







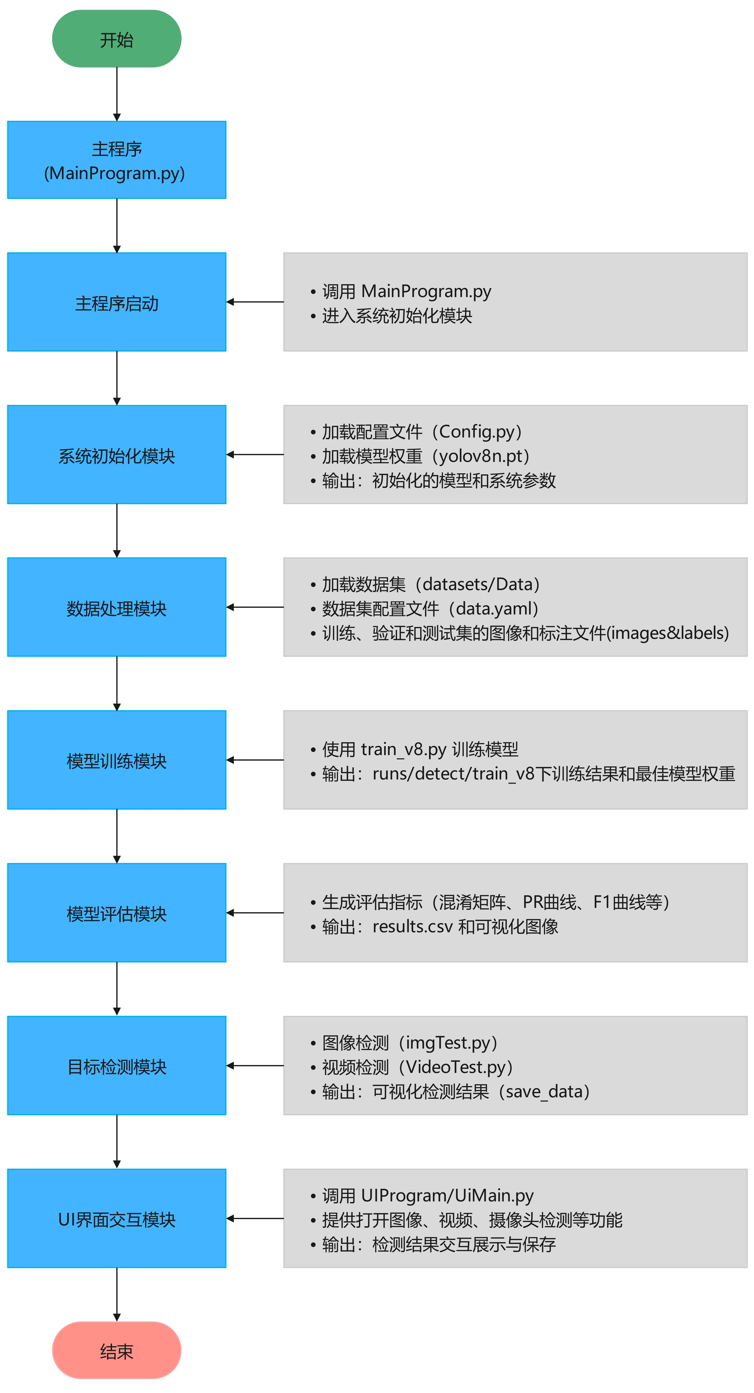
随着教育领域的智能化发展,考场监督的效率和公平性成为亟待解决的问题。针对传统考场监控效率低、漏报和误报率高的问题,本文提出了一种基于YOLOv8深度学习的考试作弊行为自动检测与语音报警系统。该系统以PyQt5作为用户界面框架,集成了数据采集、模型训练、实时检测和语音报警等功能,能够对考场中常见的作弊行为进行分类和识别,包括“使用手机 (CellPhone)”、“传递作弊材料 (GivingCheats)”、“直接作弊 (Cheating)”、“偷看他人试卷 (LookingOver)”、“低头作弊 (LookingDown)”及“无作弊行为 (NotCheating)”。
系统设计包含以下关键模块:
1) 数据采集与预处理,基于真实考场环境构建多类别作弊行为数据集;
2) 基于YOLOv8的深度学习模型训练,优化模型的检测精度和速度;
