






代码
#include <stdio.h>
#include <malloc.h>
#include <stdbool.h>
#define QUEUE_SIZE 10
int* visitedPtr;
// 具有多个索引的队列
typedef struct GraphNodeQueue{
int* nodes;
int front;
int rear;
}GraphNodeQueue, *QueuePtr;
// 初始化队列
QueuePtr initQueue(){
QueuePtr resultQueuePtr = (QueuePtr)malloc(sizeof(struct GraphNodeQueue));
resultQueuePtr->nodes = (int*)malloc(QUEUE_SIZE * sizeof(int));
resultQueuePtr->front = 0;
resultQueuePtr->rear = 1;
return resultQueuePtr;
}
// 队列是否为空
bool isQueueEmpty(QueuePtr paraQueuePtr){
if ((paraQueuePtr->front + 1) % QUEUE_SIZE == paraQueuePtr->rear) {
return true;
}
return false;
}
// 增加一个结点
void enqueue(QueuePtr paraQueuePtr, int paraNode){
//printf("front = %d, rear = %d.\r\n", paraQueuePtr->front, paraQueuePtr->rear);
if ((paraQueuePtr->rear + 1) % QUEUE_SIZE == paraQueuePtr->front % QUEUE_SIZE) {
printf("Error, trying to enqueue %d. queue full.\r\n", paraNode);
return;
}
paraQueuePtr->nodes[paraQueuePtr->rear] = paraNode;
paraQueuePtr->rear = (paraQueuePtr->rear + 1) % QUEUE_SIZE;
//printf("enqueue %d ends.\r\n", paraNode);
}
//从队列中删除一个元素并返回
int dequeue(QueuePtr paraQueuePtr){
if (isQueueEmpty(paraQueuePtr)) {
printf("Error, empty queue\r\n");
return -1;
}
paraQueuePtr->front = (paraQueuePtr->front + 1) % QUEUE_SIZE;
//printf("dequeue %d ends.\r\n", paraQueuePtr->nodes[paraQueuePtr->front]);
return paraQueuePtr->nodes[paraQueuePtr->front];
}
// 图的结构
typedef struct Graph{
int** connections;
int numNodes;
} *GraphPtr;
GraphPtr initGraph(int paraSize, int** paraData) {
int i, j;
GraphPtr resultPtr = (GraphPtr)malloc(sizeof(struct Graph));
resultPtr -> numNodes = paraSize;
//resultPtr -> connections = (int**)malloc(paraSize * paraSize * sizeof(int));
resultPtr -> connections = (int**)malloc(paraSize * sizeof(int*));
for (i = 0; i < paraSize; i ++) {
resultPtr -> connections[i] = (int*)malloc(paraSize * sizeof(int));
for (j = 0; j < paraSize; j ++) {
resultPtr -> connections[i][j] = paraData[i][j];
}
}
return resultPtr;
}
//初始化
void initTranverse(GraphPtr paraGraphPtr) {
int i;
//初始化数据
visitedPtr = (int*) malloc(paraGraphPtr -> numNodes * sizeof(int));
for (i = 0; i < paraGraphPtr -> numNodes; i ++) {
visitedPtr[i] = 0;
}
}
// 深度优先转换
void depthFirstTranverse(GraphPtr paraGraphPtr, int paraNode) {
int i;
visitedPtr[paraNode] = 1;
printf("%d\t", paraNode);
for (i = 0; i < paraGraphPtr -> numNodes; i ++) {
