







一、定义与区别
监督学习(Supervised learning) :
提供带有正确结果的训练集,基于训练集,算法将归纳(generalization)出“如何正确的响应所有可能的输入”,也就是对测试集有一个明确的输出。也称之为”示例学习(learning from examples)”
非监督学习(Unsupervised learning):
训练集没有提供正确结果,而是让算法尝试识别不同数据之间的相似性,从而让有共同特征的数据能够被归类在一起。以统计学的方式实现监督学习也称作”密度估计(density estimation)“
二、监督学习
模型训练原理:输入(X) —> 输出(Y)
※ 通过X和Y对标签来训练模型,模型从这些输入输出学习后,可接受一个全新的X并尝试对应输出
应用领域举例:
1. 垃圾邮件过滤:电子邮件 —> 垃圾邮件?(0/1)
2. 语音识别:声音 —> 文字记录
3. 机器翻译:英语 —> 中文
4. 外观检验:手机图片 —> 缺陷?(0/1)
5. ……
回归模型:
例:根据房子大小预测房价的AI模型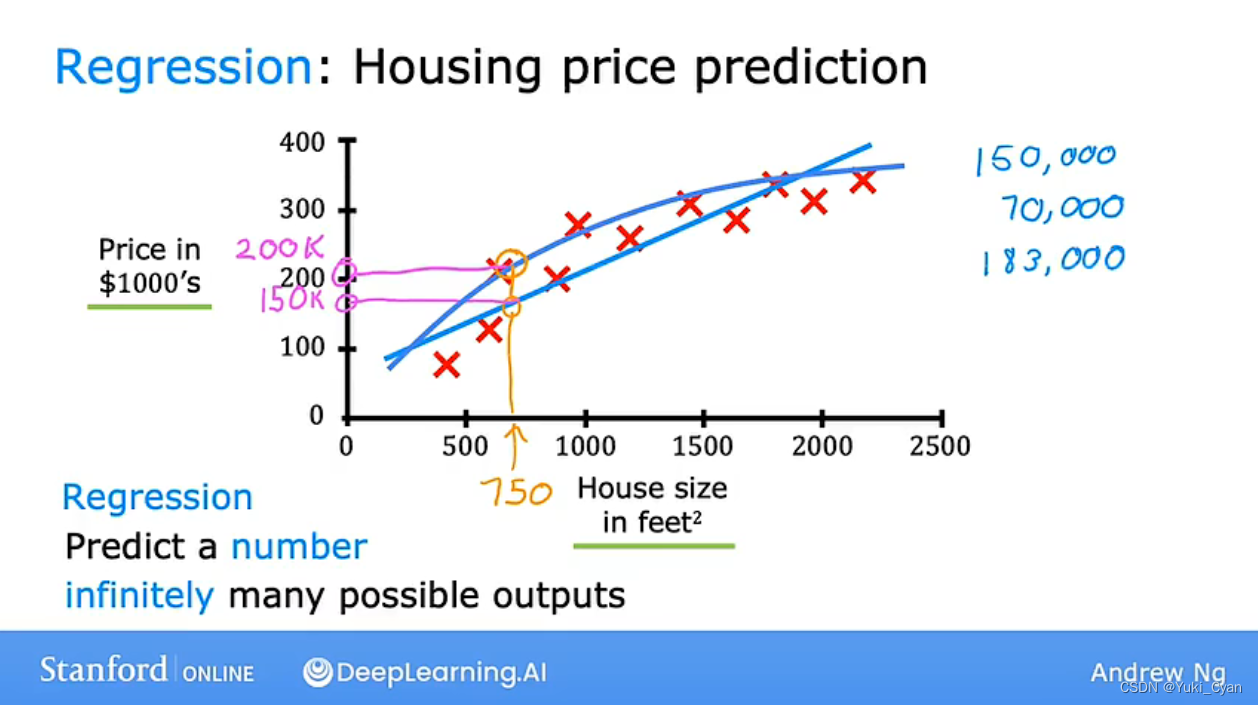
——通过直线拟合、曲线拟合或函数拟合等,对预计的输入X(房子大小)做对应的输出Y(房子价格)的预测
分类模型:
预测事物所属的类别:如肿瘤是良性或恶性;图片显示的是猫还是狗等
例:预测肿瘤是良性或是恶性
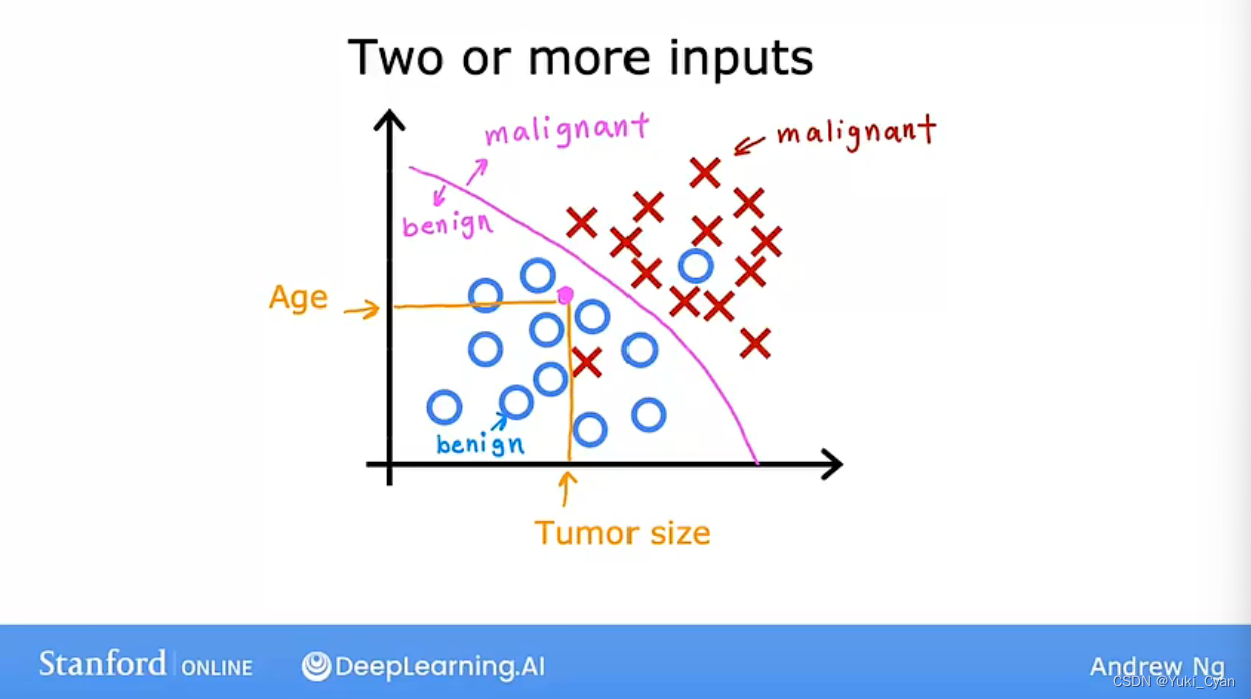
——输入病人年龄与肿瘤大小、厚度等输入值,通过恰当的算法找到一条合理的分界线来对恶性与良性所属的区域进行区分,再用大量数据对模型进行训练,最终使模型获得根据这些输入得出预测结果的能力。
常见的监督学习算法: k-近临算法,决策树,朴素贝叶斯等等。
三、非监督学习
※ 不试图监督算法:让模型自己读懂输入与输出对应的模式与关联,获取没有标签的数据并尝试将它们自动分组到集群之中。
聚类模型:
例:根据DNA表达性状对不同人群进行区分与聚类
并没有提前指明有哪些种类、不同群体有哪些特征——即没有事先让机器明白所应该做的聚类类型、目标有哪些。而最终为产出聚类结果所运用的归类方式是模型自己探寻出来的。

