






LLE(Locally Linear Embedding):局部线性嵌入
思想:在嵌入空间中拟合流行的局部结构
LLE的拓展——KLLE(kernel LLE)、ILLE(inverse LLE)、incremental LLE(增量局部线性嵌入)、Landmark LLE(界标局部线性嵌入)、Supervised LLE(SLLE监督局部线性嵌入)、enhanced SLLE、SLLE projection、probabilistic SLLE、supervised guided SLLE、Robust LLE(利用最小二乘法和惩罚函数)、ISOLLE(与Isomap方法融合)等
最为重要的是weighted LLE(加权LLE)
选择邻域数的方法——残差方差、Procrustes统计量、保邻域误差和局部邻域选择
1.LLE(Locally Linear Embedding)
LLE首次提出在2000年,2000-2003年间有所发展,到2006年文章中提出有三步骤:
(1)找到所有训练点中的k-最近邻图
(2)使用线性组合找到用于通过相邻点重建每个点的权重(即找权重值)
(3)使用找到的相同权重,通过嵌入相邻点的线性组合嵌入每个点(即一个高维到低维的嵌入转换),可以理解为在高维空间中点之间的权重在落入低维嵌入空间后仍旧保持不变的权重
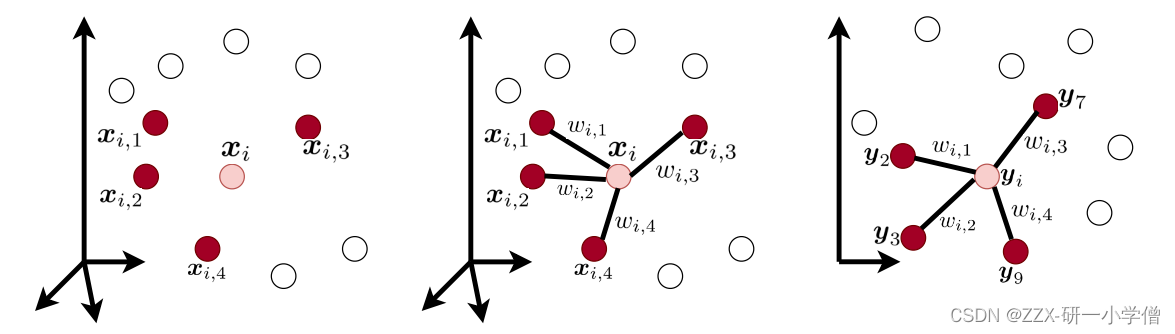
step1:找点(如图1)
计算二维空间上的欧氏距离python代码
def EuclideanDistance(x, y):
import numpy as np
x = np.array(x)
y = np.array(y)
return np.sqrt(np.sum(np.square(x-y)))
step2:计算权重(w)
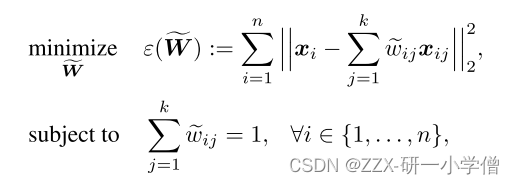
线性重构后每个点的权重总和都为1,因为防止权重爆炸问题,正负权重的相互抵消,最终使得权重总和为1。
根据计算公式可以得到特征值eigenvalue为:

把上面式子里面求出来的eigenvalue代入即可求得权重w为
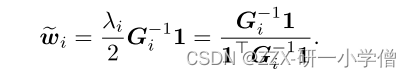
step3:嵌入
从高维数据X嵌入到低维空间中变成Y,通过公式可知就是在找到Y的替换后的eigenvalue和eigenvector,由此得到嵌入后的数据