if (!visitedPtr[i]){
if (paraGraphPtr -> connections[paraNode][i]) {
depthFirstTranverse(paraGraphPtr, i);
}
}
}
}
// 宽度平移
void widthFirstTranverse(GraphPtr paraGraphPtr, int paraStart){
// 使用队列管理指针
int i, j, tempNode;
i = 0;
QueuePtr tempQueuePtr = initQueue();
printf("%d\t", paraStart);
visitedPtr[paraStart] = 1;
enqueue(tempQueuePtr, paraStart);
while (!isQueueEmpty(tempQueuePtr)) {
tempNode = dequeue(tempQueuePtr);
visitedPtr[tempNode] = 1;
i ++;
for (j = 0; j < paraGraphPtr->numNodes; j ++) {
if (visitedPtr[j])
continue;
if (paraGraphPtr->connections[tempNode][j] == 0)
continue;
printf("%d\t", j);
visitedPtr[j] = 1;
enqueue(tempQueuePtr, j);
}
}
}
void testGraphTranverse() {
int i, j;
int myGraph[5][5] = {
{0, 1, 0, 1, 0},
{1, 0, 1, 0, 1},
{0, 1, 0, 1, 1},
{1, 0, 1, 0, 0},
{0, 1, 1, 0, 0}};
int** tempPtr;
printf("Preparing data\r\n");
tempPtr = (int**)malloc(5 * sizeof(int*));
for (i = 0; i < 5; i ++) {
tempPtr[i] = (int*)malloc(5 * sizeof(int));
}
for (i = 0; i < 5; i ++) {
for (j = 0; j < 5; j ++) {
tempPtr[i][j] = myGraph[i][j];
}
}
printf("Data ready\r\n");
GraphPtr tempGraphPtr = initGraph(5, tempPtr);
printf("num nodes = %d \r\n", tempGraphPtr -> numNodes);
printf("Graph initialized\r\n");
printf("Depth first visit:\r\n");
initTranverse(tempGraphPtr);
depthFirstTranverse(tempGraphPtr, 4);
printf("\r\nWidth first visit:\r\n");
initTranverse(tempGraphPtr);
widthFirstTranverse(tempGraphPtr, 4);
}
int main(){
testGraphTranverse();
return 1;
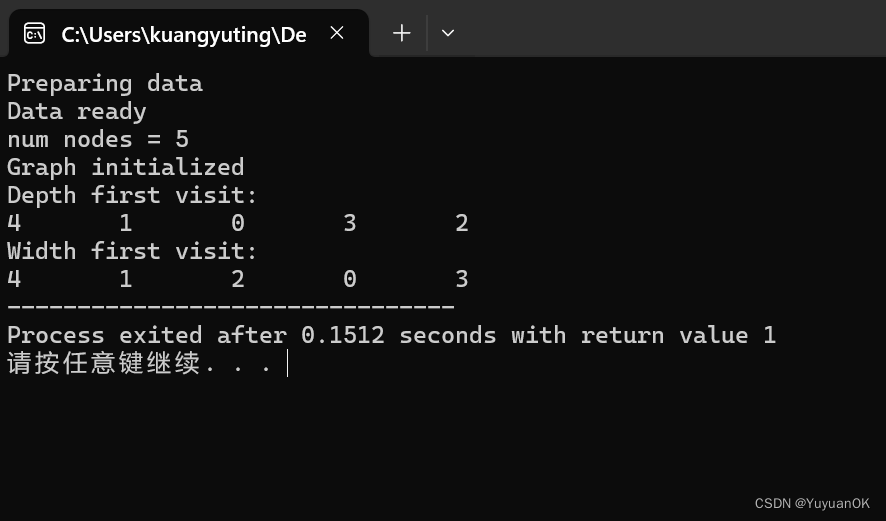
}运行结果
心得体会
编写图的遍历代码的心得体会涉及对图数据结构及其遍历算法的理解、实现细节以及性能优化的考虑。以下是我从这一过程中获得的一些心得体会:
-
理解图的数据结构:
图是由顶点和边组成的数据结构,可以是有向的也可以是无向的。在编写遍历代码之前,需要明确图的表示方式,如邻接矩阵、邻接表等,并理解它们各自的优缺点。选择合适的表示方式对于编写高效且易读的代码至关重要。 -
遍历算法的选择:
图的遍历算法有多种,如深度优先搜索(DFS)和广度优先搜索(BFS)。DFS 通常使用栈来辅助实现,而 BFS 使用队列。在选择遍历算法时,需要根据问题的具体需求来确定。例如,如果需要找到从起点到终点的最短路径,那么 BFS 可能是更好的选择。 -
实现细节:
在实现遍历算法时,需要注意一些细节问题。例如,在 DFS 中,需要避免重复访问已经访问过的顶点,这可以通过使用一个集合或布尔数组来记录已访问状态。在 BFS 中,需要注意队列的入队和出队操作,确保按照正确的顺序访问顶点。 -
性能优化:
图的遍历算法的性能与图的表示方式、顶点和边的数量以及实现细节密切相关。例如,使用邻接表表示稀疏图通常比使用邻接矩阵更高效,因为邻接表只存储了实际存在的边。此外,在实现遍历算法时,可以通过减少不必要的计算和内存访问来优化性能。 -
处理特殊情况:
在编写图的遍历代码时,需要特别注意处理一些特殊情况。例如,当图中存在环时,DFS 可能会陷入无限循环;当图不连通时,BFS 可能无法访问到所有顶点。为了避免这些问题,需要在代码中添加相应的判断和处理逻辑。 -
代码的可读性和可维护性:
与编写其他类型的代码一样,编写图的遍历代码时也需要注重代码的可读性和可维护性。使用有意义的变量名、函数名和注释可以提高代码的可读性;遵循良好的编程规范、模块化和封装可以提高代码的可维护性















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









