






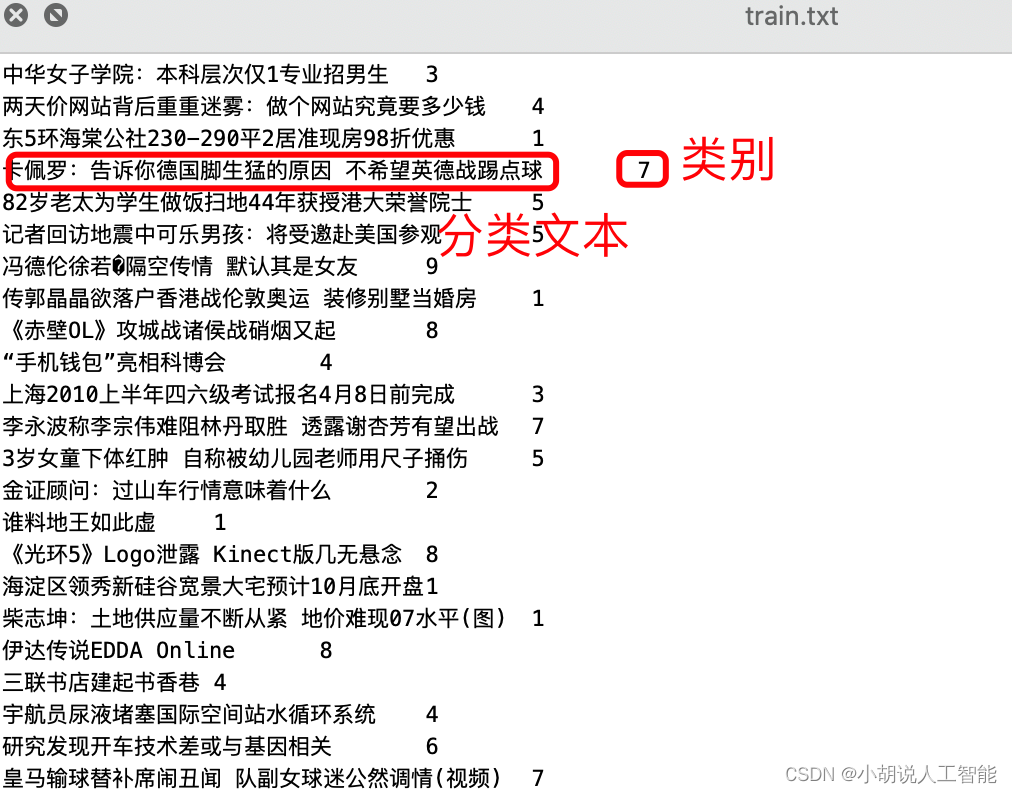
中文数据集
我从THUCNews中抽取了20万条新闻标题,已上传至github,文本长度在20到30之间。一共10个类别,每类2万条。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集划分:
| 数据集 | 数据量 |
|---|---|
| 训练集 | 18万 |
| 验证集 | 1万 |
| 测试集 | 1万 |
更换自己的数据集
-
如果用字,按照我数据集的格式来格式化你的数据。
-
如果用词,提前分好词,词之间用空格隔开,
python run.py --model TextCNN --word True -
使用预训练词向量:utils.py的main函数可以提取词表对应的预训练词向量。
数据集、词表及对应的预训练词向量,已经打包好,详见THUCNews文件夹。

效果
完整项目和数据集代码获取地址:
关注微信公众号 datayx 然后回复 NLP实战 即可获取。
Python环境及安装相应依赖包
-
python 3.7以上
-
pytorch 1.1 以上
-
tqdm
-
sklearn
-
tensorboardX
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

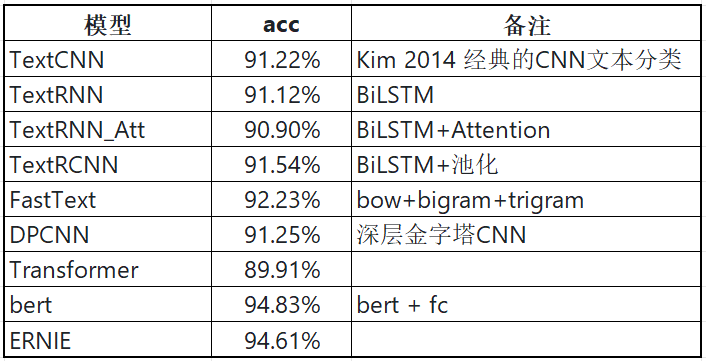
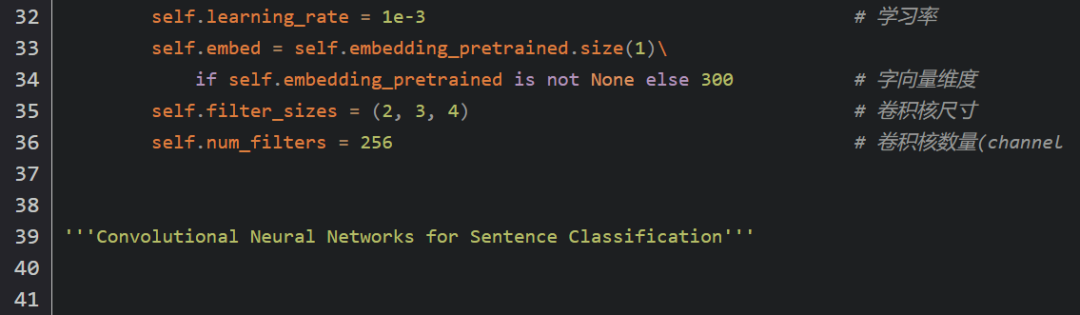
TextCNN
模型说明

