






文章链接MixUp https://arxiv.org/abs/1710.09412
https://arxiv.org/abs/1710.09412
Introduction:
- 现有的深度学习模型一般都有两个共性:1) 这些模型在训练过程中都是最小化其在训练集样本上的平均损失,也即是经验风险最小化(empirical risk minimization, ERM);2) 这些深度模型的参数量都与训练样本量成线性关系(一般是训练集样本数量的100-200倍)。
- 既往研究表明,只要模型大小(使用VC复杂度表示)不随着训练集样本数量的增加而增加,那么ERM就一定能够收敛。于是我们在使用ERM训练深度模型的时候就可能会有以下两个问题:1) 即使训练过程中使用了一些很强的正则化方法或者随机分配样本标签,ERM也能促使大型网络模型“记住”训练样本数据;2) 当使用ERM训练的模型对训练集样本以外的样本进行预测时,模型的预测结果可能会变化比较大(可能是波动大,也肯恶搞是效果差)。
- 邻域风险最小化(Vicinal Risk Minimization,VRM)就是除ERM以外的另一个选择。VRM使用数据增强(增强数据与训练样本相似但不同)的方法训练模型。在VRM中,需要使用人类的知识来定义或描述训练集的每个样本的邻域或邻居,然后从该邻域分布中抽取一些邻域样本用于模型训练。例如在图像分类任务中,通常将一张图片的邻域定义为该图片通过水平反转,旋转以及缩放生成的图片的集合。
Contribution:
- 根据上述描述过程,本研究提出了一种简单的数据增强方法:mixup。mixup过程可以简单描述为:
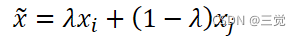
![]()
其中,𝑥𝑖和𝑥𝑗是原始输入向量,和
是one-hot编码的标签。 (𝑥𝑖,𝑦𝑖)和 (𝑥𝑗,𝑦𝑗)是从训练集中随机抽取的两个样本数据。
-
从ERM到mixup
- 在监督学习任务中,理想情况是我们可以找到一个感兴趣的函数𝑓,该函数可以很好的描述随机向量X和随机向量Y之间的关系,其中X和Y服从联合分布𝑃(X,Y)。然后,我们需要定义一个损失函数ℓ,该损失函数ℓ计算模型预测值𝑓(𝑥)与真实值y之间的差异,其中(𝑥,𝑦)~𝑃。接着,我们只需要在数据分布P的基础上,最小化损失函数的均值即可,也即是期望风险(expected risk):
![]()
- 但是通常情况下,样本的总体分布P一般是未知的,也就是说我们没有办法获取总体分布P对应的所有样本数据,我们只能获取一部分训练数据:
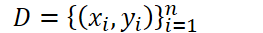
- 其中(𝑥𝑖,𝑦𝑖)~𝑃。使用训练数据D,我们就可以使用经验风险(empirical distribution)来近似分布P,也即是:
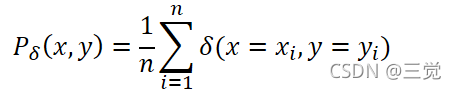
其中,𝛿(𝑥=𝑥𝑖,𝑦=𝑦𝑖)是以(𝑥𝑖,𝑦𝑖)为中心的Dirac mass。由上述经验分布𝑃𝛿,我们就可以使用经验风险来近似期望风险:
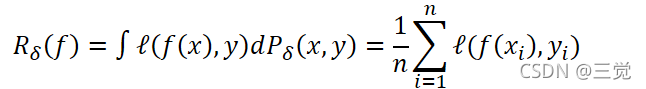
- 通过最小化上述公式就是我们所说的经验风险最小化(Empirical Risk Minimization, ERM)。当我们所建立的模型其参数量远远多于训练集样本数量时,使用ERM训练模型就会导致模型“记住”了训练样本,这时候模型对训练样本以外的数据预测能力就会变得非常差。而且, 𝑃𝛿只是真实分布P的一个可能的选项。
- 但是对于邻域风险最小化(Vicinal Risk Minimization, VRM)而言,真实分布P的近似表示为:
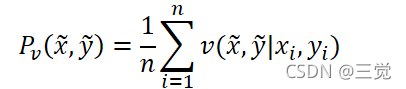
其中, 𝑣是一个计算在训练样本 (𝑥𝑖,𝑦𝑖)的邻域中选择出虚拟样本 𝑥,𝑦概率的邻域分布。
- 当我们使用VRM方法进行模型训练时,就会从训练集样本的邻域分布中生成数据集
并且最小化“经验邻域风险”: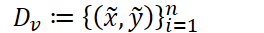
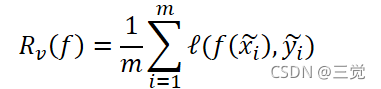
- 而这篇文章的贡献就是提出了一种通用的邻域分布mixup:
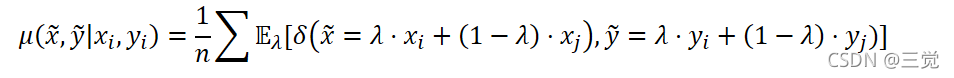
其中, 𝜆~𝐵𝑒𝑡𝑎(𝛼,𝛼),𝛼∈(0, ∞)。简单来说,使用mixup邻域分布生成的虚拟特征-目标向量就可以简单表示为:
![]()
![]()
其中, (𝑥𝑖,𝑦𝑖)和(𝑥𝑗,𝑦𝑗)是从训练集数据中随机选择的两个特征-目标向量, 𝜆∈[0,1]。超参数 𝛼用于控制两个样本特征的混合程度,当 𝛼=0的时候,VRM就等价于ERM。
本文作者通过研究得出以下几条结论:1) mixup过程比较适用于两个样本,当对3个或3个以上样本的信息进行mixup过程的时候,并不能有效提高模型的性能。2) 在minibatch样本中使用mixup过程同样可以取得不错的效果。3) 仅在有标签数据中使用mixup过程并不能带来有效的性能提升。
-
mixup都做了什么事情?
mixup邻域分布可以视作是一种数据增强的方法,该方法使得模型f 在训练样本之间呈现一种线性的渐变过程,这种线性的渐变过程就可以使得模型尽可能避免在对训练集以外的样本进行预测时,出现泛化能力不足的情况。

