







写在前面:
- 本系列笔记主要以《计算机操作系统(汤小丹…)》为参考,大部分内容出于此书,笔者的工作主要是挑其重点展示,另外配合下方视频链接的教程展开思路,在笔记中一些比较难懂的地方加以自己的一点点理解(重点基本都会有标注,没有任何标注的难懂文字应该是笔者因为强迫症而加进来的,可选择性地忽略)。
- 视频链接:操作系统(汤小丹等第四版)_哔哩哔哩_bilibili
一、概述
通常文件是由一系列的记录组成的。文件系统设计的关键要素,是将这些记录构成一个文件的方法,以及将一个文件存储到外存上的方法。
任何一个文件都存在以下两种形式的结构:
①文件的逻辑结构。从用户观点出发所观察到的文件组织形式,是用户可以直接处理的数据及其结构,它独立于文件的物理特性,又称为文件组织。
②文件的物理结构。又称为文件的存储结构,是指文件在外存上的存储组织形式。与存储介质的存储性能和采用的外存分配方式有关。
二、文件逻辑结构的类型
1、按文件是否有结构分类
(1)有结构文件:在记录式文件中,每个记录都用于描述实体集中的一个实体,各记录有着相同或不同数目的数据项。记录的长度可分为定长和不定长两类。
(2)无结构文件:这是指由字符流构成的文件,故又称为是流式文件,其文件的长度是以字节为单位的,对流式文件的访问,则是利用读、写指针来指出下一个要访问的字符。(UNIX 系统中,所有的文件都被看做是流式文件)
2、按文件的组织方式分类
(1)顺序文件:指由一系列记录按某种顺序排列所形成的文件,其中的记录可以是定长记录或可变长记录。
(2)索引文件:指为可变长记录文件建立一张索引表,为每个记录设置一个表项,以加速对记录的检索速度。
(3)索引顺序文件:这是顺序文件和索引文件相结合的产物,这里,在为每个文件建立一张索引表时,并不是为每一个记录建立一个索引表项,而是为一组记录中的第一个记录建立一个索引表项。
三、顺序文件
1、顺序文件的排列方式
(1)串结构。在串结构文件中的记录,通常是按存入时间的先后进行排序的,各记录之间的顺序与关键字无关。在对串结构文件进行检索时,每次都必须从头开始逐个记录地查找,直到找到指定的记录或查完所有的记录为止,显然,对串结构文件进行检索是比较费时的。
(2)顺序结构。由用户指定一个字段作为关键字,它可以是任意类型的变量,其中最简单的是正整数,如0到N-1,为了能唯一地标识每一个记录,必须使每个记录的关键字值在文件中具有唯一性,这样,文件中的所有记录就可以按关键字来排序,可以按关键字的大小进行排序,或按其英文字母顺序排序。在对顺序结构文件进行检索时,还可以利用某种有效的查找算法,如折半查找法、插值查找法、跳步查找法等方法提高检索效率,故顺序结构文件可有更高的检索速度和效率。
2、顺序文件的优缺点
(1)优点:
①顺序文件的最佳应用场合是在对诸记录进行批量存取时,即每次操作一大批记录。
②所有逻辑文件中顺序文件的存取效率是最高的。
③对于顺序存储设备(如磁带),也只有顺序文件才能被存储并能有效地工作。
(2)缺点:
①在交互应用的场合,如果进程操作对象是单个记录,顺序文件的性能就可能很差,当文件较大时更差。
②增加或删除一个记录都比较困难。
③可变长记录的顺序文件无法实现随机存取,每次查询只能从头依次查找。
3、记录寻址
(1)隐式寻址方式:
①对于定长记录的顺序文件,如果已知当前记录的逻辑地址,便很容易确定下一个记录的逻辑地址。在读一个文件时,为了读文件,在系统中应设置一个读指针Rptr,令它指向下一个记录的首地址,每当读完一个记录时,便执行Rptr= Rptr +L 操作,使之指向下一个记录的首地址,其中的L为记录长度;类似地,为了写文件,也应设置一个写指针Wptr,使之指向要写的记录的首地址,同样,在每写完一个记录时,又须执行操作Wptr= Wptr +L。
②对于变长记录的顺序文件,与顺序读或写时的情况相似,只是每次都需要从正在读(写)的记录中读出该记录的长度。同样需要分别为它们设置读或写指针,但在每次读或写完个记录后,须将读或写指针加上,
是刚读或刚写完的记录的长度。
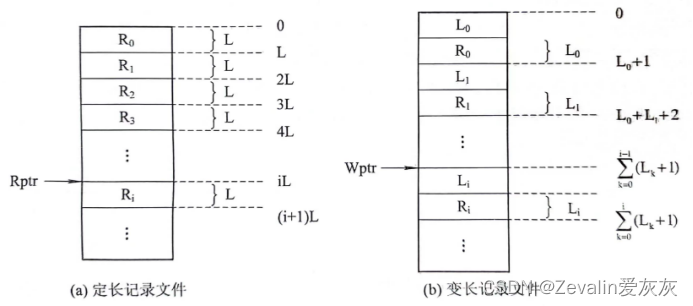
③这种顺序访问的方式可用于所有文件类型,其主要问题是,访问一个指定记录i,必须扫描或读取前面i-1个记录,访问速度是比较慢的。
(2)显式寻址方式:
①该方式可用于对定长记录的文件实现直接或随机访问,因为任何记录的位置都很容易通过记录长度计算出来;而对于可变长度记录的文件则不能利用显式寻址方式实现直接或随机访问,必须增加适当的支持机构方能实现。
②通过文件中记录的位置实现随机访问:
[1]对定长记录文件,在文件中的每一个记录可用从0到N-1的整数来标识,即用一个整数来唯一地标识一个记录,如果要查找第i个记录,可直接根据式计算,获得第i个记录相对于第一个记录首址的地址。
[2]对不定长记录文件,要查找其中的第i个记录时须首先计算出该记录的首地址,为此,须顺地查找每个记录,从中获得相应记录的长度,然后才能按式
计算出第i个记录的首址(假定在每个记录前用一个字节指明该记录的长度,所以要“+1”)。
③利用关键字实现随机访问:
此时用户必须指定一个字段作为关键字,通过指定的关键字来查找该记录。当用户给出要检索记录的关键字时,系统将利用该关键字顺序地从第一个记录开始,与每一个记录的关键字进行比较,直到找到匹配的记录。
四、索引文件
1、按关键字建立索引
定长记录的文件可以通过简单的计算,很容易地实现随机查找,但变长记录文件查找一个记录必须从第一个记录查起,一直顺序查找到目标记录为止,耗时很长,这时可以为变长记录文件建立一张索引表,为主文件中的每个记录在索引表中分别设置一个表项,记录指向记录的指针(即记录在逻辑地址空间的首址)以及记录的长度L,索引表按关键字排序,因此其本身也是一个定长记录的顺序文件,这样就把对变长记录顺序文件的顺序检索转变为对定长记录索引文件的随机检索,从而加快对记录检索的速度,实现直接存取。
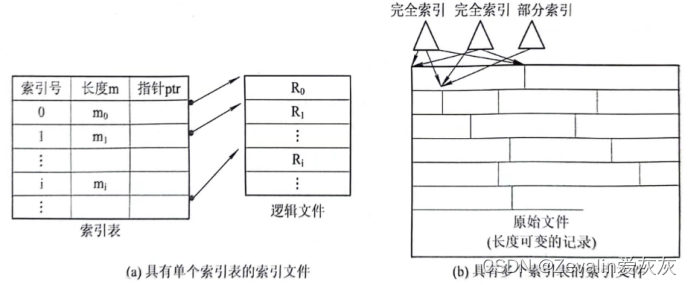
由于是按关键字建立的索引,所以在对索引文件进行检索时,可以根据用户(程序)提供的关键字利用折半查找法去检索索引表,从中找到相应的表项,再利用该表项中给出的指向记录的指针值去访问所需的记录。每当要向索引文件中增加一个新记录时,须对索引表进行修改。
2、具有多个索引表的索引文件
不同的用户,为了不同的目的,希望能按不同的属性(或不同的关键字)来检索一条记录。为实现此要求,需要为顺序文件建立多个索引表,即为每一种可能成为检索条件的域(属性或关键字)都配置一张索引表,在每一个索引表中,都按相应的一种属性或关键字进行排序。
五、索引顺序文件
1、一级索引顺序文件
最简单的索引顺序文件只使用了一级索引,其具体的建立方法是,首先将变长记录顺序文件中的所有记录分为若干个组,然后为顺序文件建立一张索引表,并为每组中的第一个记录在索引表中建立一个索引项,其中含有该记录的关键字和指向该记录的指针。
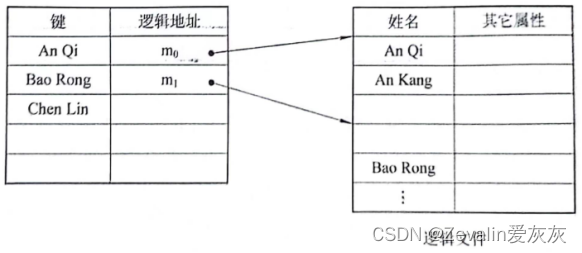
在对索引顺序文件进行检索时,首先也是利用用户(程序)所提供的关键字以及某种查找算法去检索索引表,找到该记录所在记录组中第一个记录的表项,从中得到该记录组第一个记录在主文件中的位置,然后再利用顺序查找法去查找主文件,从中找到所要求的记录。
2、两级索引顺序文件
为了进一步提高检索效率,可以为顺序文件建立多级索引,即为索引文件再建立一张索引表,从而形成两级索引表。
六、直接文件和哈希文件
1、直接文件
采用前述几种文件结构对记录进行存取时,都须利用给定的记录键值,先对线性表进行检索,以找到指定记录的物理地址。然而对直接文件,则可根据给定的记录键值,直接获得指定记录的物理地址。换言之,记录键值本身就决定了记录的物理地址,组织直接文件的关键,在于用什么方法进行从记录值到物理地址的转换。
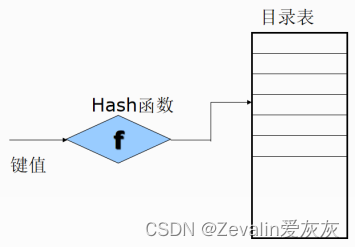
2、哈希文件
利用Hash函数(或称散列函数)可将关键字转换为相应记录的地址,但为了能实现文件存储空间的动态分配,通常由Hash函数所求得的并非是相应记录的地址,而是指向某一日录表相应表目的指针,该表目的内容指向相应记录所在的物理块。
例如,若令K为记录键值,用A作为通过Hash函数H的转换所形成的该记录在目录表中对应表目的位置,则有关系A=H(K)。通常把Hash函数作为标准函数存于系统中,供存取文件时调用。
















 9838
9838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











