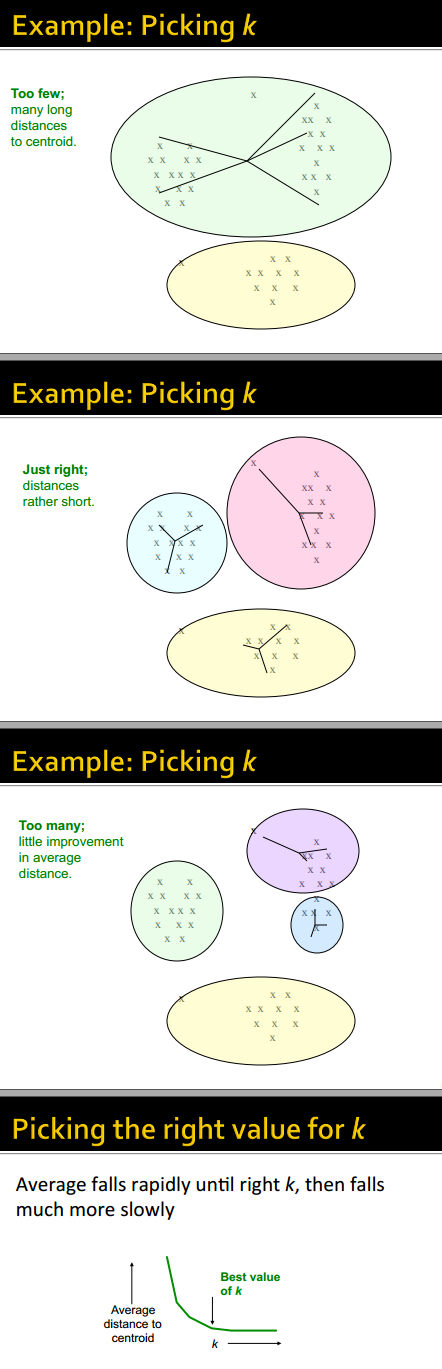
选择k
策略是:多选择几个k,看看average distance to centroid如何变化。
理论上,随着k的增加,这个值应该越变越小,但是减少的幅度也越来越小,我们需要的就是那个拐点。
选择初始点
初始点的选择很有学问,不能够太近都属于一个cluster,这样的话其他的cluster就发现不了。
所以,应该让点越分散越好。

