






强化学习 qlearning解决tsp问题
前言
学习参考网上qlearning算法解决tsp问题的程序,自己从头编写一套代码,如有疑问或建议,欢迎留言,谢谢!
下面是全部完整的程序,下载了用到的第三方库就可以直接run通,程序从main处运行,
由地图类、Qlearn类以及main组成,可参考程序中的注释,
若有疑问和建议欢迎留言讨论,若对阁下有帮助,请点个赞呗,谢谢!
【2023.12.12】采用python3.10 CPU i5 13490;显卡 七彩虹 4070
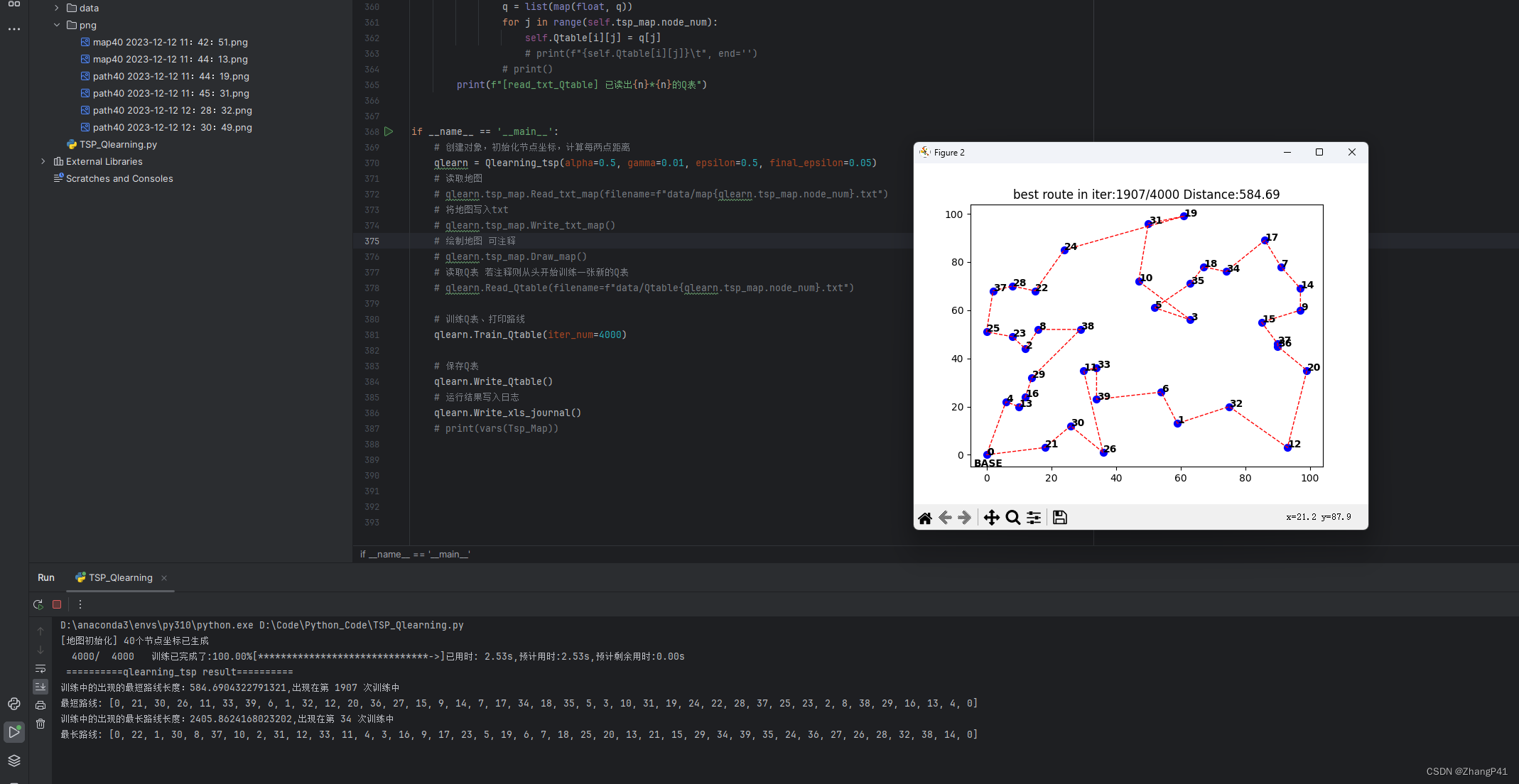
运行结果如下
源程序
# coding=utf-8
# author:ZP
# create_date:2022/10/31 13:41
# brief:qlearning处理TSP问题。包含Map类和Qlearning类
import numpy as np
import math
import time
import matplotlib.pyplot as plt
import os
# 地图类 存储地图尺寸、节点数量、节点坐标、[节点间距离]的信息
# 随机生成新地图、打开本地地图、存储地图、绘制地图、计算节点间距离
class Tsp_Map:
# 初始化地图尺寸、节点数量、节点坐标,并计算节点间距离
def __init__(self, map_size=100, node_num=40): # traffic_intensity交通堵塞强度
# np.random.seed(0) # 随机数种子
self.map_size = map_size # 地图尺寸
self.node_num = node_num # 节点数量
self.Init_coords() # 初始化节点坐标
self.Calc_distances_table() # 计算各个节点间距离
# 初始化节点坐标-随机产生
def Init_coords(self):
self.base_coord = [0, 0] # 起点坐标
self.coords = [[0, 0]] # 每个节点位置坐标
self.coord_x, self.coord_y = [self.base_coord[0]], [self.base_coord[1]]
# 随机产生另外node_num-1个坐标
for i in range(self.node_num - 1):
x, y = np.random.randint(0, self.map_size, size=2)
while [x, y] in self.coords:
x, y = np.random.randint(0, self.map_size, size=2)
self.coord_x.append(x)
self.coord_y.append(y)
self.coords.append([x, y])
print("[地图初始化] {}个节点坐标已生成".format(self.node_num))
# 计算节点间距离形成距离表-根据节点坐标、节点数量
def Calc_distances_table(self):
self.distances_table = np.zeros((self.node_num, self.node_num), dtype=float)
for a in range(self.node_num):
for b in range(a + 1, self.node_num):
self.distances_table[a][b] = self.Calc_distance(self.coords[a], self.coords[b])
self.distances_table[b][a] = self.distances_table[a][b]
# 计算两点间距离
def Calc_distance(self, a, b):
d = math.sqrt(pow(a[0] - b[0], 2) + pow(a[1] - b[1], 2))
return d
# 将地图尺寸、节点数、节点坐标写入txt文件
def Write_txt_map(self):
filename = f"data/map{self.node_num}.txt"
try:
os.mkdir(os.getcwd() + "/" + "data") # 创建指定名称的文件夹
print("[write_txt_map] data文件夹创建成功")
except:
print("[write_txt_map] data文件夹已存在")
with open(filename, 'w') as f:
f.write("{}\t{}\n".format(self.map_size, self.node_num))
print("{} {}".format(self.map_size, self.node_num))
for i in range(self.node_num):
f.write("{}\t{} {}\n".format(i + 1, self.coord_x[i], self.coord_y[i]))
print("{}\t{} {}".format(i + 1, self.coord_x[i], self.coord_y[i]))
print("[write_txt_map] 已写入{}个坐标".format(self.node_num))
# 从txt文件从读取地图尺寸、节点数、节点坐标,并更新距离表
def Read_txt_map(self, filename="data/map.txt"):
with open(filename, "r") as f:
info = f.readline()
[size, num] = info.split()
self.map_size, self.node_num = map(int, [size, num])
