






从2022年底ChatGPT发布以来,人工智能迅速在全社会火爆,ChatGPT背后的一个重要的技术进步就是Transformer架构,这个架构是当下大模型的核心技术支撑,所以要理解当下大模型技术及其未来的发展,彻底理解Transformer至关重要。
那么Transformer到底是什么?
本质上讲:Transformer是一种基于自注意力机制的深度神经网络模型。
Transformer是由Google公司于2017年在论文“Attention is All You Need”中提出的网络架构。该架构最初的设计目的是解决RNN(Recurrent Neural Network,循环神经网络)串行输入、串行编解码导致的运行速度缓慢的问题,以显著提升机器翻译的效率。
Transformer能成功的关键是什么?
通过注意力机制将序列中任意两个位置之间的距离缩小为常量,摒弃类似循环神经网络的顺序结构——关键中的关键是引入注意力机制。
而循环神经网络(RNN)模型只能从左至右(或从右至左)依次计算,不利于并行计算,并且容易产生梯度爆炸和梯度消失问题。Transformer模型能够在处理序列数据时关注到序列中不同位置的信息,实现更加高效的并行处理。
本篇我们先看Transformer的整体架构,再看其关键技术“自注意力机制”。


Transformer的整体架构
Transformer的整体结构可分为输入模块、编码器模块、解码器模块和输出模块,如下图所示:
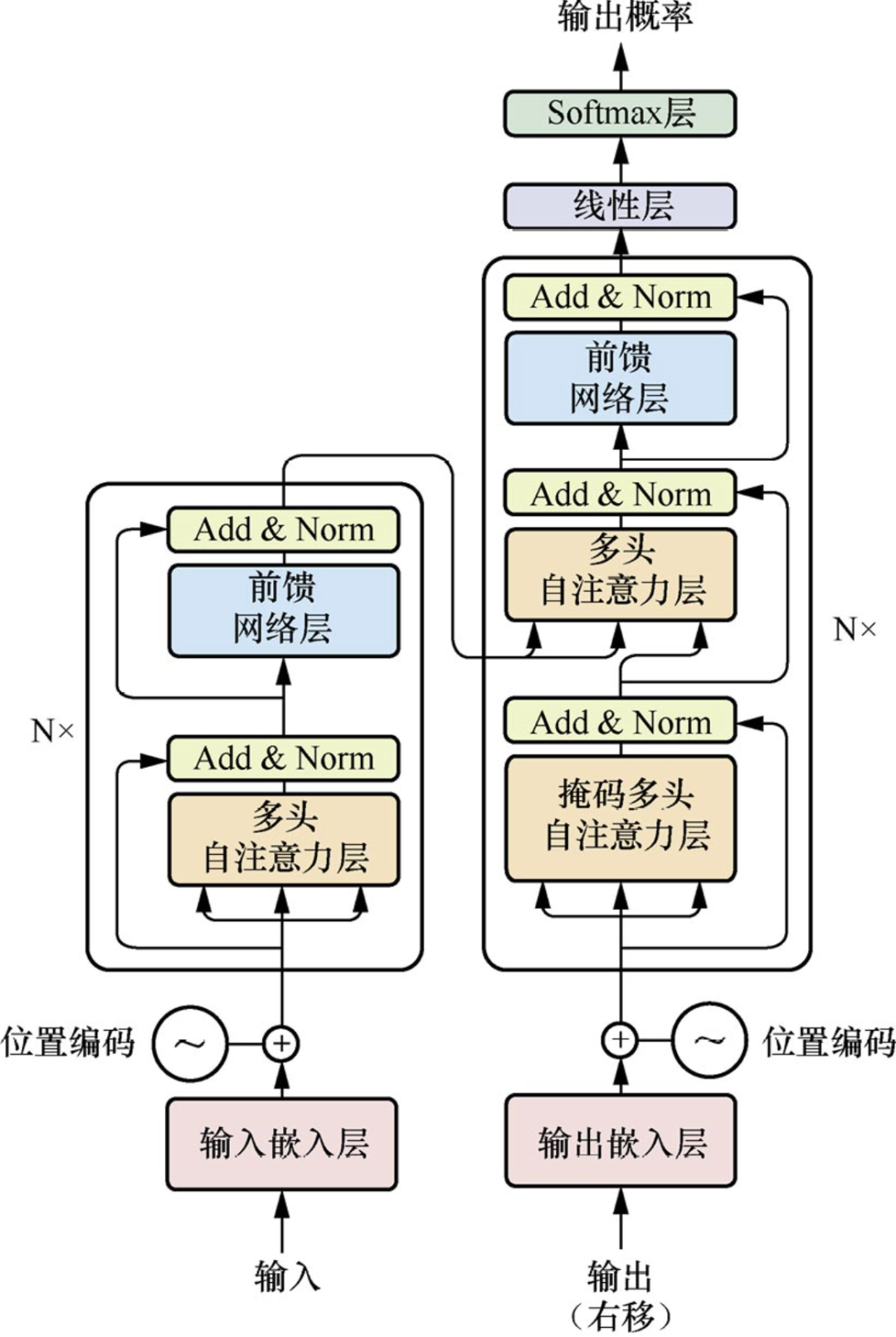