3) 实时行为检测模块,通过高效推理实现对考场实时视频流的作弊行为检测;
4) 智能语音报警模块,及时提醒监考人员采取相应措施。实验结果表明,该系统在复杂考场环境中表现出高效性与鲁棒性,检测准确率高,且具备良好的实时性和用户体验。
本研究为智慧考场监控系统的开发提供了新思路,能够显著提升监考效率,保障考试公平性,具有广泛的应用前景。
算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
项目数据
Tipps:通过搜集关于数据集为各种各样的考试作弊相关图像,并使用Labelimg标注工具对每张图片进行标注,分6检测类别,分别是’使用手机作弊’,’传递作弊材料’,’考试直接作弊’,’偷看他人试卷’,’低头作弊查看’,’考生没有作弊’。
目标检测标注工具
(1)labelimg:开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式。
(2)安装labelimg 在cmd输入以下命令 pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
![]()
结束后,在cmd中输入labelimg
![]()
初识labelimg
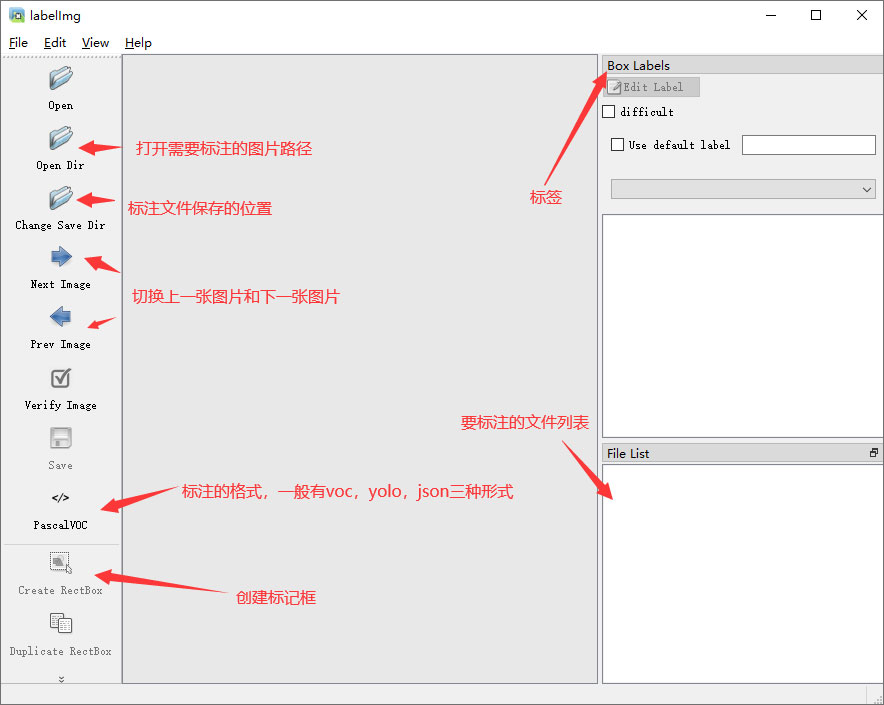
打开后,我们自己设置一下
在View中勾选Auto Save mode
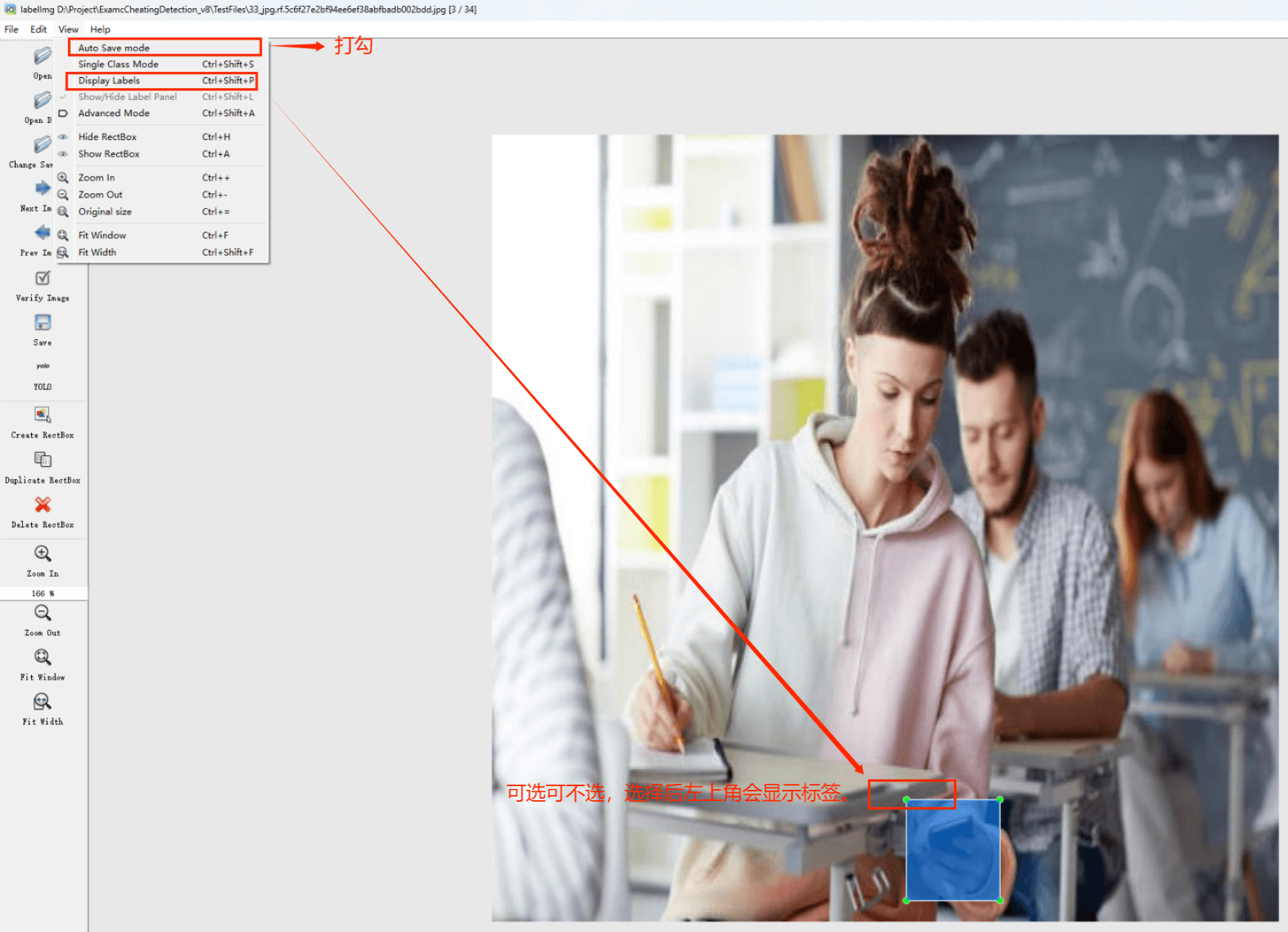
接下来我们打开需要标注的图片文件夹
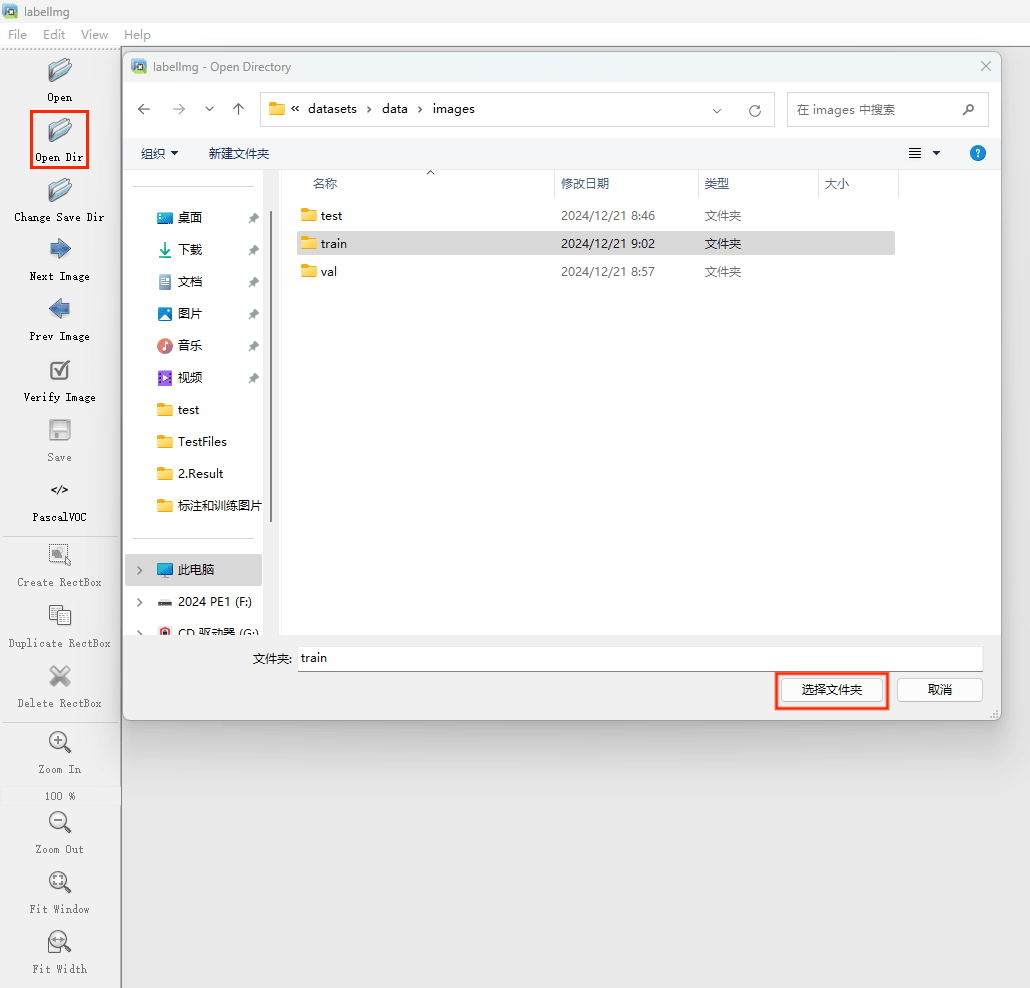
并设置标注文件保存的目录(上图中的Change Save Dir)
接下来就开始标注,画框,标记目标的label,然后d切换到下一张继续标注,不断重复重复。
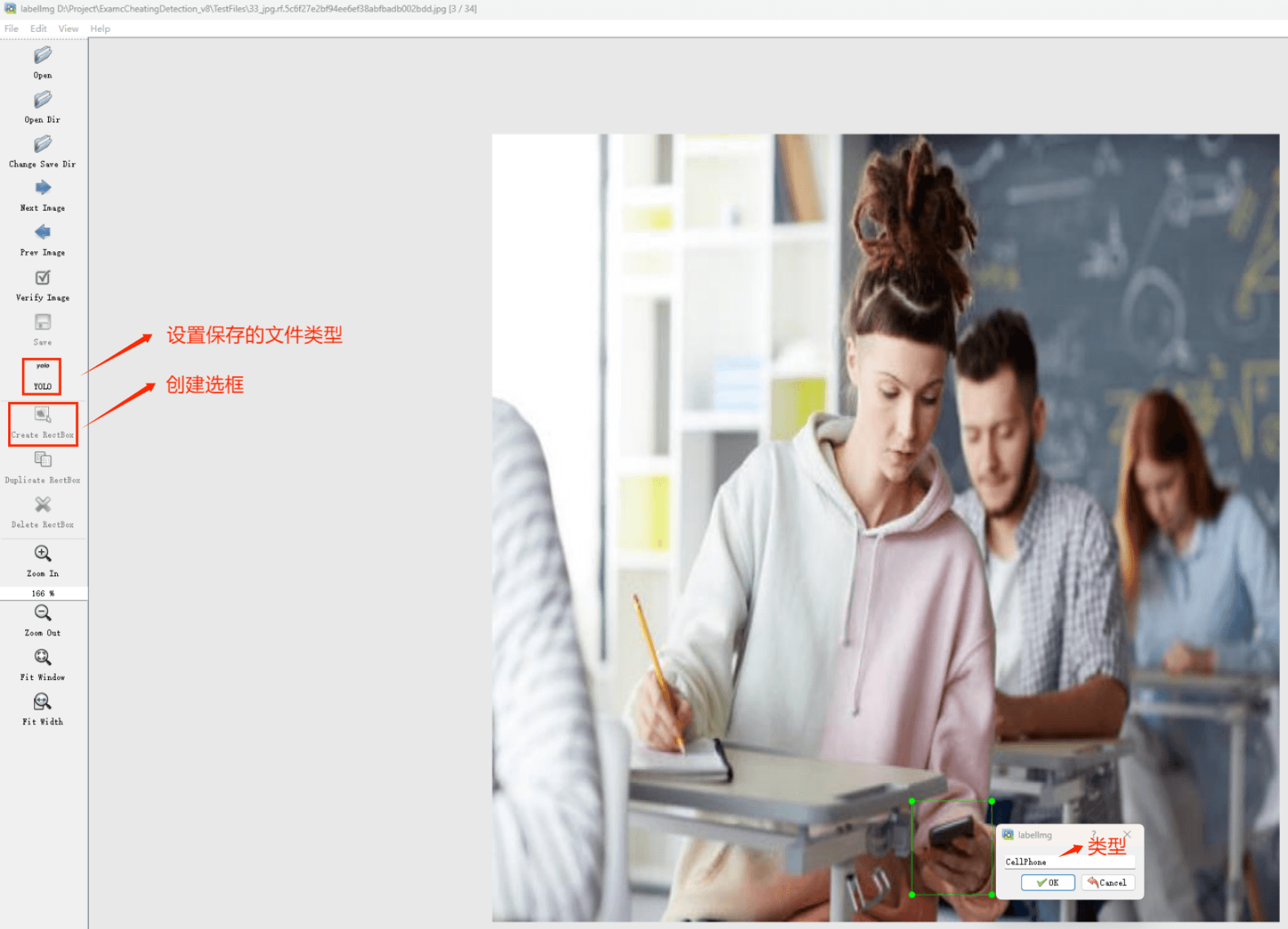