——红色、灰色、绿色代表不同性状表达能力的强弱,机器根据这些颜色所反映出群体能力的不同来对整个人群的DNA序列做了聚类。
非监督学习的其它模型:异常检测模型、降维等等
常见的非监督学习算法: k-均值聚类算法,谱聚类算法,EM算法,主成分分析。
例题:选择无监督学习的示例:

我的答案:BC
B:使用聚类的模型算法将新闻文章分组到一起。
C:给予算法一些数据让模型自动发现并细分市场,对其进行进一步的归类。
四、半监督学习
※ 训练数据集同时包含有标记样本数据和未标记样本数据。
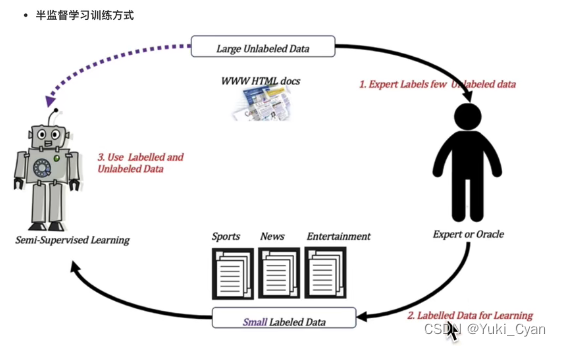
原理:用一小部分标记好的数据先进行初步的模型训练,再投入大量未标记数据来获得整体的模型结果。
总结:
监督学习、非监督学习、半监督学习是机器学习的主要算法分支。后续还会学到强化学习,日后在系统地对机器学习的相关算法进行学习、实践的过程中,也应当对这几个算法分支的概念、区别等铭记于心。















 12
12











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









