







近年来,随着长文本模型(Long-context Model, LCM)技术的突飞猛进,处理长上下文的能力已成为各大语言模型(Large Language Model, LLM)的核心竞争力,也是各大技术厂商争夺的焦点。截至2023年12月,鲜有模型能够超越8K上下文的限制,然而到了2024年9月,Gemini Pro模型已经能够处理长达2M的上下文。在短短9个月的时间里,长文本模型的上下文窗口实现了250倍的惊人增长。最近备受关注的OpenAI的o1-preview模型,第三方文档[1]也宣称能够处理长达130K的上下文。
那么,这些模型在长文本理解任务的基准测试中表现如何呢?通过观察最新或最常用的几个基准测试榜单,可以发现一个有趣的现象:无论是在处理长度(图1:XL2Bench,2024年),任务难度(图2:Ruler,2024年),还是真实世界任务(图3:LongBench,2024年)方面,开源模型普遍落后于闭源模型。除此之外,似乎没有更多关键的信息值得关注。

图1:XL2Bench,红框表示开源模型

图2:Ruler的部分结果,红框表示开源模型

图3:LongBench的部分结果,红框表示开源模型
随着长文本评测基准如雨后春笋般涌现,但随之而来的是这些基准测试之间出现了严重的同质化现象。它们要么竞相增加文本长度,要么提高任务难度,甚至两者兼而有之。在某些情况下,这种趋势导致即使是最先进的闭源模型,如GPT-4,也在测试中表现不佳。但是,这样的竞争真的有意义吗?
这种背景下,我们应该思考一下长文本模型开发的初衷究竟是什么,只有明确了这一目标,我们才能对症下药,设计出更合理的评测基准 。下面我们首先回顾一下长文本模型在现实世界中最普遍的应用场景——长文本理解任务。基于这一场景,我们再引出评测长文本模型时应当关注的能力。
长文本模型与长文本理解任务
通常,用户的一种可能输入如图4所示:
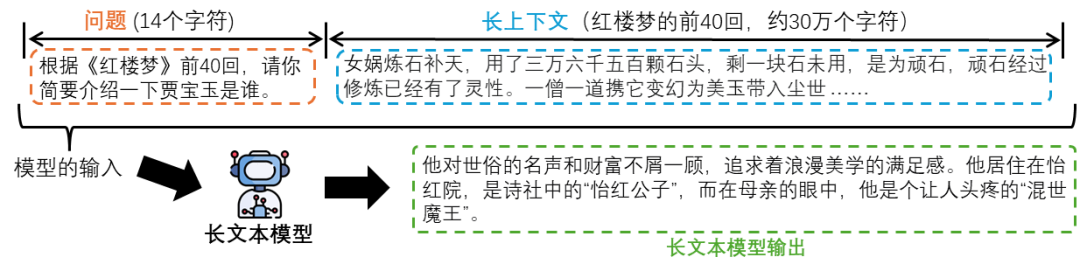
图4:用户输入一个问题,然后提供一个长的上下文片段,让长文本模型进行回复
当然啦,如果你是一个忠实的LLM信徒,你肯定会相信这个回复。But,如果你对这些回复持有怀疑态度,那也是再正常不过的事情,因为大家脑海里面肯定都会有个疑问“模型的回复真的正确吗?”难道我们还要先去读一遍文章,然后再回头检查模型的回复吗?
但如果模型在给出答案的同时,还能提供参考文本,就像图5展示的那样,那用户就可以直接根据这些参考信息来验证模型的回复。用户直接根据参考章节以及内容,带回原文找就完事了。这种提供参考来源的做法,我们通常称之为“引证”(Citation),其可以反映出模型的忠实度(faithfulness)。

