







本文为 Russell A. Poldrack 的统计学课程的讲义 Statistical Thinking for the 21st Century 的读书摘录。
课程讲义:Statistical Thinking for the 21st Century
可靠性(reliability)、有效性(validity)
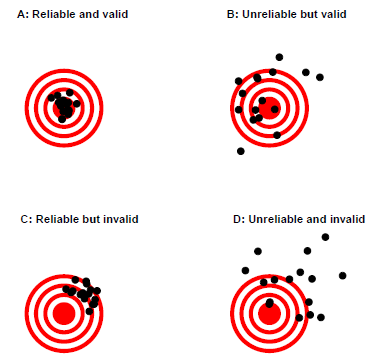
结构有效性(construct validity):
收敛有效性(convergent validity):对同一结构(construct)的不同测量(measurement)须紧密相关(related)
例:测试一个人的外向程度,有两种测试方式,问卷和采访。
发散有效性(divergent validity):对不同结构的测量须呈无关
例:对一个人的外向程度和责任心的测试
预测有效性(predictive validity):
如果一个测量有效,则应对其他结果也有预测价值。
例:一个人寻求刺激(追求新体验)的欲望,与其在现实生活中的冒险程度。
序级变量(ordinal variable)
序级变量可以给出一个相对的量级信息,但相邻两级之间的差值未必相等。
对序级变量求平均值,可能是很多研究者的通行做法,但这有时会出问题。
例:
某人每天对某种慢性疼痛程度的评估,1 - 7 等级,6 级疼痛未必是 3 级疼痛的两倍。
类似地,对人的性格测试也是如此。
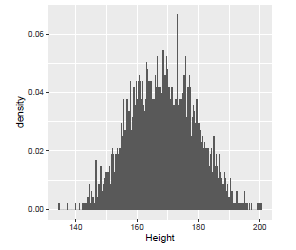
直方图(histogram)
下图为成年人身高的统计图,整体近似呈正态分布,但并不意味着,相邻身高值的样本数量一定相近。
例如,173.2cm 出现了 32 次,173.3cm 只出现了 15 次。
数据可视化(data visualisation)
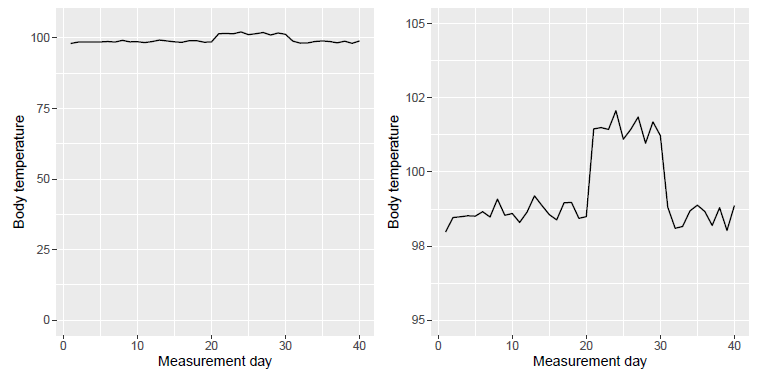
y 轴的零点:
Darrell Huff 的 How to lie with statistics 一书中声称,统计图的 y 轴须包含零点,但实际上,很多情况下,零点毫无意义。
例:对人的体温的统计,如包含零点,则原本明显的体温变化可能会显得毫无波澜。
感知局限(perceptual limitations):
- 只有颜色对比的统计图,对色盲人群不友好:
- 饼状图(pie chart):可能会使人难以准确地感知各部分的大小差异
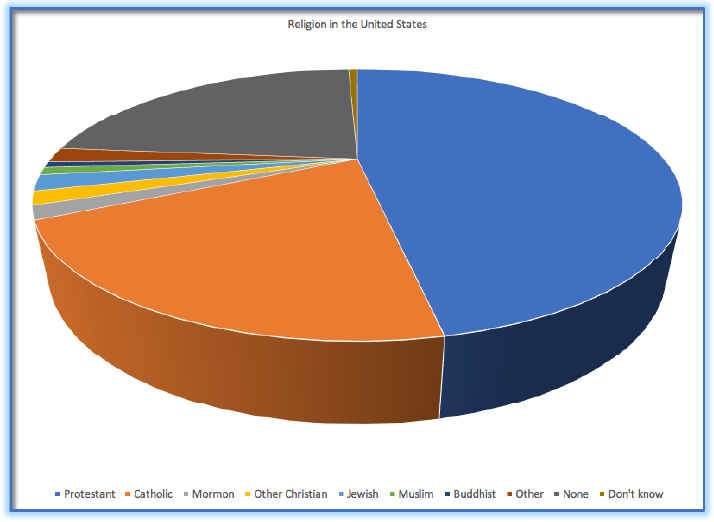
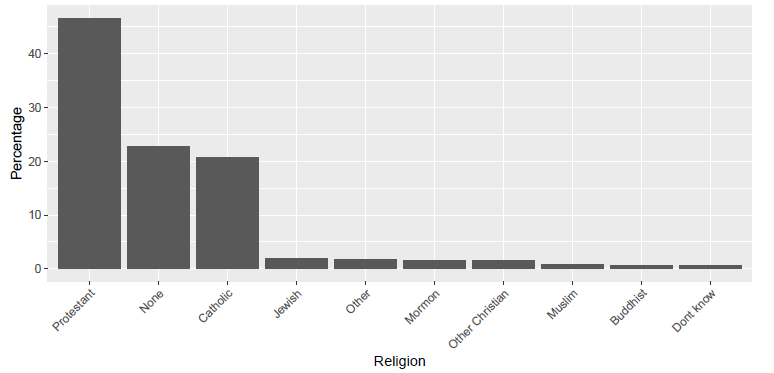
如上图所示,深灰色部分(None)的数量,实际上多于橙色部分(Catholic)。

拟合(fitting)
统计学家 George Box 曾说:所有的模型都是错的,但是有些是有用的。
"All models are wrong but some are useful."
把统计建模看作是,观测数据是如何生成的理论,是一种有益的态度。
然后我们的目标就变成了,找到这样一个模型,它可以最高效且准确地总结数据的实际生成方式。
但我们将会看到,对高效性和准确性的欲望,是自相矛盾的。
统计学总是要做权衡。
"Statistics is all about tradeoffs."
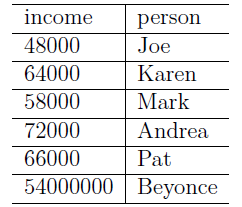
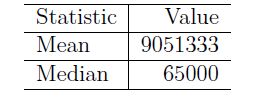
平均值(mean)、中位数(median):
以平均值作为估计值,方差最小,但对离群值(极端值)敏感;