Transformer架构可以描述为:通过词嵌入和位置编码,再结合自注意力机制获取输入序列的全局信息,并将这些信息通过多头自注意力子层和前馈网络子层进行传递,每个子层的后面都会进行残差连接(Add)和层归一化(Norm)操作。
1、输入:在输入嵌入层使用GloVe模型(2014年斯坦福大学开源的词表征模型)等词向量模型来获得输入句子中每个Token的词向量。
2、位置编码:通过引入位置编码,Transformer模型能够有效地处理序列数据,同时捕捉Token之间的语义和位置关系。这对于NLP等领域的任务来说至关重要,也是Transformer模型能够取得优异性能的重要原因之一。
3、编码:上面两个步骤完成之后就可以进入编码器编码(包括了多个编码层:多头注意力+残差-归一+前馈网络+残差-归一)。Add操作可以加大网络训练的深度,防止梯度消失。Norm操作有助于平滑损失,加快训练和收敛速度。
前馈网络子层首先通过线性变换,将数据映射到高维度的空间,然后通过激活函数进行非线性变换,再映射回原始的低维度空间。通过前馈网络,可以提取更深层次的特征,从而提升模型的表达能力。前馈网络子层是Transformer最重要的结构之一,它将注意力向量作为输入,进行线性变换和非线性变换,以获得更为丰富的语义特征
4、解码:解码器的结构与编码器相似,只是在解码器堆栈处理完毕后,数据将被传递到带有线性层和Softmax层的输出处理层。线性层是一个全连接神经网络,它首先将解码器堆栈产生的向量投影到一个具有输出词表数量宽度的向量中,该向量的每个单元格对应一个唯一单词的分数,然后应用Softmax将向量中的每个单元格的分数转换成概率,概率最高的单元格所对应的单词就是当前预测的下一个可能的单词。