因此可以知道,LLE的关键就在于找到eigenvalue。
2.KLLE(Kernel Locally Linear Embedding)
KLLE最先于2012年提出,关键是将数据映射到特征空间(类似于KPCA中讲数据映射到高维特征空间道理类似),并在特征空间中执行LLE的几个步骤,因此关键的点在于找到正确或者是合适kernel函数
step1:找点(变成在特征空间上找)
特征空间上的欧几里得距离计算公式:
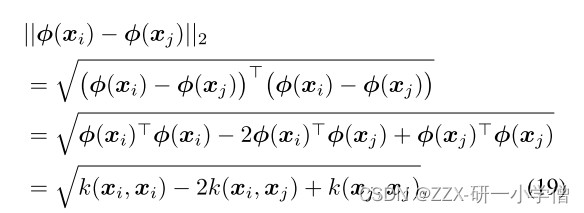
根据公式找到点之后就可以在特征空间中构建出kNN图,同LLE道理,也能在特征空间中找到k个相邻点。
step2:计算权重(相邻重构)
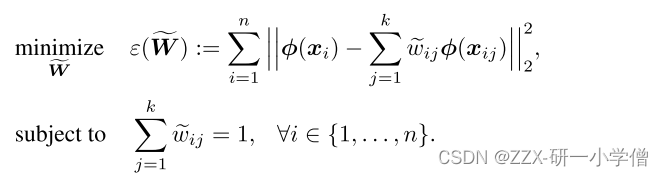

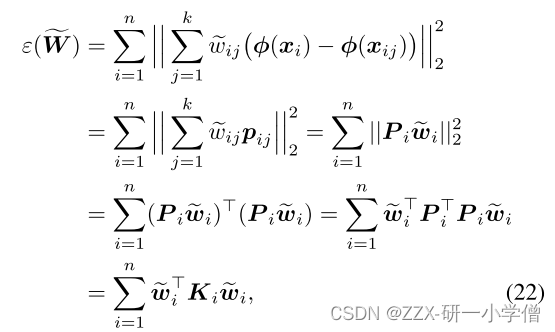
由(22)公式可以知道,最后简化后剩下未知的是Ki,因此我们只需要找到K这个核函数,而Ki可以由下面的公式得到:
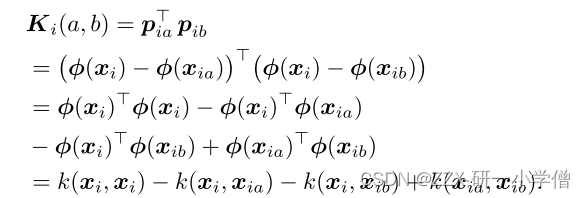
通过拉格朗日求导后求出eigenvalue特征值 ,再把求出来的特征值带入公式中计算出所有的权重值
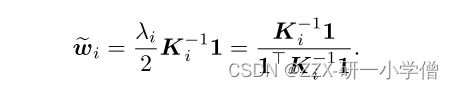
step3:嵌入(同LLE的嵌入步骤)
3.Out-of-sample Embedding in LLE
与LLE不同的是该方法是需要找到样本外的点来进行低维嵌入,而不是通过找到相邻点嵌入
在嵌入的方法中与前面不同的是样本外的嵌入是通过特征函数来实现的,因此需要找到正确的特征函数;最后通过Kernel Mapping进行映射
4.Incremental LLE
2005年提出的Incremental LLE是在使用已嵌入的数据来嵌入新接收的数据的方法,来处理实时更新的在线数据
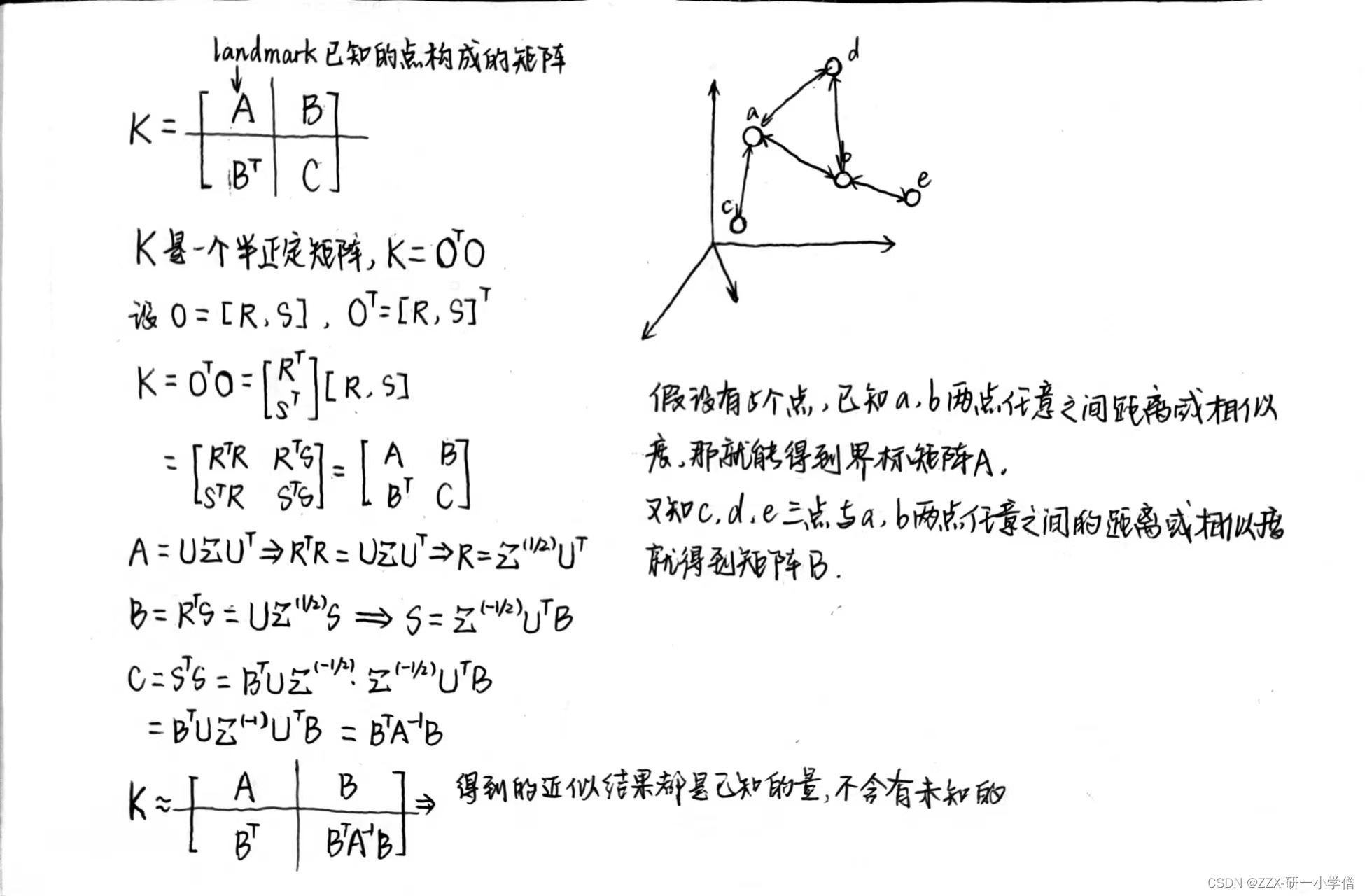
5.Landmark Locally Linear Embedding
由于是LLE处理光谱降维的方法,因此无法处理n>>1的大数据。为了解决这个问题就引入了Landmark LLE方法,使用一些界标的嵌入来近似所有点的嵌入,使用的方法是Nystrom approximation