分析:
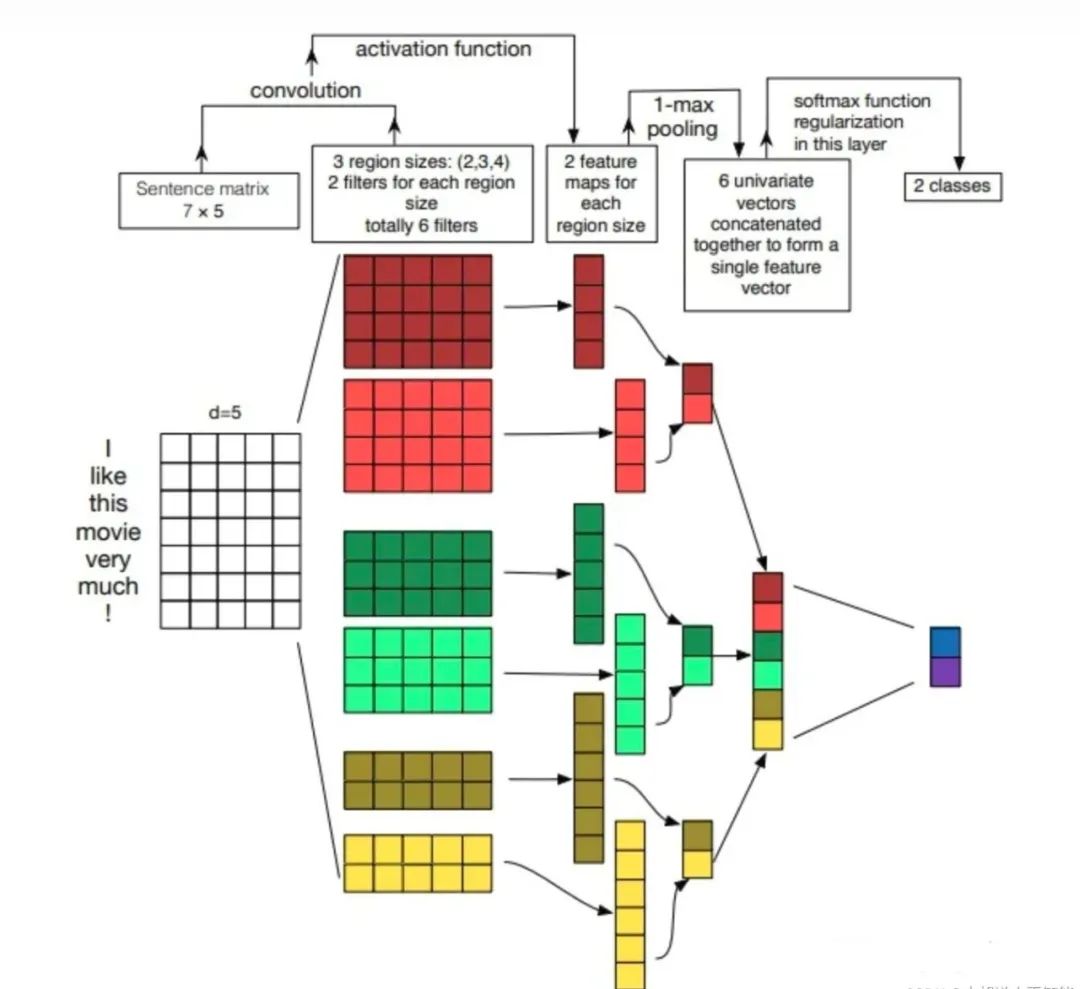
卷积操作相当于提取了句中的2-gram,3-gram,4-gram信息,多个卷积是为了提取多种特征,最大池化将提取到最重要的信息保留。
原理图如下:

终端运行下面命令,进行训练和测试:

训练过程如下:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
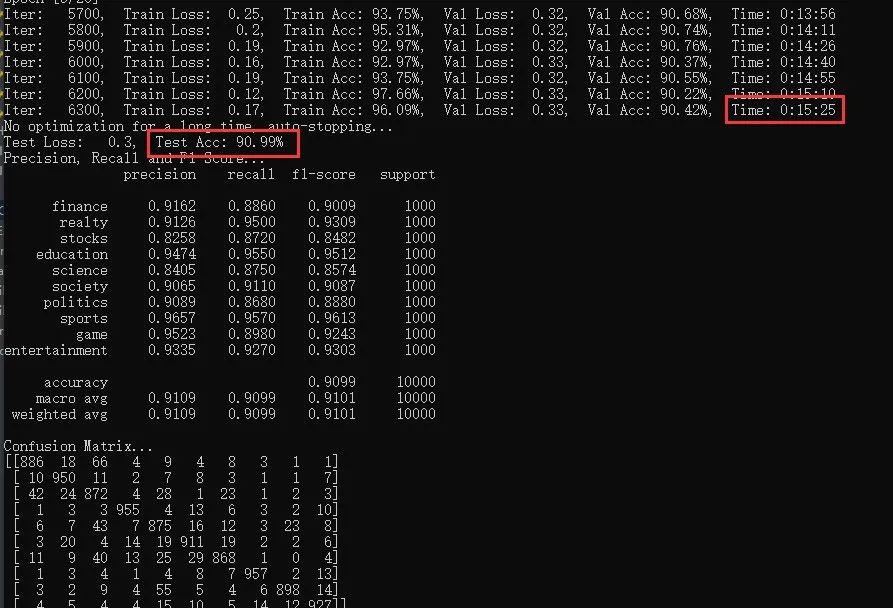
训练及测试结果如下:使用CPU版本pytorch,耗时15分25秒,准确率90.99%
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}