






简单过一下哈from scratch
SqueezeNet
《SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5MB》
<2016.02// 伯克利&斯坦福// ICLR 2017>
paper: https://arxiv.org/pdf/1602.07360.pdf
code: https://github.com/DeepScale/SqueezeNet
特点:
- Replace 3x3 filters with 1x1 filters.
- Decrease the number of input channels to 3x3 filters.
- Downsample late in the network so that convolution layers have large activation
maps.

A Fire module is comprised of: a squeeze convolution layer (which has only 1x1 filters), feeding into an expand layer that has a mix of 1x1 and 3x3 convolution filters;

class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
MobileNet
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
----Google
paper: https://arxiv.org/pdf/1704.04861.pdf
code: pytorch实现 https://github.com/jmjeon94/MobileNet-Pytorch
创新点:
- 采用名为 depth-wise separable convolution 的卷积方式代替传统卷积方式,以达到减少网络权值参数的目的。
- 提出两个超参数Width Multiplier和Resolution Multiplier来平衡时间和精度。
(第一个参数width multiplier主要是按比例减少通道数,该参数记为 α \alpha α,其取值范围为(0,1],则输入与输出通道数将变成 α M \alpha M αM 和 α N \alpha N αN;
第二个参数resolution multiplier主要是按比例降低特征图的大小)
写的比较好的博客:https://blog.csdn.net/mzpmzk/article/details/82976871
https://zhuanlan.zhihu.com/p/101888768
深度可分离卷积:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution) --------主要目的是降低模型参数量和计算量

def conv_dw(inp, oup, stride):
return nn.Sequential(
# dw
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# pw
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
网络结构:所有卷积层都加BN和ReLU,每个block由标准1×1卷积+深度分离3×3卷积组成,使用conv/s2方式下采样,网络第一层使用的是标准卷积。整个网络通道数依次为:128,256,512,1024,block数量为2,2,6,2。可见,通道数依然很多,这也可能是MobileNet泛化能力较好的原因之一。
结果:参数数量4.2M,计算量569M,top-1 70.6%,性能和GoogLeNet和VGG16差不多,比VGG16模型小32倍,计算量低27倍,比GoogLeNet模型更小,计算量低2.5倍。
MobileNet V2
《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
paper: https://arxiv.org/pdf/1801.04381.pdf
创新点:
- Inverted residual block:引入残差结构和bottleneck层。-----增强梯度的传播,显著减少推理期间所需的内存占用
- Linear Bottlenecks:ReLU会破坏信息,故去掉第二个Conv1x1后的ReLU,改为线性神经元。------保留特征多样性,增强网络的表达能力
(通常的residual block是先1×1Conv减少通道数,再3×3 Conv,最后经过一个1×1 Conv,将通道数再“扩张”回去。即先“压缩”,最后“扩张”回去。而 inverted residuals就是 先“扩张”,最后“压缩”,Depth-wise convolution之前多了一个1×1的“扩张”层,目的是为了提升通道数,获得更多特征;)

class InvertedBlock(nn.Module):
def __init__(self, ch_in, ch_out, expand_ratio, stride):
super(InvertedBlock, self).__init__()
self.stride = stride
assert stride in [1,2]
hidden_dim = ch_in * expand_ratio
self.use_res_connect = self.stride==1 and ch_in==ch_out
layers = []
if expand_ratio != 1:
layers.append(conv1x1(ch_in, hidden_dim))
layers.extend([
#dw
dwise_conv(hidden_dim, stride=stride),
#pw
conv1x1(hidden_dim, ch_out)
])
self.layers = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.layers(x)
else:
return self.layers(x)
MobileNet V1和 MobileNet V2:

MobileNet V2和ResNet区别:

MobileNet V3:
《Searching for MobileNetV3》
paper: https://arxiv.org/pdf/1905.02244.pdf
code: https://github.com/kuan-wang/pytorch-mobilenet-v3
- 网络的设计不再是人为设定了,而是先采用NAS算法,计算出大体的网络结构,然后再使用NetAdapt算法优化每个层的输入输出通道数。从而通过算法得到一个网络效率在设定目标时间内的“最优"网络结构。这是本篇论文最重要的部分之一;
- MobileNetV3的基础模块是在MobileNetV2的bottleneck模块的基础上,增加SE注意力模块得到的。
- 还提出了h-swish激活函数,保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。
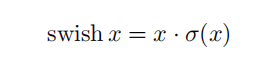
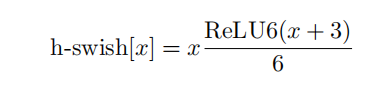
互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索
网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。

class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
return F.relu6(x + 3., inplace=self.inplace) / 6.
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.inplace = inplace
def forward(self, x):
out = F.relu6(x + 3., self.inplace) / 6.
return out * x
def _make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class SqueezeBlock(nn.Module):
def __init__(self, exp_size, divide=4):
super(SqueezeBlock, self).__init__()
self.dense = nn.Sequential(
nn.Linear(exp_size, exp_size // divide),
nn.ReLU(inplace=True),
nn.Linear(exp_size // divide, exp_size),
h_sigmoid()
)
def forward(self, x):
batch, channels, height, width = x.size()
out = F.avg_pool2d(x, kernel_size=[height, width]).view(batch, -1)
out = self.dense(out)
out = out.view(batch, channels, 1, 1)
# out = hard_sigmoid(out)
return out * x
class MobileBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernal_size, stride, nonLinear, SE, exp_size):
super(MobileBlock, self).__init__()
self.out_channels = out_channels
self.nonLinear = nonLinear
self.SE = SE
padding = (kernal_size - 1) // 2
self.use_connect = stride == 1 and in_channels == out_channels
if self.nonLinear == "RE":
activation = nn.ReLU
else:
activation = h_swish
self.conv = nn.Sequential(
nn.Conv2d(in_channels, exp_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(exp_size),
activation(inplace=True)
)
self.depth_conv = nn.Sequential(
nn.Conv2d(exp_size, exp_size, kernel_size=kernal_size, stride=stride, padding=padding, groups=exp_size),
nn.BatchNorm2d(exp_size),
)
if self.SE:
self.squeeze_block = SqueezeBlock(exp_size)
self.point_conv = nn.Sequential(
nn.Conv2d(exp_size, out_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_channels),
activation(inplace=True)
)
def forward(self, x):
# MobileNetV2
out = self.conv(x)
out = self.depth_conv(out)
# Squeeze and Excite
if self.SE:
out = self.squeeze_block(out)
# point-wise conv
out = self.point_conv(out)
# connection
if self.use_connect:
return x + out
else:
return out
ShuffleNe
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for MobileDevices》-face++团队
paper: https://arxiv.org/pdf/1707.01083.pdf
code: https://github.com/megvii-model/ShuffleNet-Series

比较好的blog:https://www.cnblogs.com/hellcat/p/10318630.html
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size()
assert num_channels % self.group == 0
group_channels = num_channels // self.group
x = x.reshape(batchsize, group_channels, self.group, height, width)
x = x.permute(0, 2, 1, 3, 4) # 转置
x = x.reshape(batchsize, num_channels, height, width)
return x

ShuffleNet v2
paper: https://arxiv.org/abs/1807.11164v1
- 卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快;
- 过多的group操作会增大MAC,从而使模型速度变慢;
- 模型中的分支数量越少,模型速度越快;
- element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作。
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









