






题目描述
所有的网页浏览器都有访问、前进与后退按钮,它们的工作原理如下:
- 访问操作需要用户提供一个网址,浏览器将会访问该网址,并将该网址的前继设为跳转前的网址;
- 后退操作会检查当前网址是否有前继(除第一个网址外,每个网址都有前继),如果有,浏览器将访问当前网址的前继;
- 前进是用于抵消后退的:
- 若前一步是后退,浏览器退回至后退前的网页。
- 若前一步是访问,忽略这条前进操作。
- 若前一步也是前进,若上步前进已经抵消了一个后退,则根据更早的操作确定前进的作用,否则,忽略这条操作。
给定 n 条操作,请你模拟浏览器的行为,并输出它执行每条操作时所访问的网址。
输入格式
第一行:单个正整数 n 表示操作数量;
接下来 n 行:每行表示一步操作,
- 访问以字母
v开头,后接一条网址,保证该网址中间没有空格或者其他不可见字符;
- 后退仅有一个字母
b; - 前进仅有一个字母
f。
输出格式
共 n 行:对每一步操作,
- 如果浏览器访问了某个网址,则输出该网址;
- 如果浏览器忽略了这部操作,则输出一个
?。
数据范围
保证每个输入的网址长度不会超过 30;
- 对于 30% 的数据,1≤n≤1000;
- 对于 60% 的数据,1≤n≤10000;
- 对于 100% 的数据,1≤n≤50000。
样例数据:
输入1:
10
v iai.sh.cn
v scs.sh.cn
v yacs.club
b
b
f
f
f
v ioinformatics.org
f
输出1:
iai.sh.cn
scs.sh.cn
yacs.club
scs.sh.cn
iai.sh.cn
scs.sh.cn
yacs.club
?
ioinformatics.org
?
输入2:
8
v iai.sh.cn
v taobao.com
v baidu.com
b
b
v tmall.com
f
b
输出2:
iai.sh.cn
taobao.com
baidu.com
taobao.com
iai.sh.cn
tmall.com
?
iai.sh.cn
解析:
这道题用两个栈就很方便地解决,大致流程如下:

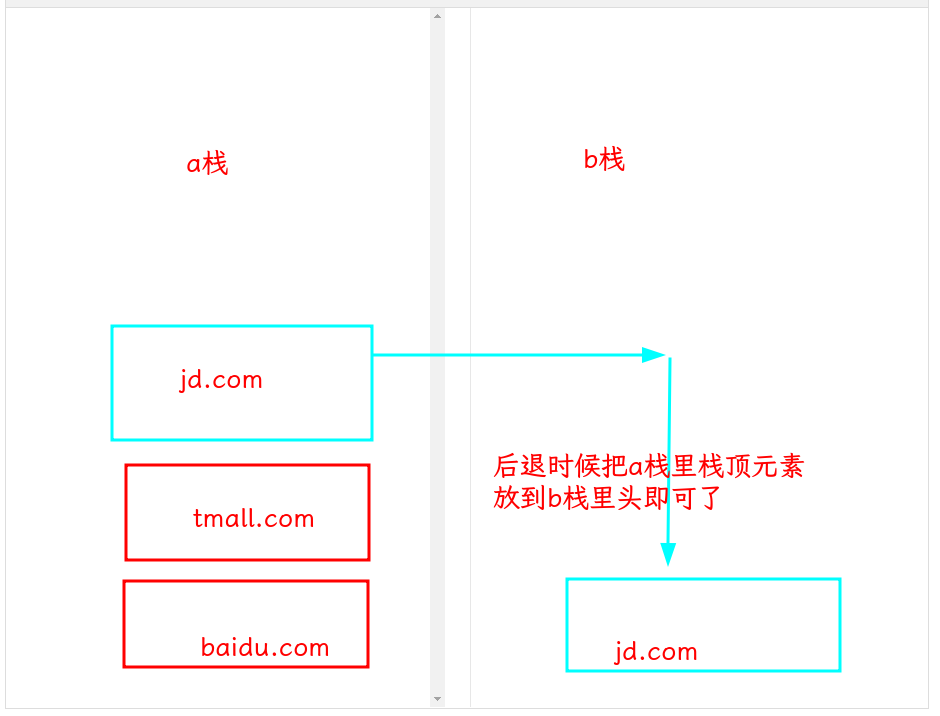
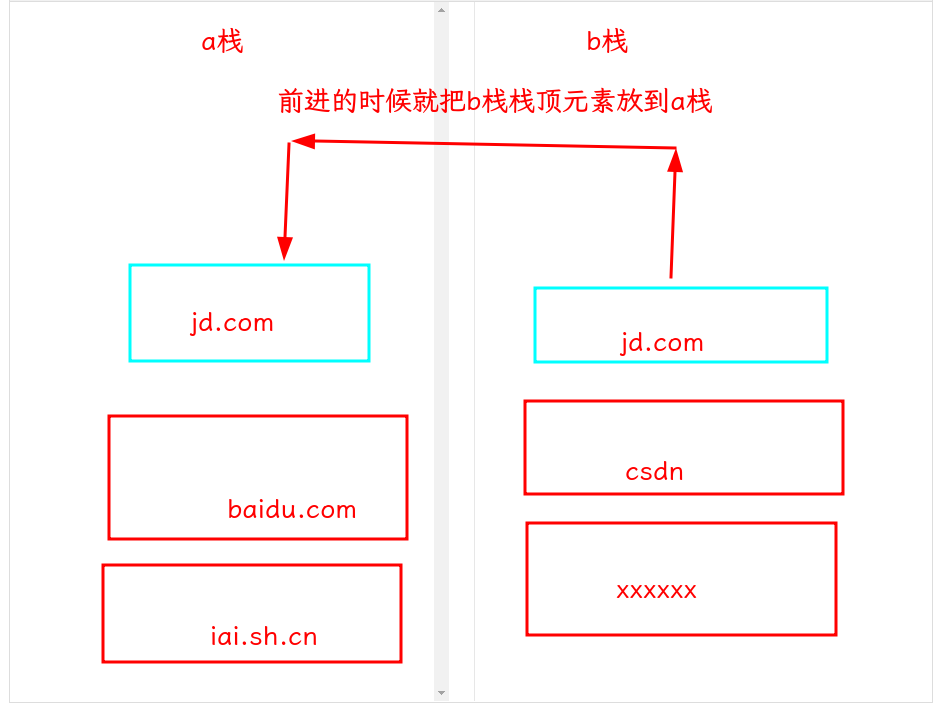
代码:
#include<bits/stdc++.h>
using namespace std;
stack<string> a,b;
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
char c;
cin>>c;
if(c=='v'){
string s;
cin>>s;
cout<<s<<endl;
a.push(s);
while(!b.empty()){
b.pop();
}
}
else if(c=='b'){
if(a.size()>1){
b.push(a.top());
a.pop();
cout<<a.top()<<endl;
}
else cout<<"?"<<endl;
}
else {
if(!b.empty()){
a.push(b.top());
b.pop();
cout<<a.top()<<endl;
}
else cout<<"?"<<endl;
}
}
return 0;
}大概就是这样。















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









