







Adam算法
——可以让梯度下降运行得更快,更有效率地进行损失函数最小化
1. 解决问题
在传统梯度下降算法里,有这样的问题:
· 有时候,学习率过小会使得向损失函数最小的方向调整过慢;
· 有时候,学习率过大又会出现损失函数变化太大,左右摇摆的情况;
Adam算法可以自动调整学习率,使得其过小的时候增大,过大的时候减小。
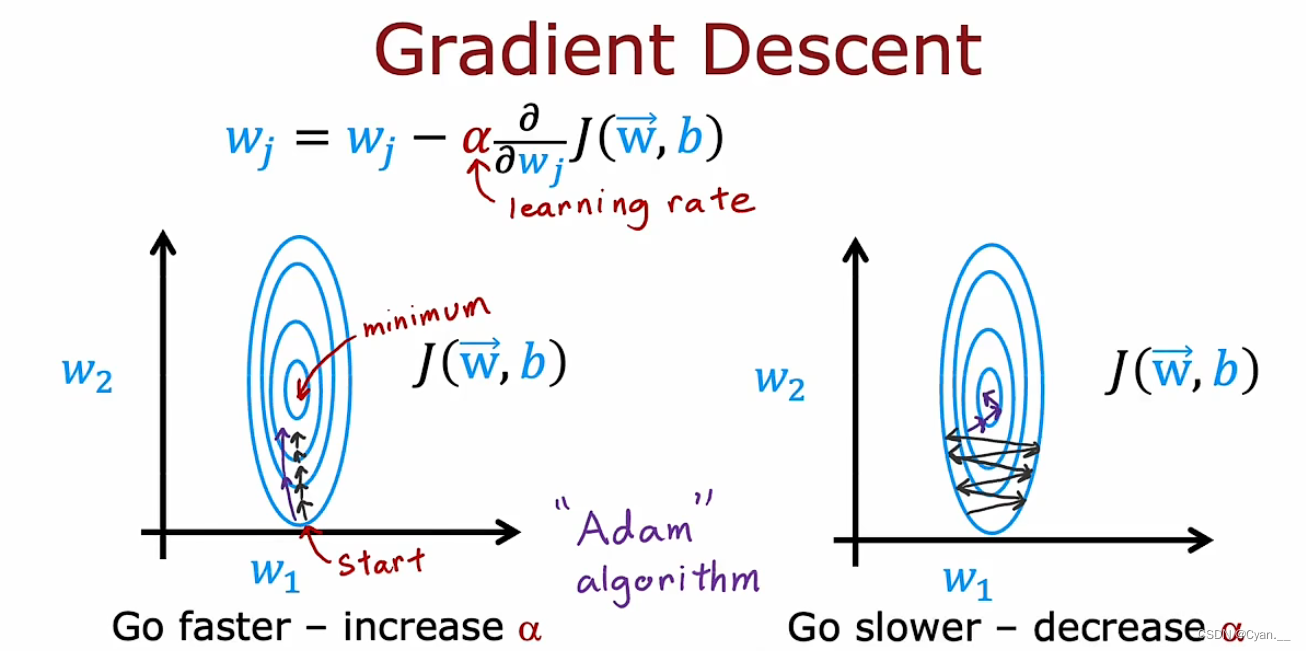
如图所示,等高线表示投射在二维的多参数损失函数图,学习率低的时候,参数更新幅度小,到最低点的速度慢;学习率高的时候,参数更新幅度大,损失函数左右摇摆。
2. 实现原理
Adam算法通过不使用全局学习率而是对每个参数使用针对每个参数的学习率

· 情况①:若参数 或者
似乎沿着大致相同的变化方向移动(一直增或减),则增加学习率;
· 情况②:若参数 或者
来回不断振荡,有时增加有时减少,则减小学习率;
※具体的实现原理不再详述
代码实现:
· 和大多数优化算法一样,仅需在模型实现的函数中调用库中已有的Adam算法进行梯度下降即可
· 在Adam算法中,仍然需要预先设定好全局学习率 a 的值
















 3727
3727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