图5:长文本模型不仅回复答案,还回复参考的文本(引证)
引证生成的现状 & 我们的进展
在当前的长文本模型评测领域,测试模型忠实度的榜单确实还不多见。ALCE[2]曾经是一个备受认可的评测基准,专注于评估模型的引文生成能力,从而间接反映其忠实度。然而,随着长文本处理技术的发展,ALCE中的任务所涉及的上下文长度已经显得有些捉襟见肘。
为了适应这一挑战,THU结合了Longbench中的QA任务,提出了ALCE的加长版LongCite[3],虽然这在一定程度上解决了长度问题,但仍然局限于QA任务,且最长上下文长度仅达到32K,这与当前长文本模型的上下文处理能力相比,仍有较大差距。
针对这一现状,我们提出了一个全新的长文本理解任务基准——L-CiteEval。L-CiteEval是一个多任务的、包含引证生成的长文本理解基准,它覆盖了5个主要任务类别,包括单文档问答、多文档问答、摘要、对话理解和合成任务,共包含11个不同的长文本任务。这些任务的上下文长度从8K到48K不等。同时,我们提供自动化的评估工具(不依赖人工评测或者GPT4评测),便于研究者和开发者对模型进行客观评价。
论文 & 代码(评测数据)传送门:
论文:L-CiteEval: Do Long-Context Models Truly Leverage Context for Responding?
链接:https://arxiv.org/pdf/2410.02115
项目:https://github.com/ZetangForward/L-CITEEVAL
下面将简要介绍一下我们的工作,更多细节还请参考我们的论文与源码(包括评测数据)。
Note:代码库还在整理,国庆结束之前应该可以放出来,欢迎大家使用和提出宝贵的意见哈~
L-CiteEval 任务形式
如图6所示,在L-CiteEval基准测试中,模型需要根据用户的问题(Question, Q)和提供的长参考上下文(Reference, R)生成回复(Response, R)。为了确保回复的准确性和可验证性,模型被要求按照特定的格式生成回复,即每个陈述(Statement, S)后面都要跟随一个对应的引证(Citation, C)。这样的格式有助于在验证(Verification, V)阶段对模型的回复进行全面的评估。