Fig.a 在pytorch中实现一个简单的mixup过程
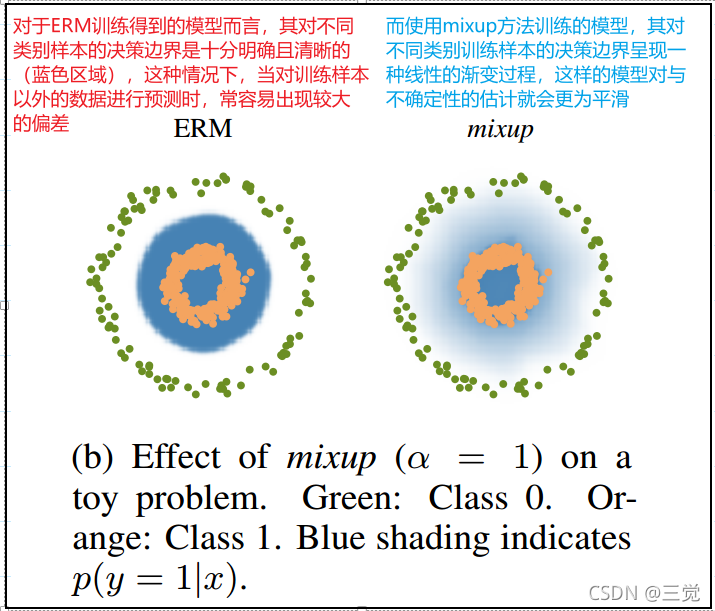
Fig.b mixup效果示意图

Fig.2 ERM和mixup在训练过程的表现
注意:
1) 通过研究发现,当 𝛼∈[0.1, 0.4]之间时,mixup的性能会优于ERM;但是如果继续增加 𝛼的取值,就会导致模型欠拟合。2) 当模型的能力(capacities)较强和/或模型训练轮次较多时,mixup的性能会更强。3) 随着 𝛼的不断增加,模型在真实数据上的训练误差会不断增加,但是模型的泛化能力也在不断提高。同时作者推测当增加模型的容量时,使得训练误差对较大 𝛼的敏感性降低,因此会使得mixup性能较强。


















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









