






Read + Verify: Machine Reading Comprehension with Unanswerable Questions (AAAI 2019)
| 动机: | SQuAD数据集中包括无答案问题。 1. 以前的工作尝试在预测答案跨度概率之外,还额外预测一个无答案概率,并且在这两项概率之间进行共享归一化操作。这种共享归一化操作会引起概率互相干扰的问题会最终影响无答案检测的精度,导致模型针对无答案问题的检测精度下降。 |
| 贡献: | 作者提出read+verify 模型,旨在提高系统对于无答案问题的鲁棒性。其贡献在于:
|
| 模型: | 1.无答案阅读器(之前的工作)。(1) 利用注意力机制,为问题和段落建立相互感知的隐层表示, (2) 利用指针网络预测答案开始和结束位置: (3) 检测问题有答案的概率; 基于
最终优化一个联合训练函数:
2. 两个辅助损失函数(1) 无论问题是否有答案,对所有问题抽取候选答案;并用额外的指针网络产生另一对答案跨度分数; 通过该损失函数,可以期望模型在不考虑无答案检测的情况下专注于最大化候选答案跨度的概率,从而增强答案抽取精度。 (2) 需要根据问题判断段落中是否存在答案,而不用顾及如何抽取候选答案。
(3)合并上述损失函数:
3. 答案验证器(1) 序列架构: 将答案句子(包含答案或者似是而非的答案所在的句子) 将该嵌入表述输入到k个transformer块中进行编码 最后一层隐藏状态的最后一位词表示 一个标准的交叉熵损失函数被用于最小化负的对数概率:
(2) 交互架构 过于复杂,略 (3) 混合架构 结合序列架构和交互架构,组成混合架构 |
| IDEA: | 1.在验证答案阶段,如果答案文本与问题文本相矛盾,需要重新学习。即,答案验证器缺少反馈 |
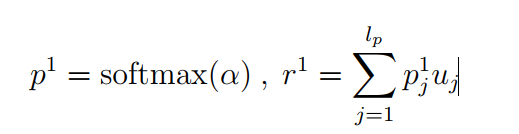 ,同理得到
,同理得到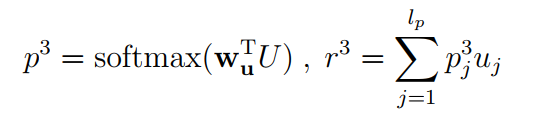
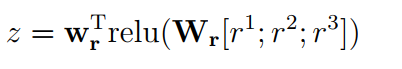
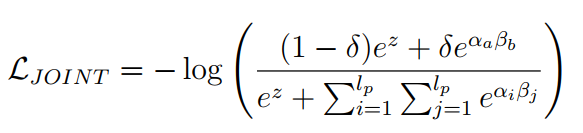
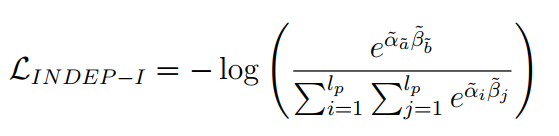
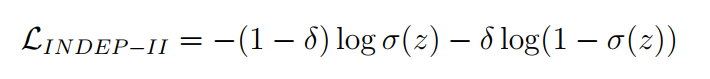
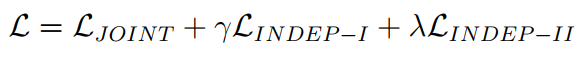
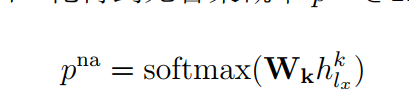
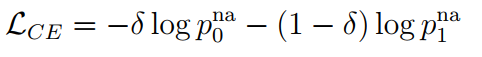















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









