






#include <stdio.h>
#include <malloc.h>
#define TOTAL_SPACE 5
typedef struct CircleIntQueue{
int data[TOTAL_SPACE];
int front;
int rear;
}*CircleIntQueuePtr;
//初始化队列
CircleIntQueuePtr initQueue() {
CircleIntQueuePtr resultPtr = (CircleIntQueuePtr)malloc(sizeof(struct CircleIntQueue));
resultPtr->front = 0;
resultPtr->rear = 0;
return resultPtr;
}
//入列
void enqueue(CircleIntQueuePtr paraPtr, int paraValue) {
printf("Enqueue: %d ", paraValue);
if ((paraPtr->rear + 1) % TOTAL_SPACE == paraPtr->front) {
printf("Queue full.\r\n");
return;
}
paraPtr->data[paraPtr->rear] = paraValue;
paraPtr->rear = (paraPtr->rear + 1) % TOTAL_SPACE;
}
//出列
int dequeue(CircleIntQueuePtr paraPtr) {
int resultValue;
if (paraPtr->front == paraPtr->rear) {
printf("No element in the queue.\r\n");
return -1;
}
resultValue = paraPtr->data[paraPtr->front];
paraPtr->front = (paraPtr->front + 1) % TOTAL_SPACE;
return resultValue;
}
//输出队列
void outputCircleIntQueue(CircleIntQueuePtr paraPtr){
int i;
if (paraPtr->front == paraPtr->rear) {
printf("Empty queue.");
return;
}
printf("Elements in the queue: ");
for (i = paraPtr->front; i != paraPtr->rear; i = (i + 1) % TOTAL_SPACE) {
printf("data[%d] = %d, ", i, paraPtr->data[i]);
}
printf("\r\n");
}
//测试
void testCircleIntQueue(){
int i = 10;
CircleIntQueuePtr tempPtr = initQueue();
for (; i < 16; i ++) {
enqueue(tempPtr, i);
}
outputCircleIntQueue(tempPtr);
for (i = 0; i < 6; i ++) {
printf("dequeue gets %d\r\n", dequeue(tempPtr));
}
for (i = 3; i < 6; i ++) {
enqueue(tempPtr, i);
}
for (i = 20; i < 30; i ++) {
enqueue(tempPtr, i);
printf("dequeue gets %d\r\n", dequeue(tempPtr));
outputCircleIntQueue(tempPtr);
}
}
int main(){
testCircleIntQueue();
return 1;
}
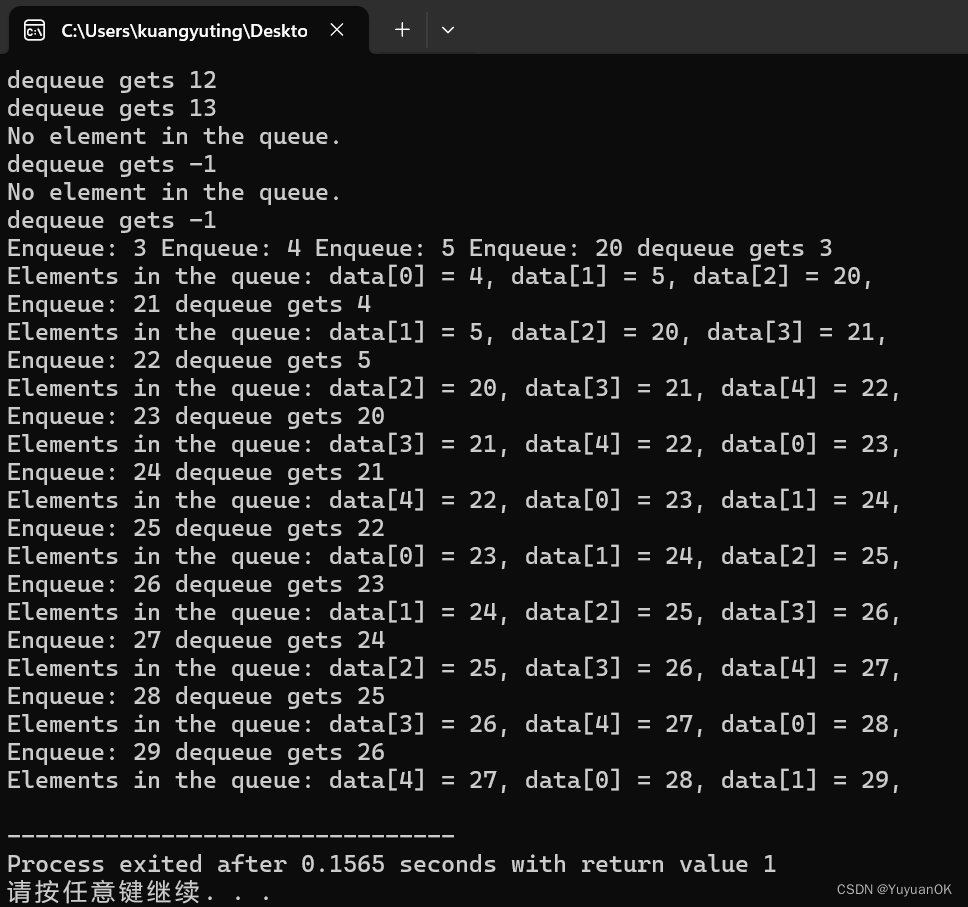
运行结果
心得体会
编写循环队列代码的心得体会可以涉及多个方面,从理解概念到实际编程实现,再到对代码性能和设计的考量。以下是我基于这些方面的一些心得体会:
- 理解循环队列的概念:在开始编写代码之前,对循环队列的基本原理有清晰的理解是非常重要的。循环队列是一种线性数据结构,其操作表现基于FIFO(先进先出)原则并且队尾被连接在队首以形成一个循环。这种结构能够有效地利用存储空间,避免了传统队列中可能出现的空间浪费。
- 确定数据结构:循环队列通常需要一个数组(或动态数组)来存储元素,以及两个指针(如
front和rear)来追踪队列的头部和尾部。确定这些数据结构的大小和类型对于代码的正确性和效率至关重要。 - 处理边界条件:在编写入队(enqueue)和出队(dequeue)操作时,处理边界条件是一个挑战。例如,当队列为空时入队和出队应该如何处理?当队列满时如何有效地添加新元素?这些都需要通过仔细的逻辑判断来实现。
- 考虑线程安全:如果循环队列在多线程环境中使用,那么线程安全性就是一个重要的问题。这可能需要使用锁或其他同步机制来确保对队列的并发访问不会导致数据不一致或其他问题。
- 优化性能:优化循环队列的性能可能涉及多个方面,如减少不必要的内存分配、减少CPU密集型操作等。例如,通过避免在每次入队和出队操作中都重新计算队列的大小,可以显著提高性能。
- 编写清晰可读的代码:编写易于理解和维护的代码同样重要。这意味着应该使用有意义的变量名、添加注释以解释复杂的逻辑,并确保代码结构清晰明了。
- 测试和调试:编写完代码后,进行充分的测试和调试是必不可少的。这有助于发现潜在的错误和边界条件问题,并确保代码在各种情况下都能正常工作。
- 学习和反思:编写循环队列代码是一个学习和反思的过程。通过实践,可以加深对数据结构和算法的理解,并发现自己在编程和设计方面的不足。这些经验可以用于改进未来的工作。















 1421
1421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









