






今天给大家推荐一本大模型神书,就是这本:《大语言模型:基础与前沿》,本书深入阐述了大语言模型的基本概念和算法、研究前沿以及应用,涵盖大语言模型的广泛主题,从基础到前沿,从方法到应用,不仅涵盖了经典的语言模型知识,还重点介绍了最新的研究成果和技术进展。
适宜人群
本书内容全面、系统性强,适合高年级本科生和研究生、博士后研究人员、讲师以及行业从业者阅读与参考。
所有资料 ⚡️ ,朋友们如果有需要 《AI大语言模型的基础与前沿》PDF,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

书籍推荐
本书还涵盖了 LLM 领域的一些前沿进展,包括并行性、稀疏专家混合、检索增强型语言模型,以及根据人类偏好调整语言模型等话题。作者还专门探讨了 LLM 如何帮助减少偏见和有害性,这是人工智能领域一个日益重要的方面。
最后则将注意力转移到视觉语言模型上,探讨了如何将视觉信息与语言模型相结合。探讨了 LLM 对环境的影响,包括能源消耗、温室气体排放等问题,引发人们对于技术发展与可持续发展之间的思考。
总之,那些机械重复、易出错的工作将会被 AI 取代。例如,软件开发将不会是一项高风险的活动,每个人都可以是软件工程师,通过 LLM 开发出稳定可用的软件。其他行业也类似,这就需要我们透彻理解 LLM,找到发轫点,提升效能。
从目前来看,我们的许多工作都在被 LLM 取代,例如文本自动生成、智能客服、数据分析与预测等。这预示着 LLM 将会成为维持人类社会运行的基础设施,比 Devin 更智能的 LLM 还会出现,我们现在要做的就是吃透原理,做到运用之妙,存乎一心。

《大语言模型:基础与前沿》这本书相比市场上同类型书籍,在内容上更具有稀缺性,因为它不仅讲解了当前 LLM 技术的原理与应用,还展望了未来的发展方向,更对其争议也进行了思辨,帮助读者找到技术与现实应用的最佳结合点。
本书最大的特点就是全面性,通过对 LLM 的基础知识、前沿进展和社会影响的解读,为读者提供了系统的认识。同时,本书对 LLM 技术前瞻性的预测,也促使读者思考未来要做出的选择。
对于 LLM 相关的数学原理,书中使用简洁易懂的语言进行描述,作者还精心绘制了大量图表,对一些晦涩的理论和复杂的流程进行形象化的展现。
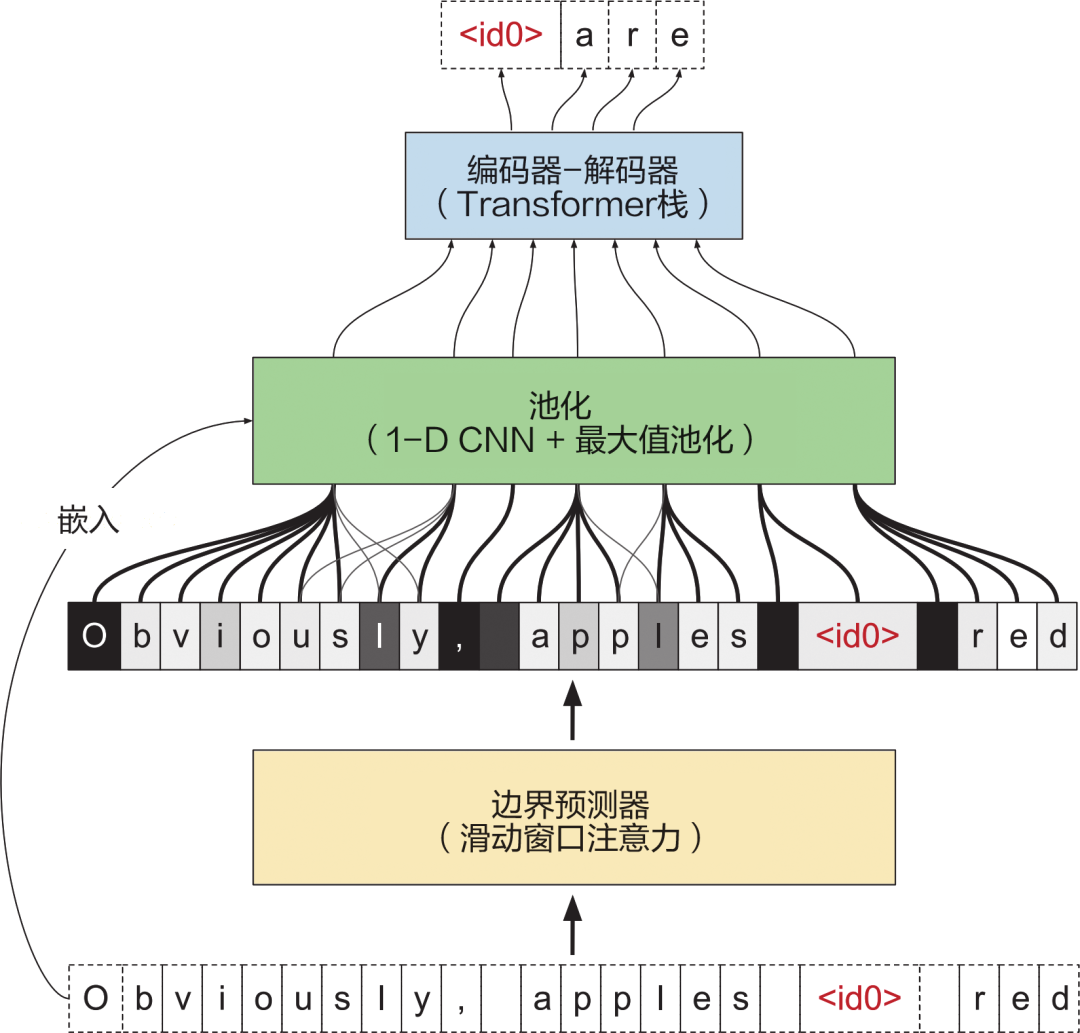
精彩图示
最后,我们来纵览一下本书的知识点,直观体会本书内容的独特性。大家可以就自己感兴趣的方向深入探索。
· 第1章概述了 LLM 的辩论、争议和未来发展方向。
· 第2章讨论了语言模型和分词的基础知识。
· 第3章深入阐释了 Transformer 架构。
· 第4章深入分析了 LLM 的预训练,涉及预训练目标和解码策略。
· 第5章探讨了这些模型的上下文学习和轻量级微调。
· 第6章讨论了扩大尺度法则、涌现能力、并行、混合训练和低精度训练,以实现训练更大的模型。
· 第7章介绍稀疏专家模型的概念,实现该模型的路由算法与其他改进措施。
· 第8章介绍检索增强型语言模型,包括预训练检索增强型语言模型、通过高效和精简检索进行问答和多跳推理、检索增强型 Transformer 等知识点。