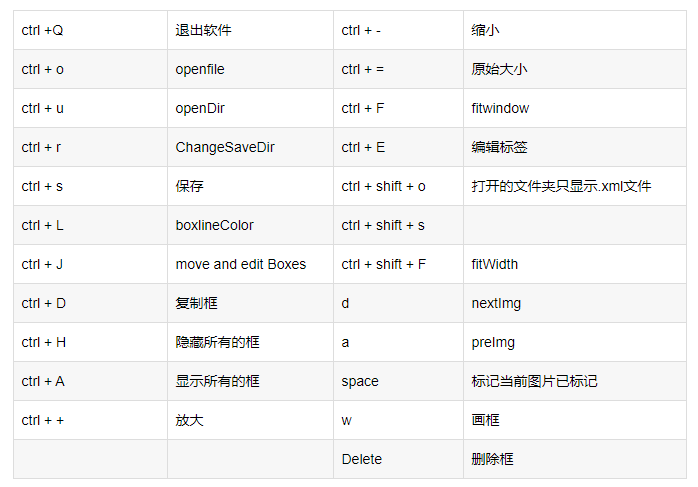
Labelimg的快捷键
(3)数据准备
这里建议新建一个名为data的文件夹(这个是约定俗成,不这么做也行),里面创建一个名为images的文件夹存放我们需要打标签的图片文件;再创建一个名为labels存放标注的标签文件;最后创建一个名为 classes.txt 的txt文件来存放所要标注的类别名称。
data的目录结构如下:
│─img_data
│─images 存放需要打标签的图片文件
│─labels 存放标注的标签文件
└ classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
首先在images这个文件夹放置待标注的图片。
生成文件如下:
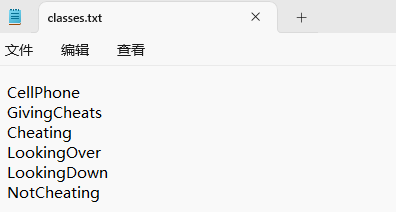