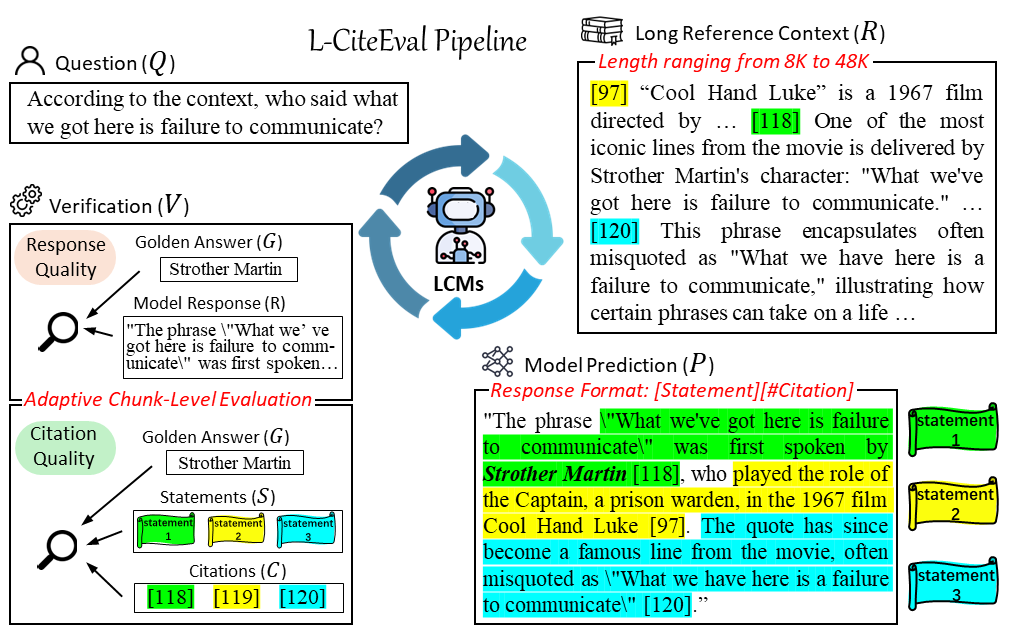
图6:L-CiteEval的任务形式
数据集分布 & 制作
1) 评测数据集分布
图7展示了测试数据集的数据分布情况,对于不同的任务的生成质量我们提供了对应的自动评测指标。对于引证质量的评估,则采用了统一的标准,即Citation Recall (CR)、Citation Precision (CP) 和 Citation F1 score (F1) 这三个指标。这些指标的计算方式与ALCE基准测试中使用的相同,具体计算方式可以参考ALCE。
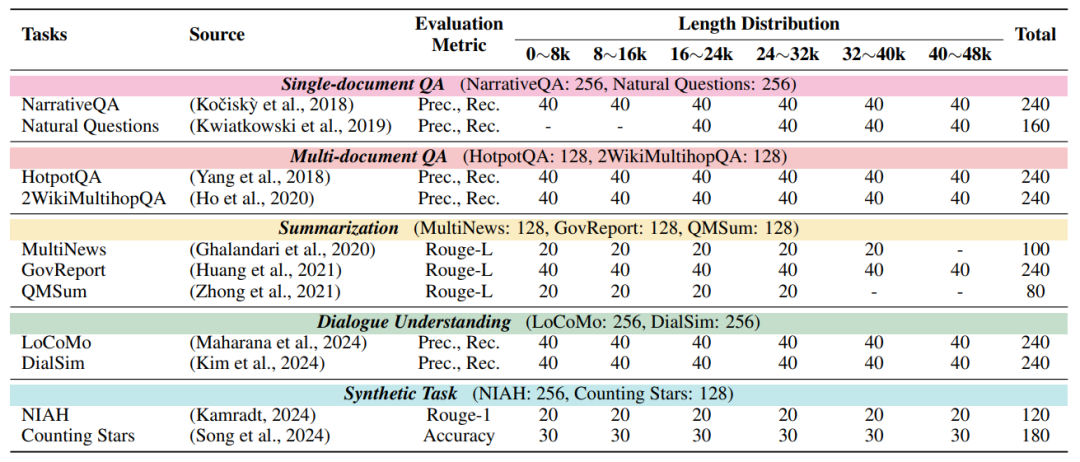
图7:L-CiteEval测试数据集分布
2) 数据集制作流程
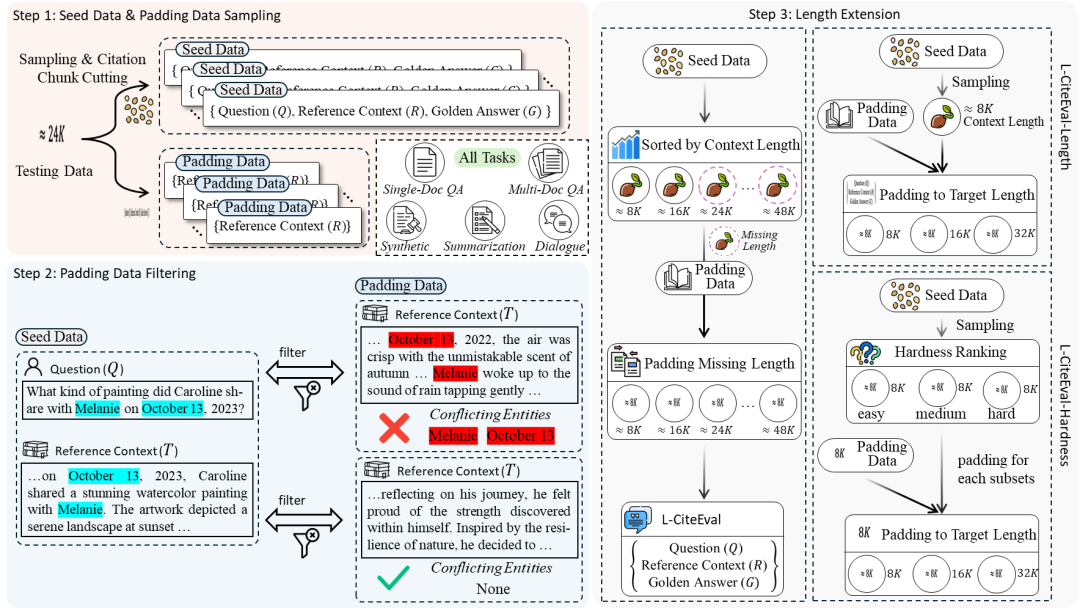
图8:L-CiteEval测试数据流程
如图8所示,具体的测试数据制作流程包含三个步骤,分别为:
-
种子数据和填充数据采样(Seed Data & Padding Data Sampling):
-
从每个源数据集中采样一部分测试数据集作为种子数据。
-
对于上下文较短的数据集,从剩余的数据集中采样数据作为候选填充数据,用于扩展上下文长度。
-
填充数据过滤(Padding Data Filtering):
-
使用命名实体识别(NER)模型从种子数据中的问题和参考上下文中提取实体,并从填充数据的参考上下文中提取实体。
-
保留与种子数据实体重叠较少的填充样本,以减少可能影响预测的额外上下文信息。
-
长度扩展(Length Extension):
-
利用筛选后的填充数据来扩展种子数据的上下文长度。
-
根据目标长度间隔,随机采样填充数据,以填补种子数据缺失的长度间隔。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