以中位数作为估计值,绝对偏差最小,对离群值较不敏感(方差的平方操作会加剧极端数值的影响)。
例:几个人的收入的平均值和中位数:
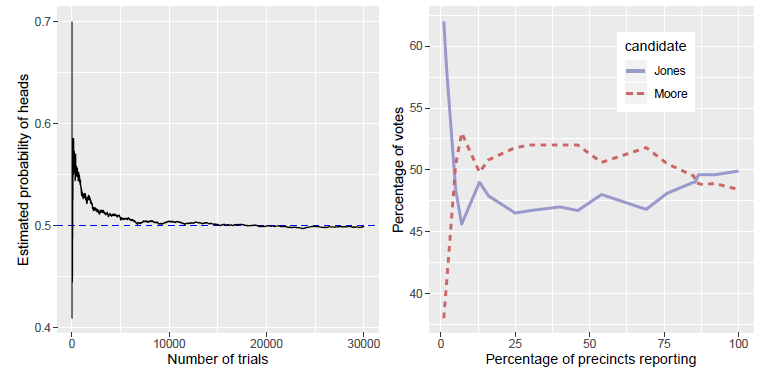
大数定律(law of large numbers)、小数定律(law of small numbers)
大数定律的前提条件是样本量足够大,然而很多人常常忘记这一点,过度诠释了小样本的结果。
鉴于人们(甚至是受过训练的研究者)经常对小样本应用大数定律、对小数据集的结果给予过度信任的现象,心理学家 Danny Kahneman 和 Amos Tversky 总结出了小数定律。
例:
左图为掷硬币试验的大样本,右图为 2017 年美国阿拉巴马州参议院选举的小样本:
抽样(sampling)
均值标准误(standard error of the mean, SEM):
由上式可以看出,增加样本容量可以提高统计质量;然而,样本容量的增加只能使统计质量呈平方根式的增长,过度追求大样本并不能带来相应的收益。
中心极限定理(The Central Limit Theorem):
当某个统计量受多种不同因素共同影响时,结果很可能是一个正态分布。
例:成年人的身高由很多因素(先天遗传、后天经历)决定,尽管其中各种因素的影响未必服从正态分布,但它们组合起来所得的结果却是服从正态分布的。
随机性(randomness)
- 值得注意的是,某件事情是不可预测的,并不意味着它不是确定性的。
例如,当我们掷一枚硬币时,其结果是由物理学定律决定的,如果我们知道决定其结果的所有物理条件的全部细节,我们就可以预测出抛掷结果。然而,实际上诸多因素会对结果造成影响,使之通常不可预测。
- 心理学家指出,人们对于随机性的感觉实际上是很差的。
一方面,我们有看到本不存在的模式的倾向。极端地,这会导致幻想性错觉的现象,即在随机的模式中感知到熟悉的物体。
另一方面,人们倾向于认为随机性表现为“自我纠正”。这导致我们在运气游戏中输掉很多轮后,总是会期待“该赢一回”,即赌徒谬误。
假设检验(hypothesis testing)
假设的等性(equality)、不等性(inequality):
原始假设()总是表现为等性假设,即
;而备选假设(
)意味着一个有实际影响的结论,因此其总是表现为不等性假设,即
。
重要地,原始假设检验的原则是,除非有明确的相反的证据,否则认为原始假设为真。
无向假设(non-directional)、有向假设(directional):
检验一个无向假设()更加保守,因此,除非有足够强大的先验理由,否则通常不建议做有向假设(
)。
P 值(p-value)的含义:
在假设检验中,P 值(p-value)指的是,在假设成立的条件下,出现所观测数据的概率 ,而不是反过来
,因此假设检验并不能支持和
有关的结论。
多重比较谬误(multiple comparisons fallacy)、familywise error:

控制 familywise error 的一种简单方式:Bonferroni 校正(Bonferroni correction,以意大利统计学家 Carlo Bonferroni 命名):将显著性水平(alpha level)除以比较次数。
贝叶斯统计(Bayesian statistics)
频率学派与贝叶斯学派的基本区别:
频率学派不相信假设成立的概率,即假设的可信程度,他们认为,假设非真即假。换句话说,对于频率学派,假设是固定的而数据是随机的,这就是为什么他们的推理集中于给定假设条件下出现所观测数据的概率(P 值);而贝叶斯学派,更乐于同时通过数据和假设来阐述概率。