· 第9章探讨对齐语言模型与人类偏好,说明了基于人类反馈、基于语言反馈、基于监督学习进行微调的方法。
· 第10章探讨了 LLM 如何帮助减少偏见和有害性,提出了检测与减少偏见及有害性的多种办法。
· 第11章将重点转移到视觉语言模型上,探讨如何将视觉信息整合到语言模型中。
· 第12章阐释了 LLM 对环境的影响,并讨论了能源消耗、温室气体排放等问题。
读完这本书,读者将能够系统地了解 LLM 的理论基础、技术原理以及未来趋势。对于从事自然语言处理、人工智能研究和应用的专业人士来说,定能拨开迷雾,把握住 AI 发展的脉络。
《大语言模型:基础与前沿》不仅深入解读了 LLM 技术本身,还将目光扩展到人类与社会层面,全景式地为我们揭示出 LLM 的应用与发展究竟会怎样改变我们的生活。

本书首先从 LLM 的辩论、争议和未来发展方向入手,引出对这一领域的全面认识。接着,探讨语言模型和分词的基础知识,为读者打下扎实的理论基础。
随后 对 Transformer 架构深入阐释 ,通过对编码器-解码器架构的剖析,以及外部记忆和推理优化的说明,揭示其在 LLM 中的重要性和应用方法。还详细分析了 LLM 的预训练、目标设定以及上下文学习和微调等关键内容。

本书还涵盖了 LLM 领域的一些前沿进展,包括并行性、稀疏专家混合、检索增强型语言模型,以及根据人类偏好调整语言模型等话题。作者还专门探讨了 LLM 如何帮助减少偏见和有害性,这是人工智能领域一个日益重要的方面。
最后则将注意力转移到视觉语言模型上,探讨了如何将视觉信息与语言模型相结合。探讨了 LLM 对环境的影响,包括能源消耗、温室气体排放等问题,引发人们对于技术发展与可持续发展之间的思考。
总之,那些机械重复、易出错的工作将会被 AI 取代。例如,软件开发将不会是一项高风险的活动,每个人都可以是软件工程师,通过 LLM 开发出稳定可用的软件。其他行业也类似,这就需要我们透彻理解 LLM,找到发轫点,提升效能。
2.1 内容简介
全书内容共12章,每章内容简介如下:
-
第1章概述了 LLM 的辩论、争议和未来发展方向。
-
第2章讨论了语言模型和分词的基础知识。
-
第3章深入阐释了 Transformer 架构。
-
第4章深入分析了 LLM 的预训练,涉及预训练目标和解码策略。
-
第5章探讨了这些模型的上下文学习和轻量级微调。
-
第6章讨论了扩大尺度法则、涌现能力、并行、混合训练和低精度训练,以实现训练更大的模型。
-
第7章介绍稀疏专家模型的概念,实现该模型的路由算法与其他改进措施。
-
第8章介绍检索增强型语言模型,包括预训练检索增强型语言模型、通过高效和精简检索进行问答和多跳推理、检索增强型 Transformer 等知识点。
-
第9章探讨对齐语言模型与人类偏好,说明了基于人类反馈、基于语言反馈、基于监督学习进行微调的方法。
-
第10章探讨了 LLM 如何帮助减少偏见和有害性,提出了检测与减少偏见及有害性的多种办法。
-
第11章将重点转移到视觉语言模型上,探讨如何将视觉信息整合到语言模型中。
-
第12章阐释了 LLM 对环境的影响,并讨论了能源消耗、温室气体排放等问题。
2.2 本书作者
- 熊涛:电子与计算机工程博士。曾在多家中美知名高科技公司担任高级管理职位和首席科学家,在人工智能的多个领域,包括大语言模型、图神经网络等从事研发和管理工作多年。