注意力是怎么实现的?
注意力机制是一种模仿人类视觉和认知系统的方法,它允许神经网络在处理输入数据时集中注意力于重要部分——本质是找到关键点、关键关系。通过引入注意力机制,神经网络能够自动地学习并选择性地关注输入中的重要信息,提高模型的性能和泛化能力。
自注意力机制(self-attention mechanism)是指在处理序列元素时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。它通过计算元素之间的相对重要性来自适应地捕捉元素之间的长程依赖关系。
自注意力计算的基本公式:
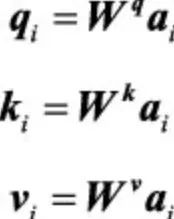
初始矩阵的设置:

自注意力机制的计算步骤:
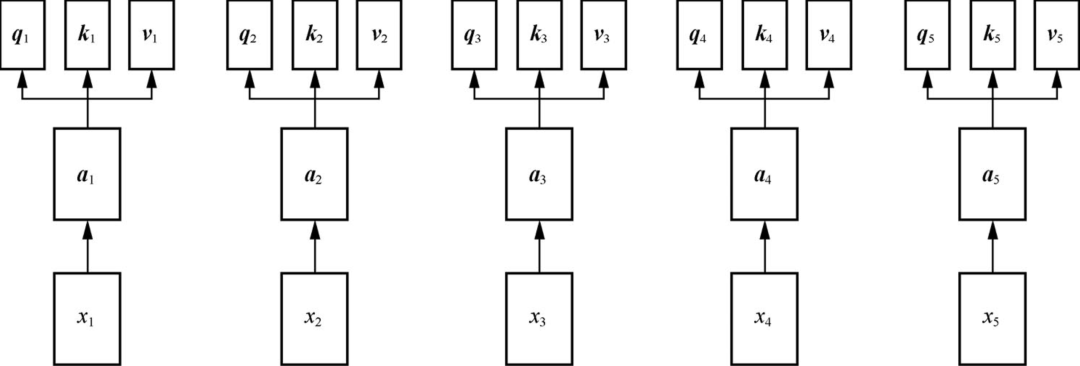
向量之间关系的计算过程:
Softmax处理:
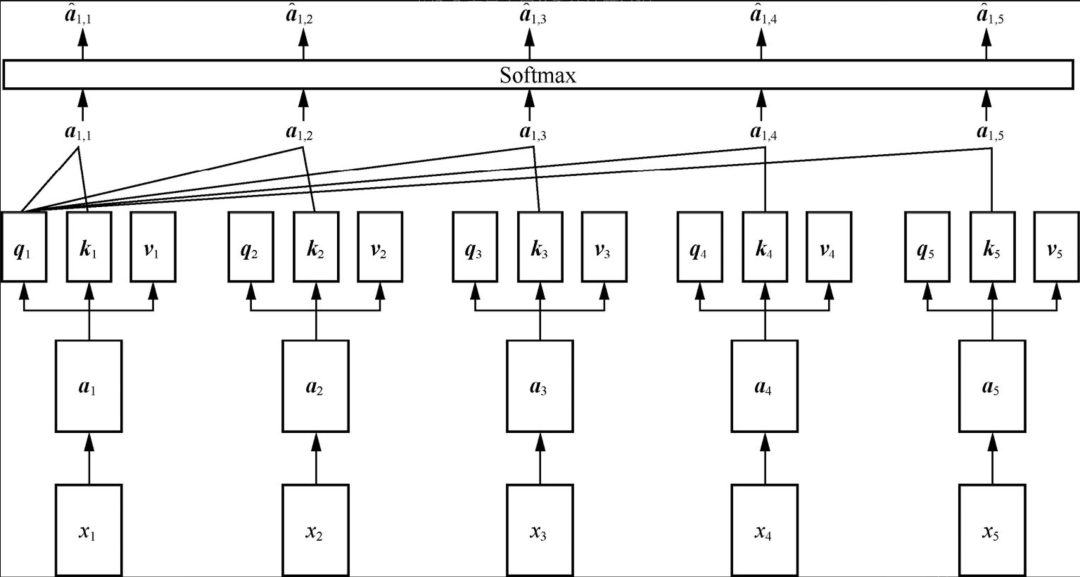
自注意力机制通过计算序列中不同位置之间的相关性(矩阵q、k操作),为每个位置分配一个权重,随后对序列进行加权求和,矩阵v操作:
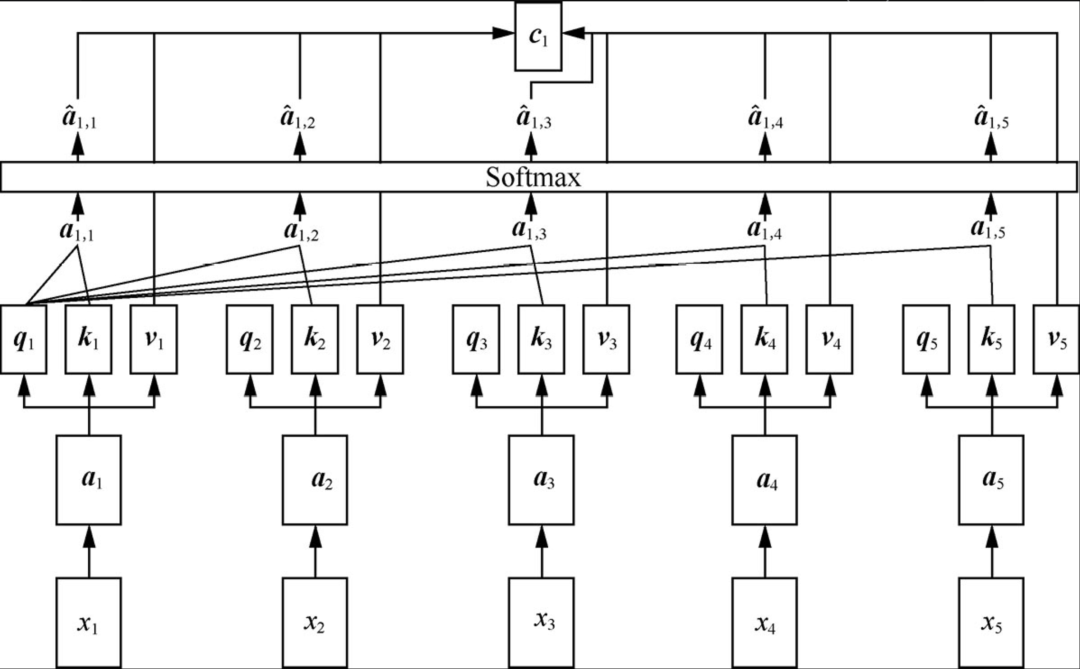
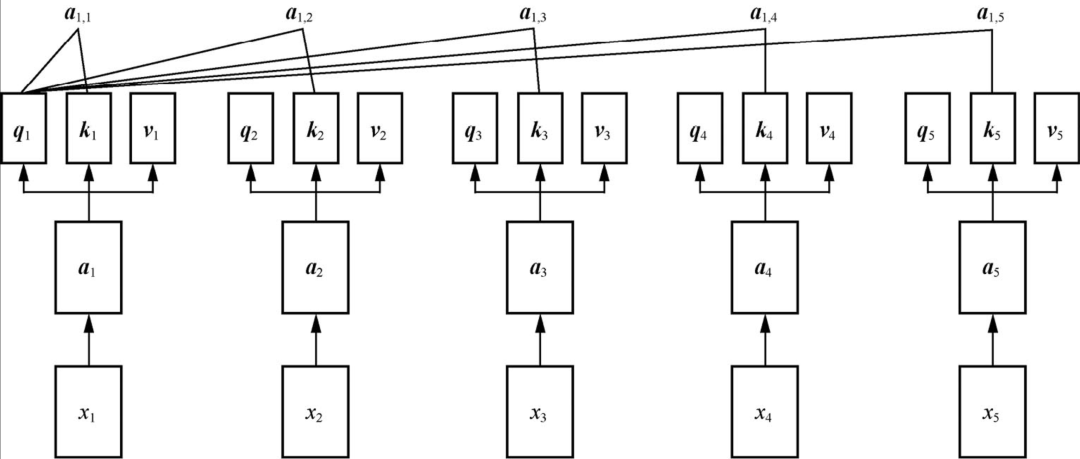
