







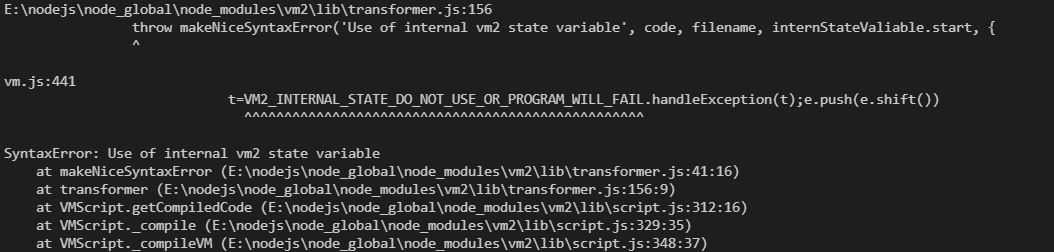
在补环境框架的文件夹里执行 vm2 文件能成功得到结果,但是将合并了环境和原 js 文件后的代码内容单独提取出来通过 vm2 调用却报错提示 SyntaxError: Use of internal vm2 state variable:
通过 transformer.js 源码,分析 VM2_INTERNAL_STATE_DO_NOT_USE_OR_PROGRAM_WILL_FAIL 和 makeNiceSyntaxError 都是什么:
const {Parser: AcornParser, isNewLine: acornIsNewLine, getLineInfo: acornGetLineInfo} = require('acorn');
const {full: acornWalkFull} = require('acorn-walk');
const INTERNAL_STATE_NAME = 'VM2_INTERNAL_STATE_DO_NOT_USE_OR_PROGRAM_WILL_FAIL';该 js 文件的前两行引入了 acorn 和 acorn-walk,acorn 是一个小而快 JavaScript 解析器,熟知的还有 babel 和 eslint 等等,acorn-walk 包提供了遍历的能力,以下为 acorn 解析示例:
AST 相关可阅读:【JavaScript 逆向】AST 技术反混淆
console.log('Yy_Rose')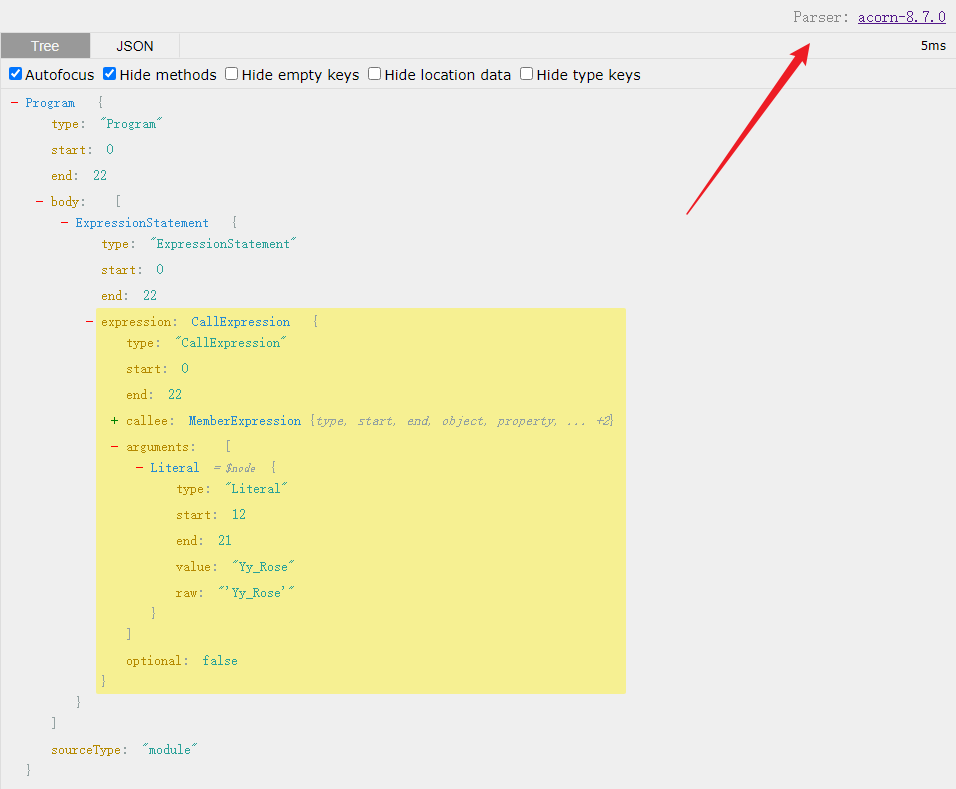
由上面代码可知 VM2_INTERNAL_STATE_DO_NOT_USE_OR_PROGRAM_WILL_FAIL 是一个字符串对象,赋值给了 INTERNAL_STATE_NAME,再看看 INTERNAL_STATE_NAME 在哪被调用了,搜索后总共有七个地方,与报错提示相关的在第 122 行,内容如下:
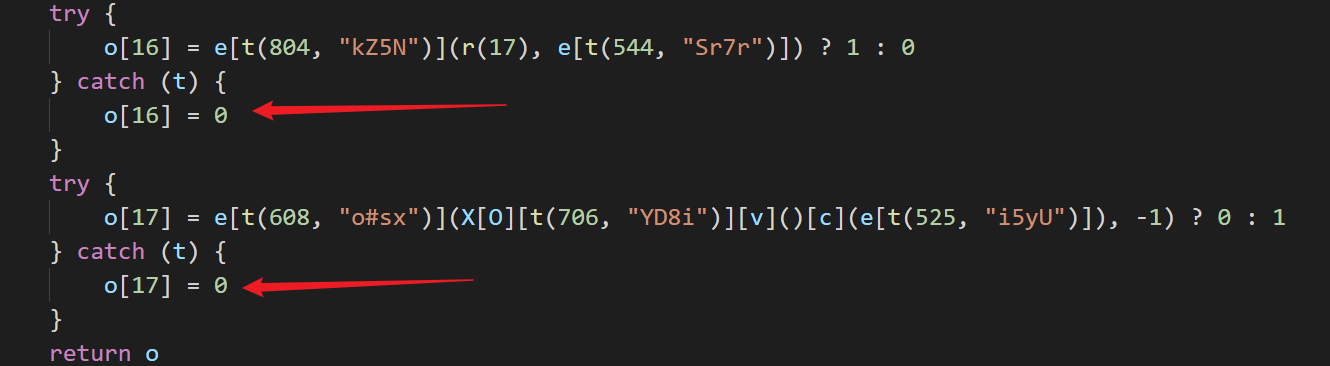
code: `${name}=${INTERNAL_STATE_NAME}.handleException(${name});`先来看看初始扣下来的 js 文件中以下位置的代码内容:
然后再看看通过 vm2 合并环境后的 js 文件的 try catch 处,可以看出 VMScript 编译时自动添加了语句:
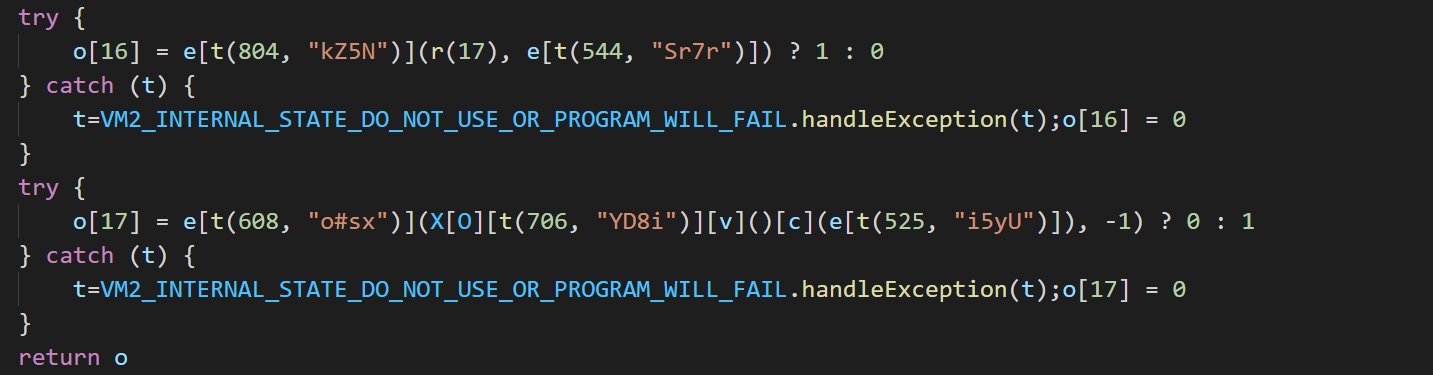
所以需要分析这部分代码的含义,是什么导致添加了这部分代码,且有什么用,代码如下:
acornWalkFull(ast, (node, state, type) => {
if (type === 'Function') {
if (node.async) hasAsync = true;
}
const nodeType = node.type;
if (nodeType === 'CatchClause') {
const param = node.param;
if (param) {
const name = assertType(param, 'Identifier').name;
const cBody = assertType(node.body, 'BlockStatement');
if (cBody.body.length > 0) {
insertions.push({
__proto__: null,
pos: cBody.body[0].start,
order: TO_LEFT,
code: `${name}=${INTERNAL_STATE_NAME}.handleException(${name});`
});
}
}
} else if (nodeType === 'WithStatement') {...