2.3 本书目录
第 1章 大语言模型:辩论、争议与未来发展方向 1
1.1 新时代的曙光 1
1.2 LLM有意识吗 3
1.2.1 理解LLM的层次结构 3
1.2.2 意识是否需要碳基生物学 4
1.2.3 具身化与落地 4
1.2.4 世界模型 7
1.2.5 沟通意图 8
1.2.6 系统性和全面泛化 9
1.3 未来发展方向 10
1.4 小结 13
第 2章 语言模型和分词 15
2.1 语言建模的挑战 16
2.2 统计语言建模 16
2.3 神经语言模型 18
2.4 评估语言模型 19
2.5 分词 19
2.5.1 按空格分割 20
2.5.2 字符分词 21
2.5.3 子词分词 21
2.5.4 无分词器 24
2.5.5 可学习的分词 25
2.6 小结 27
第3章 Transformer 29
3.1 Transformer编码器模块 29
3.2 编码器-解码器架构 31
3.3 位置嵌入 32
3.3.1 绝对位置编码 32
3.3.2 相对位置编码 34
3.4 更长的上下文 38
3.5 外部记忆 42
3.6 更快、更小的Transformer 45
3.6.1 高效注意力 45
3.6.2 条件计算 47
3.6.3 搜索高效Transformer 48
3.6.4 在单个GPU上一天内训练一个语言模型 49
3.7 推理优化 49
3.7.1 推测解码 49
3.7.2 简化Transformer 51
3.7.3 修剪 52
3.7.4 蒸馏 53
3.7.5 混合精度 54
3.7.6 高效扩展Transformer推理 54
3.8 小结 56
第4章 预训练目标和解码策略 57
4.1 模型架构 57
4.2 预训练目标 60
4.3 具有代表性的语言模型 62
4.4 解码策略 67
4.5 小结 72
第5章 上下文学习和轻量级微调 73
5.1 上下文学习 74
5.1.1 示范样本选择 75
5.1.2 样本排序 82
5.1.3 指令生成 82
5.1.4 思维链 84
5.1.5 递归提示 87
5.1.6 为什么ICL有效 90
5.1.7 评估 93
5.2 提示语言模型的校准 94
5.3 轻量级微调 97
5.3.1 基于添加的方法 98
5.3.2 基于规范的方法 100
5.3.3 基于重新参数化的方法 101
5.3.4 混合方法 103
5.4 小结 104
第6章 训练更大的模型 107
6.1 扩大尺度法则 107
6.1.1 预训练Transformer扩大尺度的启示 107
6.1.2 预训练和微调Transformer带来的新启示 110
6.1.3 k比特推理扩大尺度法则 111
6.1.4 挑战与机遇 112
6.2 涌现能力 113
6.3 人工智能加速器 115
6.4 并行 117
6.4.1 数据并行 119
6.4.2 流水线并行 126
6.4.3 张量/模型并行 131
6.4.4 专家混合 133
6.5 混合训练和低精度训练 133
6.5.1 单位缩放 133
6.5.2 FP8与INT8 135
6.6 其他节省内存的设计 136
6.7 小结 137
第7章 稀疏专家模型 139
