









学习textRNN网络
参考论文中的模型,可以看出卷积神经网络不仅在图像处理方向可以有优秀的表现,同时在文本处理中也可以把词向量输入提取特征。但是在这时需要的中文进行一个预处理,然后用词向量进行表示。对于正常而言的CNN中的卷积核,textCNN的卷积核的宽度一般和词向量的维度一样,图上的维度是6 。卷积核的高度一般设置为2-6的范围。

在另外的一篇论文A Sensitivity Analysis of (and Practitioners’ Guide to) ConvolutionalNeural Networks for Sentence Classification中给出的模型结构更加清楚易懂些,这里也作为学习textCNN的资料

将训练好的模型进行保存,并且输入电影评论,查看输出会是怎样的
三:解决方案
(一)开发环境:pycharm+python3.5
(二)整个项目需要导入的代码:
import numpy as np
import random as rn
np.random.seed(0)
rn.seed(0)
import matplotlib.pyplot as plt
import jieba
import gensim
import os
import time
from collections import Counter
import tensorflow as tf
tf.random.set_seed(0)
import tensorflow.keras as kr
import tensorflow.keras as keras
from tensorflow.keras import layers
from numba import cuda
(三)函数和网络结构设计:一次训练数据设置为100(视电脑性能决定),epoch初始设置为3次,drop=0.1,用softmax激活处理,随后为了提高准确度可以对以上的参数进行更改。
网络结构主要使用简单cnn网络、多核卷积网络和LSTM网络进行比较
损失函数使用的多分类损失函数
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[‘accuracy’]
)
对训练模型进行预测
网络结构主要使用简单cnn网络、多核卷积网络和LSTM网络进行比较
#构建模型
num_features = 59290
sequence_length = 50
embedding_dimension = 100
def cnn():
model = kr.Sequential([
layers.Embedding(input_dim=num_features, output_dim=embedding_dimension, input_length=sequence_length),
layers.Conv1D(filters=50, kernel_size=5, strides=1, padding=‘valid’),
layers.MaxPool1D(2, padding=‘valid’),
layers.Flatten(),
layers.Dense(10, activation=‘relu’),
layers.Dense(2, activation=‘sigmoid’)
])
model.compile(optimizer=kr.optimizers.Adam(1e-3),
loss=kr.losses.BinaryCrossentropy(),
metrics=[‘accuracy’])
return model
model = cnn()
model.summary()
history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)
plt.plot(history.history[‘accuracy’])
plt.plot(history.history[‘val_accuracy’])
plt.legend([‘training’, ‘valiation’], loc=‘upper left’)
plt.show()
#model = tf.keras.Sequential([
词嵌入层
tf.keras.layers.Embedding(input_dim=num_features, output_dim=embedding_dimension, input_length=sequence_length),
第一个LSTM层
tf.keras.layers.LSTM(125, dropout=0.5, return_sequences=True),
第二个LSTM层
tf.keras.layers.LSTM(125, dropout=0.5, return_sequences=True),
利用TimeDistributed对每个时间步的输出都做Dense操作(softmax激活)
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(2, activation=‘softmax’)),
])
model.summary()
class ShowSaveCallback(tf.keras.callbacks.Callback):
def __init__(self):
super().__init__()
self.loss = float(“inf”) # 给一个初始最大值
def on_epoch_end(self, epoch, logs=None): # 保留损失最低的模型
if logs[‘loss’] <= self.loss:
self.loss = logs[‘loss’]
model.save("./qingganfenxi.h5")
print()
model.compile(optimizer=tf.keras.optimizers.Adam(),loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[‘accuracy’]
)
history=model.fit((x_train,y_train), steps_per_epoch=1111,epochs=3) # 开始训练
plt.plot(history.history[‘accuracy’]) #训练可视化
#plt.legend([‘train’],loc=‘upper left’)
#plt.show()
#plt.plot(history.history[‘loss’], label=‘train loss’)
#plt.legend()
#plt.show()
#model.save(‘qingganfenxi.h5’) # 保存模型
filter_sizes = [3, 4, 5]
def convolution():
inn = layers.Input(shape=(sequence_length, embedding_dimension, 1))
cnns = []
for size in filter_sizes:
conv = layers.Conv2D(filters=64, kernel_size=(size, embedding_dimension),
strides=1, padding=‘valid’, activation=‘relu’)(inn)
pool = layers.MaxPool2D(pool_size=(sequence_length - size + 1, 1), padding=‘valid’)(conv)
cnns.append(pool)
outt = layers.concatenate(cnns)
model = keras.Model(inputs=inn, outputs=outt)
return model
def cnn_mulfilter():
model = keras.Sequential([
layers.Embedding(input_dim=num_features, output_dim=embedding_dimension,
input_length=sequence_length),
layers.Reshape((sequence_length, embedding_dimension, 1)),
convolution(),
layers.Flatten(),
layers.Dense(10, activation=‘relu’),
layers.Dropout(0.2),
layers.Dense(2, activation=‘sigmoid’)
])
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.BinaryCrossentropy(),
metrics=['accuracy'])
return model
model = cnn_mulfilter()
model.summary()
四:实验分析和总结
数据集介绍:从课程网站可以下载数据集,形式如下图,前面有情感的编号,如果是负面的就输出1,正面的就输出0.

同时数据处理中对于中文数据需要编码排序,用词向量进行表示,随后再用编码后的数据进行替代;数据集中存在一些英文和繁体字,如果自己处理的话需要删除然后转换为简体字;但是用实验报告中的方法,似乎不要这样做也可以获得正确的编码
(1)实验结果分析:
使用简单的CNN网络对训练集跑3次之后的结果


然后加上测试集跑3次之后的结果

最后的损失和精确度

使用多核卷积模型对训练集跑3次后的训练的结果


然后加上测试集跑3次之后的结果

最后的损失和精确度

使用LSTM跑3次后的结果:


最后的损失和精确度

评估结果

混淆矩阵
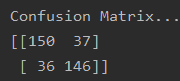
验证模型:


(三)总结:
本实验基本完成课程设计要求,使用简单CNN网络训练三次后大概可以保持0.82左右的准确率,使用多核卷积网络训练以后大概可以保持0.86左右的准确度,使用LSTM训练三次后大概可以保持0.8的准确度,本实验只训练了三个回合的原因在于从得到的可视化图像来看,因为文本数据不是很多,倾向于出现了过拟合的情况。最后使用保存的模型对自己输入的评论进行预测,可以看到,可以对简单的电影评论进行分类















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