复杂度

BFR算法
大数据集的难题
前面讨论的启发式算法的复杂度是
O(n3)
,使用priority queue的话能减低到
O(n2logn)
。
KMEANS的复杂度是
KN
,但是收敛很慢,也不适用于大数据集。
因此,我们需要一种算法,能够处理数据量很大的分类问题。
概述
BFR(Bradley-Fayyad-Reina)算法,是KMEANS的变种,适用于大数据的分类(数据量只能在disk中存储,不可能全部放在memory里)。
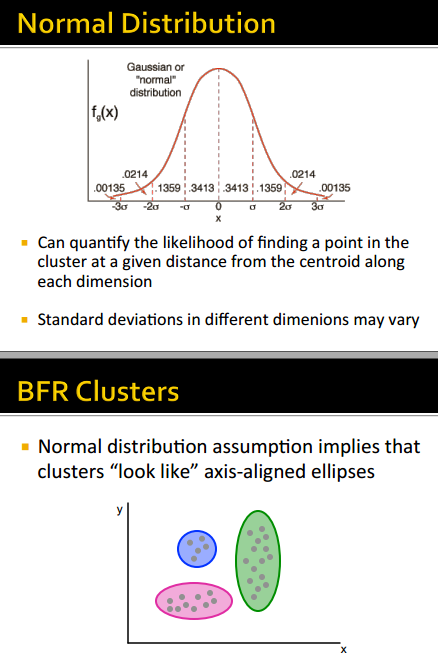
这个算法的基础是一个很重要的假设:
assumes each cluster is normally distributed around a centroid in Euclidean space.
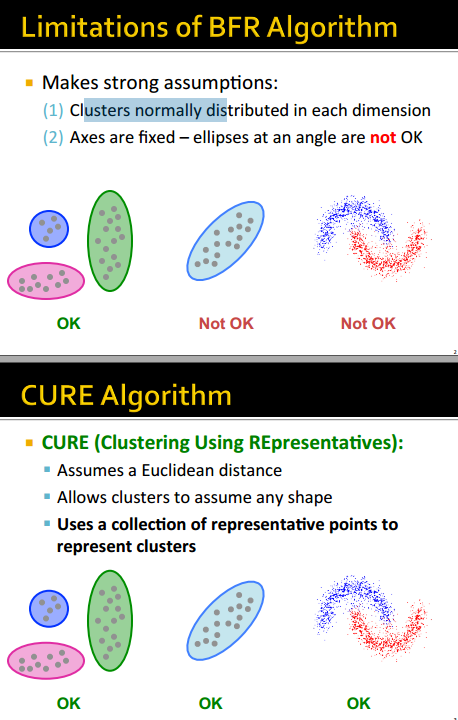
假设
假设的存在,使得每个cluster长得都像下图这样:
- axis-aligned
- normal distribution among each cluster in each dimension
算法
概述
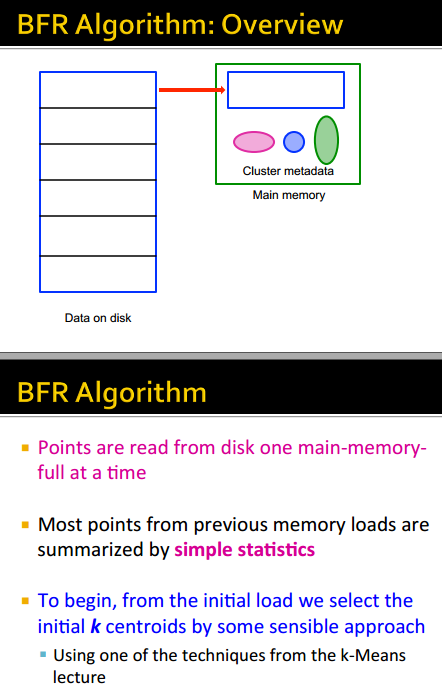
三类点
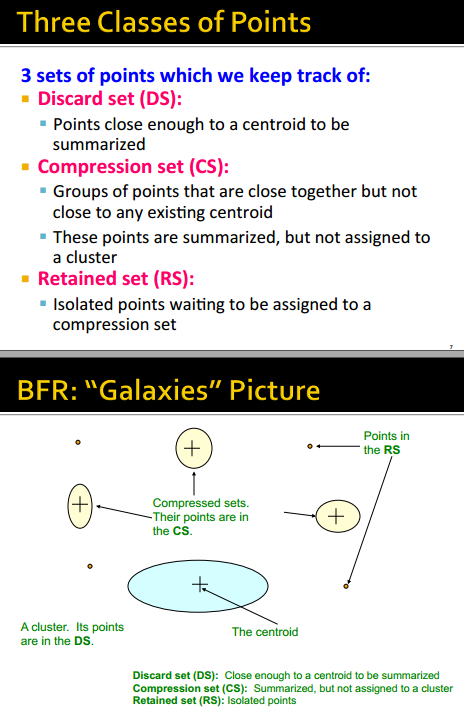
DS点的更新与数据特征

整个流程

细节
怎么判断点离群中心是不是够近以加入DS

怎么判断2个CS是不是应该合成一个

CURE算法
其他算法的限制
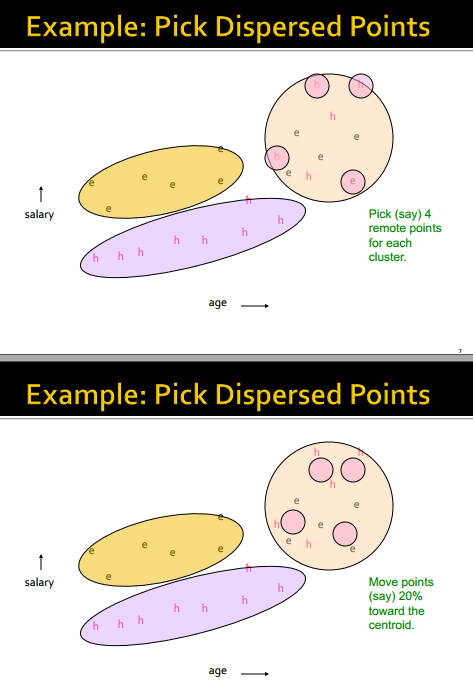
步骤1
核心思想就是先用一些样本训练出大概的样子,并且用4个数据很好地用样本代替了总体。


















 4581
4581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