7.1 为什么采用稀疏专家模型 139
7.2 路由算法 142
7.2.1 每个词元选择top-k个专家 142
7.2.2 每个专家选择top-k个词元 144
7.2.3 全局最优分配 145
7.2.4 随机路由 148
7.2.5 双层路由 149
7.2.6 针对不同预训练领域的不同专家 149
7.3 其他改进措施 152
7.3.1 加快训练速度 152
7.3.2 高效的MoE架构 153
7.3.3 生产规模部署 154
7.3.4 通过稀疏MoE扩展视觉语言模型 154
7.3.5 MoE与集成 155
7.4 小结 156
第8章 检索增强型语言模型 157
8.1 预训练检索增强型语言模型 158
8.2 词元级检索 161
8.3 通过高效和精简检索进行问答和多跳推理 163
8.4 检索增强型Transformer 166
8.5 检索增强型黑盒语言模型 168
8.6 视觉增强语言建模 169
8.7 小结 170
第9章 对齐语言模型与人类偏好 171
9.1 基于人类反馈进行微调 172
9.1.1 基于人类反馈的强化学习 172
9.1.2 KL散度:前向与反向 174
9.1.3 REINFORCE、TRPO和PPO 174
9.1.4 带有KL惩罚的强化学习:贝叶斯推理观点 178
9.1.5 通过分布控制生成进行语言模型对齐 180
9.1.6 通过f散度最小化统一RLHF和GDC方法 182
9.2 基于语言反馈进行微调 183
9.3 基于监督学习进行微调 184
9.4 基于人工智能反馈的强化学习 185
9.5 基于自我反馈进行迭代优化 188
9.6 基于人类偏好进行预训练 190
9.7 小结 193
第 10章 减少偏见和有害性 195
10.1 偏见 196
10.2 有害性 199
10.3 偏见和有害性的检测与减少 200
10.3.1 基于解码的策略 201
10.3.2 基于提示的脱毒 202
10.3.3 基于数据的策略 204
10.3.4 基于投影和正则化的方法 205
10.3.5 基于风格转换的方法 205
10.3.6 基于强化学习的微调和基于人类偏好的预训练 206
10.4 小结 206
第 11章 视觉语言模型 207
11.1 语言处理的多模态落地 207
11.2 不需要额外训练即可利用预训练模型 208
11.2.1 视觉引导解码策略 208
11.2.2 作为大语言模型提示的视觉输入 209
11.2.3 基于相似性搜索的多模态对齐 212
11.3 轻量级适配 213
11.3.1 锁定图像调优 213
11.3.2 作为(冻结)语言模型前缀的学习视觉嵌入 214
11.3.3 视觉-文本交叉注意力融合 216
11.4 图文联合训练 219
11.5 检索增强视觉语言模型 222
11.6 视觉指令调整 225
11.7 小结 227
第 12章 环境影响 229
12.1 能源消耗和温室气体排放 229
12.2 估算训练模型的排放量 230
12.3 小结 231
参考文献 232
所有资料 ⚡️ ,朋友们如果有需要 《AI大语言模型的基础与前沿》PDF,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}