小概率事件(rare events):
对小概率事件的检验几乎总是倾向于产生误报(false positive)的结果。
连续性(sequential):
贝叶斯分析的一个重要特点就是它具有连续性。也就是说,当我们获得一次分析的后验概率之后,就可以将其作为下一次分析的先验概率。
先验概率的选择:
经验主义先验(empirical priors)旨在基于科学文献或已存在的数据设置先验概率。然而,为了减弱先验概率对结果的影响,我们仍然坚持使用无信息先验(uninformative priors)或弱信息先验(weakly informative priors)。
辛普森悖论(Simpson's paradox)
现象:整体数据的特征,与各局部数据的特征均相反。
例:两个棒球运动员在 1995-1997 年的比赛数据:

原因:
有一个潜在变量(lurking variable)会影响统计结果,即例中每一年的击球总次数(Justice 在 1995 年击球总次数远多于 Jeter)。
在检查类别数据(categorical data)时,要时刻注意这样的变量。
再举一个极端点的例子:

延申阅读:
Simpson's paradox in psychological science: a practical guide
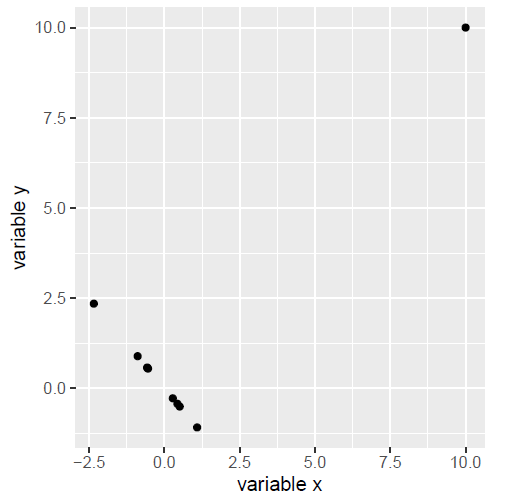
斯皮尔曼相关系数(Spearman correlation)
当存在离群值时,可通过该方式进行处理,即先将数据排序,再根据等级数据计算相关系数。
例:如下图所示,由于离群值的存在,其皮尔逊相关系数(Pearson correlation)为正(0.83);而斯皮尔曼相关系数为负(-0.45),没有受到严重影响。
做可重复的研究(reproducible research)
可能导致 p-hacking 的研究方式:
- 分析所有主题的数据,当 p < 0.05 时停止数据收集;
- 分析很多不同的变量,但只报道 p < 0.05 的那些;
- 收集很多不同的实验条件,但只报道 p < 0.05 的那些;
- 去除一些参与者,以获得 p < 0.05;
- 为获得 p < 0.05 而改变数据。
研究标准:
Simmons 等人在2011年的论文(见延伸阅读)中,列举了一系列使研究更具可重复性的做法,这些都应成为研究者们所持的标准:
- 作者必须在数据收集开始前就确定数据收集的终止规则,并在文章中说明该规则;
- 作者必须对每单个数据观测至少20次,否则须提供一个可信服的数据收集成本的理由;
- 作者必须列举在研究中收集的所有变量;
- 作者必须说明所有的实验条件,包括错误操作;
- 如果某些观测被除去,作者必须额外说明包含这些观测的统计结果;
- 如果分析中包含协变量,作者必须说明不含该协变量的分析的统计结果。
再谈 P 值(p-value):
要记住的是,P 值不能提供可重复性的量度。
如前所述,P 值用于表述,特定原始假设下,出现所观测数据的可能性;它并不能为研究结果正确的概率提供任何信息。
如要知道可重复的可能性,我们需要知道研究结果正确的概率,而这个我们通常都不知道。
工具选用:
为便于做可重复的分析,脚本化的分析工具(如 R 语言)优于点击式的软件,而免费的开源软件优于付费的商业软件。
结论:
研究的目的不是要去发现一个有意义的结果,而是用最可能真实的方式提出并解答有关自然的问题。