(1)Nystrom approximation
(2)Kernel approximation
在Nystrom approximation的基础上,Kernel approximation就是将kernel看成是两个嵌入的内积
(3)Locally Linear Landmark(LLL)
先是将n维嵌入数据映射到m维界标,m<<n,然后使用投影矩阵,再去做内积
内容补充——LLE的关键核心代码
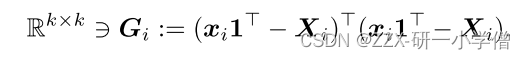
![]()
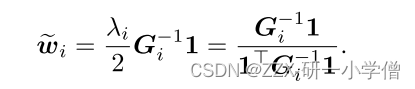
G = ((x.dot(ones_vector.T) - X_neighbors).T).dot(x.dot(ones_vector.T) - X_neighbors)
epsilon = 0.0000001
G = G + (epsilon * np.eye(self.n_neighbors))
numinator = (np.linalg.inv(G)).dot(ones_vector) #分子
denominator = (ones_vector.T).dot(np.linalg.inv(G)).dot(ones_vector) #分母
self.w_linearReconstruction[sample_index, :] = ((1 / denominator) * numinator).ravel()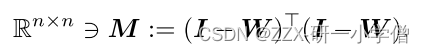
temp = np.eye(self.n_samples) - self.W_linearEmbedding
M = (temp.T).dot(temp)
求M的特征值和特征向量
eig_val, eig_vec = np.linalg.eigh(M)
idx = eig_val.argsort() # sort eigenvalues in ascending order (smallest eigenvalue first)
eig_val = eig_val[idx]
eig_vec = eig_vec[:, idx]
















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