print("{} {}".format(self.map_size, self.node_num))
coord = f.readline()
while coord:
[i, x, y] = coord.split()
[i, x, y] = map(int, [i, x, y])
print("{}\t{} {}".format(i, x, y))
self.coords[i - 1] = ([x, y])
self.coord_x[i - 1] = x
self.coord_y[i - 1] = y
coord = f.readline()
self.Calc_distances_table()
print("[read_txt_map] 已读取{}个坐标".format(self.node_num))
# 绘制地图 根据节点坐标
def Draw_map(self):
plt.figure(3)
# 标题
plt.title("node_num: {}".format(self.node_num))
# 画上所有节点
plt.scatter(self.coord_x, self.coord_y, c="blue", s=50)
# 地图上标注 BASE点
xy = self.base_coord # 得到基地坐标
xytext = xy[0] - 2, xy[1] - 3
# 标注文字
plt.annotate("BASE", xy=xy, xytext=xytext, weight="bold")
# Show 火源点序号、连线
x, y = [], []
for i in range(self.node_num):
x.append(self.coord_x[i])
y.append(self.coord_y[i])
xy = (self.coord_x[i], self.coord_y[i])
# 文字标注位置为右下方
xytext = xy[0] + 0.1, xy[1] - 0.05
# 标注文字
plt.annotate(str(i), xy=xy, xytext=xytext, weight="bold")
# plt.plot(x, y, c="green", linewidth=1, linestyle="--")
try:
os.mkdir(os.getcwd() + "/" + "png") # 创建指定名称的文件夹
print("[Draw_map] png文件夹创建成功")
except:
print("[Draw_map] png文件夹已存在")
timestr = time.strftime("%Y-%m-%d %H:%M:%S")
save_path = f"png/map{self.node_num} {timestr}"
plt.savefig(save_path + '.png', format='png')
print("[draw map] 地图已保存")
plt.show()
# 强化学习Qlearning算法。
# 定义算法中的训练参数、Q表、奖励表、动作空间、最优/最差路线记录器、动作空间;
# 实现Qlearning算法流程、选择动作、状态转移、绘制路线、绘制训练效果图、记录运行日志、打开本地Q表、存储Q表。
class Qlearning_tsp:
# 初始化dqn算法参数和地图信息
def __init__(self, gamma=0.3, alpha=0.3, epsilon=0.9, final_epsilon=0.05):
self.tsp_map = Tsp_Map(map_size=100, node_num=40) # 创建地图类对象
self.actions = np.arange(0, self.tsp_map.node_num) # 创建并初始化动作空间
self.Qtable = np.zeros((self.tsp_map.node_num, self.tsp_map.node_num)) # 创建并初始化q表
# 记录训练得到的最优路线和最差路线
self.good = {'path': [0], 'distance': 0, 'episode': 0}
self.bad = {'path': [0], 'distance': 0, 'episode': 0}
self.gamma = gamma # 折扣银子
self.alpha = alpha # 学习率
self.epsilon = epsilon # 初始探索率
self.final_epsilon = final_epsilon # 最终学习率
# 训练智能体 s a r s
def Train_Qtable(self, iter_num=1000):
# 训练参数
gamma = self.gamma # 折扣因子
alpha = self.alpha # 学习率
epsilon = self.epsilon # 初始探索率
t1 = time.perf_counter() # 用于进度条
qvalue = self.Qtable.copy()
plot_dists = []
plot_iter_nums = [] # 用于绘训练效果图,横坐标集合
self.iter_num = iter_num
# 大循环-走iter_num轮
for iter in range(iter_num):
path = [] # 重置路线记录
s = 0 # 初始化状态到起点
path.append(s)
flag_done = False # 完成标志
round_dist = 0 # 本轮距离累加统计
# 小循环-走一轮
while flag_done == False: # 没完成
a = self.Choose_action(path, epsilon, qvalue)