模型评测
模型选择
如图9所示,我们的评测目前最常用的长文本模型,覆盖了闭源、开源、不同尺寸,不同结构的模型。

图9:模型选择
主实验结果:

图10:模型在信息集中任务上的引证质量

图11:模型在信息分散任务上的引证质量
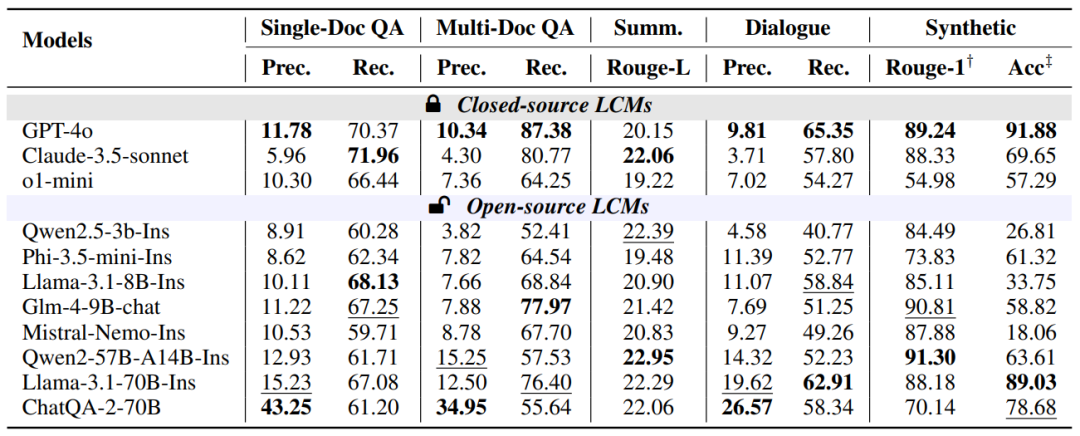
图12:模型的生成质量
几个关键结论:
-
闭源模型的性能:闭源模型GPT-4o和Claude-3.5-sonnet在生成质量和引用质量方面表现出色,尤其是在引用准确性和召回率方面。但是o1-mini更适合推理任务,而不适合这种需要检索上下文的任务。
-
开源模型的性能:开源模型在生成质量方面与闭源模型相近,但在引用质量方面落后,特别是在需要推理的任务上;一些较大的开源模型,如Llama-3.1-70B-Instruct,在某些任务上的表现接近闭源模型。
-
模型大小与性能:模型大小并不总是与性能成正比。一些中等大小的模型(如8B和9B)在某些任务上的表现与较大的模型相当,说明中等模型的性价比很高,还有很大的开发空间。但是大模型的效果总体上是更加稳定,如果能进一步增强,则有机会追赶闭源模型。
其他实验
长度 还是 问题难度 对长文本模型影响大?
L-CiteEval-Length和L-CiteEval-Hardness是L-CiteEval基准测试的两个变体,它们旨在从不同的角度评估长文本模型的性能, 两者的目的如下:
-
L-CiteEval-Length 这个变体专注于评估模型在不同上下文长度下的性能。
-
L-CiteEval-Hardness这个变体专注于评估模型在不同任务难度下的性能。
评测结果见图12,图13所示。关键结论:
-
上下文长度的影响(L-CiteEval-Length):当任务难度保持不变,上下文长度增加时,开源LCMs的性能总体上呈现下降趋势,尤其是较小的模型受到更长上下文的影响更大。闭源LCMs,如GPT-4o,即使在更长的上下文长度下也保持相对稳定的性能。
-
任务难度的影响(L-CiteEval-Hardness):随着任务难度的增加,LCMs的生成质量通常下降,但引用质量并没有显示出一致的趋势。这表明忠实度(是否基于上下文进行回复)与任务难度不强相关。