多头自注意力机制(multi-head self-attention mechanism)是在自注意力机制的基础上发展起来的,是自注意力机制的变体,旨在增强模型的表达能力和泛化能力。它通过使用多个独立的注意力头,分别计算注意力权重,并将它们的结果进行拼接或加权求和,从而获得更丰富的表征。
在自注意力机制中,每个单词或者字都有且只有一个矩阵q、k、v与其对应,多头自注意力机制则是为向量分配多组矩阵q、k、v,如下图所示:
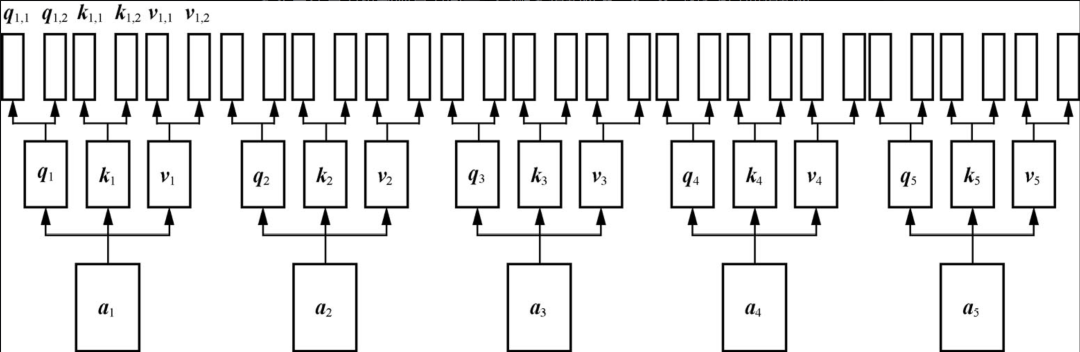
计算过程随之变复杂,理解了自注意力机制就可以比较好的理解多头自注意力机制,不再赘述。
总结
Transformer是在全球人工智能技术几十年发展成果的基础上提出来的,是全球在人工智能领域的阶段性智慧结晶。在它的基础上,又发展出了多模态大模型。如今,它已经成为人工智能领域的核心技术支撑。
通过学习、了解Transformer在NLP、计算机视觉以及多模态领域的发展历史,我们不仅能够学习这一关键技术的进化路线,而且能够预见未来技术的发展趋势。当然,在深入了解Transformer同时我们也应该关注Mamba、KAN等新的架构思想,每一次架构变换都可能带来新的技术变革,而且不同的架构适用的领域不同,对于天文学研究来说找到适合天文数据的架构是至关重要的事情。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 3200
3200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}