} else if (nodeType === 'Identifier') {...
} else if (nodeType === 'ImportExpression') {...
}
...
...
});- acornWalkFull 是引用的 acorn-walk 包
- ast:前面通过 acorn 的解析器 Parser 将 JavaScript 代码转换为了成了 AST(抽象语法树)
- Identifier:标识符,指变量名称
- BlockStatement:代码块语句,表示一些控制语句或特殊语句
- catchClause:构造一个自定义的 catch 子句节点,作为 try 异常处理块的内容,param 用以表示 catch 后的参数,body 则表示 catch 后的执行语句,通常是一个块语句
interface CatchClause <: Node {
type: "CatchClause";
param: Pattern;
body: BlockStatement;
}assertType 函数返回 node 节点,若节点为无效类型则抛出异常,类型断言:
function assertType(node, type) {
if (!node) throw new Error(`None existent node expected '${type}'`);
if (node.type !== type) throw new Error(`Invalid node type '${node.type}' expected '${type}'`);
return node;
}这里先判断 name 是否为 Identifier,获取了 catch 括号中的变量名称,然后判断 cBody 是否为 BlockStatement 代码块语句,这里为 try{}catch(){},insertions 为空数组,这里大底就是遍历了函数节点,当节点类型为 catchClause 时,在 try...catch... 代码块的 catch 部分开头添加了指定的内容,通过 handleException 处理异常,更改了 catch 处的代码,将整个 try 语句节点作为一个新的函数声明节点的子节点,用新生成的节点替换原有的函数声明节点。
抛出 makeNiceSyntaxError('Use of internal vm2 state variable' 异常处在第 155 行:
let internStateValiable = undefined;
if (internStateValiable) {
throw makeNiceSyntaxError('Use of internal vm2 state variable', code, filename, internStateValiable.start, {
__proto__: null,
start: internStateValiable.start,
end: internStateValiable.end
});
}所以当通过 try 捕捉的参数未定义的时候,则会抛出此类异常及前文提到的 catch 处被更改的内容,INTERNAL_STATE_NAME 被调用,进一步导致报错 SyntaxError: Use of internal vm2 state variable,但是原本 js 文件的 try 处捕捉到异常时则执行 catch 后的内容,从以下可以看到,try 处赋值语句出现异常时,o[17] 被赋值为 0:
try {
o[17] = e[t(608, "o#sx")](X[O][t(706, "YD8i")][v]()[c](e[t(525, "i5yU")]), -1) ? 0 : 1
} catch (t) {
o[17] = 0
}而 catch 处已经添加了 ${name}=${INTERNAL_STATE_NAME}.handleException(${name}); 的 js 文件会直接抛出异常,程序运行结束,所以不能直接将合并后的整个 js 文件内容复制出来使用,只能单独将合并后的环境拿出来,放在原始的 js 文件前面,再通过 vm2 调用执行,即可成功得到结果。















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