s_next, r, flag_done = self.Transform(path, a)
# round_reward += r
round_dist += self.tsp_map.distances_table[s, a]
path.append(s_next)
# 更新Qtable
if flag_done == True: # path包含全部状态时flag_done=True
q_target = r
qvalue[s, a] = qvalue[s, a] + alpha * (q_target - qvalue[s, a])
break
else:
a1 = self.greedy_policy(path, qvalue)
q_target = r + gamma * qvalue[s_next, a1]
# q_target = r + gamma * np.max(qvalue[s_next,:])
qvalue[s, a] = qvalue[s, a] + alpha * (q_target - qvalue[s, a])
s = s_next # 状态转移
# 每一轮探索率epsilon衰减一次
if epsilon > self.final_epsilon:
epsilon *= 0.997
# epsilon -=(self.epsilon-self.final_epsilon)/iter_num
plot_iter_nums.append(iter + 1)
plot_dists.append(round_dist) # 绘训练效果图-记录每轮总距离-作为纵坐标
# if round_reward >= np.max(self.rewards):
# 记录最好成绩和最坏成绩
if round_dist <= np.min(plot_dists):
self.Qtable = qvalue.copy() # 记录最优成绩对应的Q表,可能和最优路线不对应,因为存在探索
self.good['path'] = path.copy()
self.good['distance'] = round_dist
self.good['episode'] = iter + 1
if round_dist >= np.max(plot_dists):
self.bad['path'] = path.copy()
self.bad['distance'] = round_dist
self.bad['episode'] = iter + 1
# 训练进度条
percent = (iter + 1) / iter_num
bar = '*' * int(percent * 30) + '->'
delta_t = time.perf_counter() - t1
pre_total_t = (iter_num * delta_t) / (iter + 1)
left_t = pre_total_t - delta_t
print('\r{:6}/{:6}\t训练已完成了:{:5.2f}%[{:32}]已用时:{:5.2f}s,预计用时:{:.2f}s,预计剩余用时:{:.2f}s'
.format((iter + 1), iter_num, percent * 100, bar, delta_t,
pre_total_t, left_t), end='')
# 打印训练结果
print('\n', "qlearning_tsp result".center(40, '='))
print('训练中的出现的最短路线长度:{},出现在第 {} 次训练中'.format(self.good['distance'], self.good['episode']))
print("最短路线:", self.good['path'])
print('训练中的出现的最长路线长度:{},出现在第 {} 次训练中'.format(self.bad['distance'], self.bad['episode']))
print("最长路线:", self.bad['path'])
# 画训练效果图
# self.Plot_train_process(plot_iter_nums, plot_dists)
# 画路线图
self.Plot_path(self.good['path'])
# 画路线图
# if show_path is True:
# if iter_num[-1] % render_each == 0:
# img = self.DT_plt_path(iter_num[-1])
# img.savefig(save_path + str(iter) + '.png', format='png')
# Show rewards
def Plot_train_process(self, iter_nums, dists):
# plt.ion()
plt.figure(1)
# plt.subplot(212)
plt.title(f"qlearning node_num:{self.tsp_map.node_num}")
plt.ylabel("distance")
plt.xlabel("iter_order")
plt.plot(iter_nums, dists, color='blue')
try:
os.mkdir(os.getcwd() + "/" + "png") # 创建指定名称的文件夹
print("[Plot_train_process] png文件夹创建成功")
except:
pass
# print("[Plot_train_process] png文件夹已存在")
timestr = time.strftime("%Y-%m-%d %H:%M:%S")
save_path = f"png/process{self.tsp_map.node_num} {timestr}"