“classes.txt”定义了你的 YOLO 标签所引用的类名列表。
(4)YOLO模式创建标签的样式
存放标签信息的文件的文件名为与图片名相同,内容由N行5列数据组成。
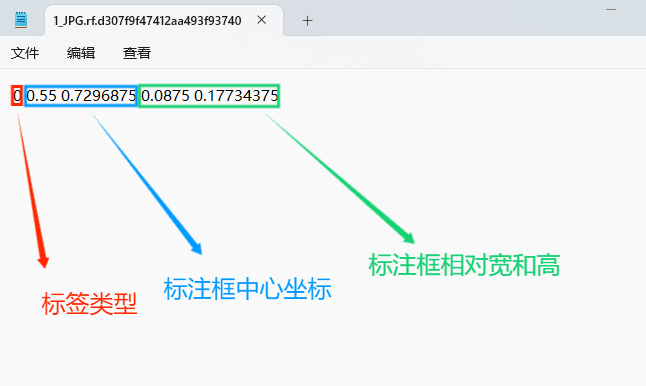
每一行代表标注的一个目标,通常包括五个数据,从左到右依次为:类别id、x_center、y_center、width、height。
其中:
–x类别id代表标注目标的类别;
–x_center和y_center代表标注框的相对中心坐标;
–xwidth和height代表标注框的相对宽和高。
注意:这里的中心点坐标、宽和高都是相对数据!!!
存放标签类别的文件的文件名为classes.txt (固定不变),用于存放创建的标签类别。
完成后可进行后续的yolo训练方面的操作。
硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