It is every scientist’s responsibility to improve their research practices in order to increase the reproducibility of their research. It is essential to remember that the goal of research is not to find a significant result; rather, it is to ask and answer questions about nature in the most truthful way possible. Most of our hypotheses will be wrong, and we should be comfortable with that, so that when we find one that’s right, we will be even more confident in its truth.
延伸阅读:
Simmons, Joseph P, Leif D Nelson, and Uri Simonsohn. 2011. “False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant.” Psychol Sci 22 (11): 1359–66. https://doi.org/10.1177/0956797611417632.
写在最后的建议:向统计学家寻求帮助
理解这本书(即参考资料)的内容并不会使你不再需要统计学家的帮助,但会帮助你与他们更有根据地进行交流,并更好地理解他们所提供的建议。
Whenever one is analyzing real data, it’s useful to check your analysis plan with a trained statistician, as there are many potential problems that could arise in real data. In fact, it’s best to speak to a statistician before you even start the project, as their advice regarding the design or implementation of the study could save you major headaches down the road. Most universities have statistical consulting offices that offer free assistance to members of the university community. Understanding the content of this book won’t prevent you from needing their help at some point, but it will help you have a more informed conversation with them and better understand the advice that they offer.
相关文献
Brad Efron & Trevor Hastie, Computer Age Statistical Inference: Algorithms, Evidence, and Data Science















 8601
8601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