plt.savefig(save_path + '.png', format='png')
# plt.show()
def Plot_path(self, path):
plt.figure(2)
# plt.subplot(211)
# 标题
plt.title("best route in iter:{}/{}".format(self.good['episode'], self.iter_num) +
" Distance:" + "{:.2f}".format(self.good['distance']))
# 画上节点
plt.scatter(self.tsp_map.coord_x, self.tsp_map.coord_y, c="blue", s=50)
# 地图上标注 BASE点
if len(self.good['path']) > 0:
xy = self.tsp_map.base_coord # 得到基地坐标
xytext = xy[0] - 4, xy[1] - 5
plt.annotate("BASE", xy=xy, xytext=xytext, weight="bold")
# Show 火源点序号、连线
if len(self.good['path']) > 1:
x, y = [], []
for i in path:
x.append(self.tsp_map.coord_x[i])
y.append(self.tsp_map.coord_y[i])
xy = (self.tsp_map.coord_x[i], self.tsp_map.coord_y[i])
xytext = xy[0] + 0.1, xy[1] - 0.05
plt.annotate(str(i), xy=xy, xytext=xytext, weight="bold")
plt.plot(x, y, c="red", linewidth=1, linestyle="--")
try:
os.mkdir(os.getcwd() + "/" + "png") # 创建指定名称的文件夹
print("[Plot_path] png文件夹创建成功")
except:
pass
# print("[Plot_path] png文件夹已存在")
timestr = time.strftime("%Y-%m-%d %H:%M:%S")
# save_path = f"png/process&path{self.tsp_map.node_num} {timestr}"
save_path = f"png/path{self.tsp_map.node_num} {timestr}"
plt.savefig(save_path + '.png', format='png')
plt.show()
# 和环境交互返回(s,a)下的reward和flag_done
def Transform(self, path, action):
# self.reward_table = self.tsp_map.distances_table.copy()#奖励表,根据距离表修改数值
# self.reward_table = 100*(self.tsp_map.distances_table / np.max(self.tsp_map.distances_table))
# self.reward_table = np.exp(self.tsp_map.distances_table / np.max(self.tsp_map.distances_table))
# reward = -np.exp(self.tsp_map.distances_table[path[-1]][action]/np.max(self.tsp_map.distances_table))
reward = -10000 * (self.tsp_map.distances_table[path[-1]][action] / np.max(self.tsp_map.distances_table))
# reward = -self.tsp_map.distances_table[int(path[-1]), action]
if len(path) == self.tsp_map.node_num and action == 0:
return action, reward, True
return action, reward, False
# 选择动作-episilon-greedy方法
def Choose_action(self, path, epsilon, qvalue):
# 判断是否完成
if len(path) == self.tsp_map.node_num: # 若path中包含了全部的状态则返回原点
return 0
q = np.copy(qvalue[path[-1], :])
if np.random.rand() > epsilon:
q[path] = -np.inf # Avoid already visited states
a = np.argmax(q) # 执行学习到的最优决策
else:
a = np.random.choice([x for x in self.actions if x not in path]) # 在没走过的节点中选一个
return a
def greedy_policy(self, path, qvalue):
if len(path) >= self.tsp_map.node_num: # 如果所有点全部遍历完,只返回基地
return 0
q = np.copy(qvalue[path[-1], :])
q[path] = -np.inf # Avoid already visited states
a = np.argmax(q)
return a