图12:模型在L-CiteEval-Length上的生成与引证质量
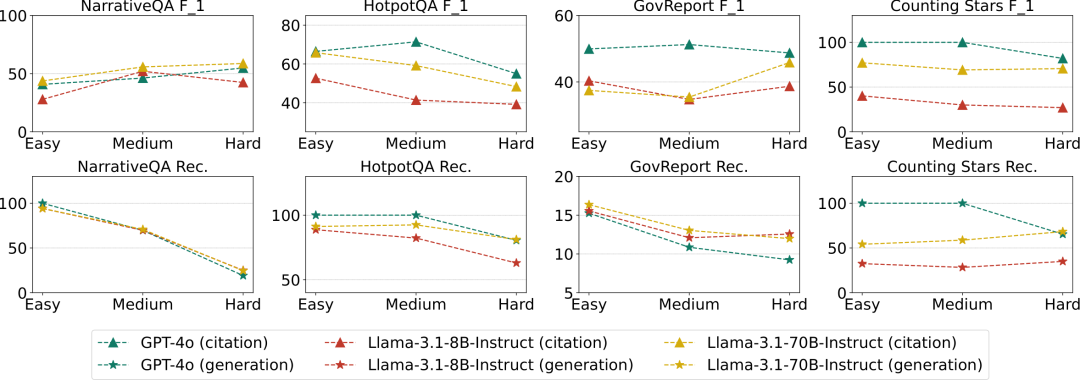
图13:模型在L-CiteEval-Hardness上的生成与引证质量
RAG对L-CiteEval 是否有帮助?

图14:RAG增强的长文本模型在L-CiteEval子任务上的生成与引证质量
如图14所示,RAG技术在开源模型上显著提高了模型的忠实度(甚至和GPT4o性能相持平)。然而,RAG技术可能会略微影响模型的生成质量。
引证生成和Attention机制有关系吗?
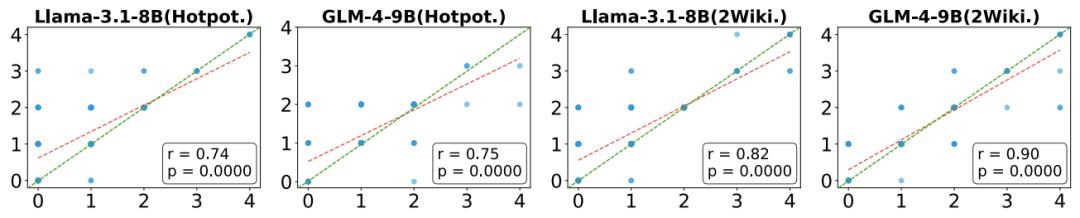
图15:引证生成和Attention机制的关系(相关性系数). 红线:拟合的相关性曲线; 绿线: 理论最优相关性曲线
注意力机制是许多现代LCMs的关键组成部分,它使模型能够关注输入序列中最重要的部分。在长文本处理任务中,有效的注意力分配可以帮助模型更好地理解和利用上下文信息。
如图15所示, 红色的线(引证生成与Attention相关性曲线)与绿色的线(理论最优的相关性曲线) 具有很高的重合程度。这表明模型在生成引用时所关注的上下文片段与实际正确的引用之间存在高度相关性, 如果模型的注意力机制能够正确地集中在包含答案信息的上下文片段上,那么模型更有可能生成准确的引用。
这一发现作证了 引证生成(Citation Generation) 以及L-CiteEval 基准测试集的合理性,另一方面,也为未来的长文本领域的基准测试集以及长文本模型的开发提供了思路。
结论
本篇文章提出的评测基线着重于生成结果的可解释性及模型的忠实度,这是长文本模型发展中一个重要的考量维度。但随着技术的不断进步,我们不得不深思:未来的长文本模型真的需要无休止地追求更长的上下文处理能力吗?在现实应用中,我们真的频繁需要模型处理如此庞大的文本量吗?长文本模型的发展,似乎正在进入一个“卷”的怪圈,盲目追求数字上的突破,却可能忽略了实际应用的真正需求。
实际上,用户可能更关心的是模型是否真正基于上下文进行回答,而不仅仅是答案的正确性。这种关注点的转移,提示我们在未来的研究中,也许应该更多地关注模型的理解和推理能力,以及如何让模型的决策过程更加透明和可解释。我们是否应该从“更长上下文”的竞赛中跳出来,转而探索如何使模型在给定的上下文中做出更精准、更符合人类思维方式的回应?
长文本模型的“真实窗口大小”,或许不应该是模型能处理的文本长度,而应该是模型能理解和运用上下文信息的深度和准确性。这种深度和准确性,才是构建用户信任和满意度的关键。因此,未来的长文本模型研究,也许应该更多地聚焦于提升模型的忠实度和可解释性,而不是单纯地追求处理更长文本的能力。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}