# 将训练日志写入xls-包含地图信息、qlearning参数、训练出的路径、训练结果
def Write_xls_journal(self):
try:
os.mkdir(os.getcwd() + "/" + "data") # 创建指定名称的文件夹
print("[Write_xls_journal] data文件夹创建成功")
except:
pass
# print("[Write_xls_journal] data文件夹已存在")
timestr = time.strftime("%Y-%m-%d %H:%M:%S")
filename = "data/journal.xls"
with open(filename, 'a') as f:
f.write(f"{timestr}\t")
# print(f"{timestr}")
f.write("{}\t{}\t".format(self.tsp_map.map_size, self.tsp_map.node_num))
# print("{} {}".format(self.tsp_map.map_size, self.tsp_map.node_num))
f.write(f"{self.alpha}\t{self.gamma}\t{self.epsilon}\t{self.final_epsilon}\t{self.iter_num}\t"
f"{self.good['distance']}\t{self.good['episode']}\t{self.good['path']}\n")
# print(f"{self.alpha}\t{self.gamma}\t{self.epsilon}\t{self.iter_num}\t{self.good['distance']}\t{self.good['episode']}\t{self.good['path']}")
print("[Write_xls_journal] 已写入日志".format(self.tsp_map.node_num))
# 将Q表存入本地
def Write_Qtable(self):
try:
os.mkdir(os.getcwd() + "/" + "data") # 创建指定名称的文件夹
print("[write_txt_Qtable] data文件夹创建成功")
except:
pass
# print("[write_txt_Qtable] data文件夹已存在")
filename=f"data/Qtable{self.tsp_map.node_num}.txt"
with open(filename, 'w') as f:
f.write(f"{self.tsp_map.node_num}\n")
# print(f"{self.tsp_map.node_num}")
for i in range(self.tsp_map.node_num):
for j in range(self.tsp_map.node_num):
f.write(f"{self.Qtable[i][j]}\t")
# print(f"{self.Qtable[i][j]}\t",end='')
f.write("\n")
# print()
print(f"[write_txt_Qtable] 已写入{self.tsp_map.node_num}*{self.tsp_map.node_num}的Q表")
# 从本地读取Q表
def Read_Qtable(self, filename="data/Qtable.txt"):
with open(filename, 'r') as f:
n = f.readline()
n = int(n)
# print(f"{self.tsp_map.node_num}")
if n != self.tsp_map.node_num:
print("Q表和地图不匹配")
return 0
for i in range(self.tsp_map.node_num):
q = f.readline()
q = q.split()
q = list(map(float, q))
for j in range(self.tsp_map.node_num):
self.Qtable[i][j] = q[j]
# print(f"{self.Qtable[i][j]}\t", end='')
# print()
print(f"[read_txt_Qtable] 已读出{n}*{n}的Q表")
if __name__ == '__main__':
# 创建对象,初始化节点坐标,计算每两点距离
qlearn = Qlearning_tsp(alpha=0.5, gamma=0.01, epsilon=0.5, final_epsilon=0.05)
# 读取地图
# qlearn.tsp_map.Read_txt_map(filename=f"data/map{qlearn.tsp_map.node_num}.txt")
#将地图写入txt
# qlearn.tsp_map.Write_txt_map()
#绘制地图 可注释
# qlearn.tsp_map.Draw_map()
# 读取Q表 若注释则从头开始训练一张新的Q表
# qlearn.Read_Qtable(filename=f"data/Qtable{qlearn.tsp_map.node_num}.txt")
# 训练Q表、打印路线
qlearn.Train_Qtable(iter_num=4000)
# 保存Q表
qlearn.Write_Qtable()
# 运行结果写入日志
qlearn.Write_xls_journal()
# print(vars(Tsp_Map))
---














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









