










前言
俗话说想训练好一个模型,3分靠模型,7分靠数据,然而真实情况往往是缺少数据,高额的标注成本、极为常见的长尾问题都限制了模型的效果。因此数据增强在AI领域基本上是必不可少,在CV中有图片的旋转、裁剪偏移等等,但是在nlp领域中想做好数据增强就有一点麻烦了,一些采样的方法例如smote在深度学习领域更是基本没啥效果。那么有没有什么好的方法,能在各种不同的领域都能做到数据增强并且稳定提升效果呢?
Mixup
Mixup是近几年提出来的一种新的数据增强的方法,它的核心思想是采用线性插值的方式从训练集生成新的数据点与标签的随机凸组合,该方法能提高模型的整体效果、泛化能力,其次能提高对抗攻击的鲁棒性。
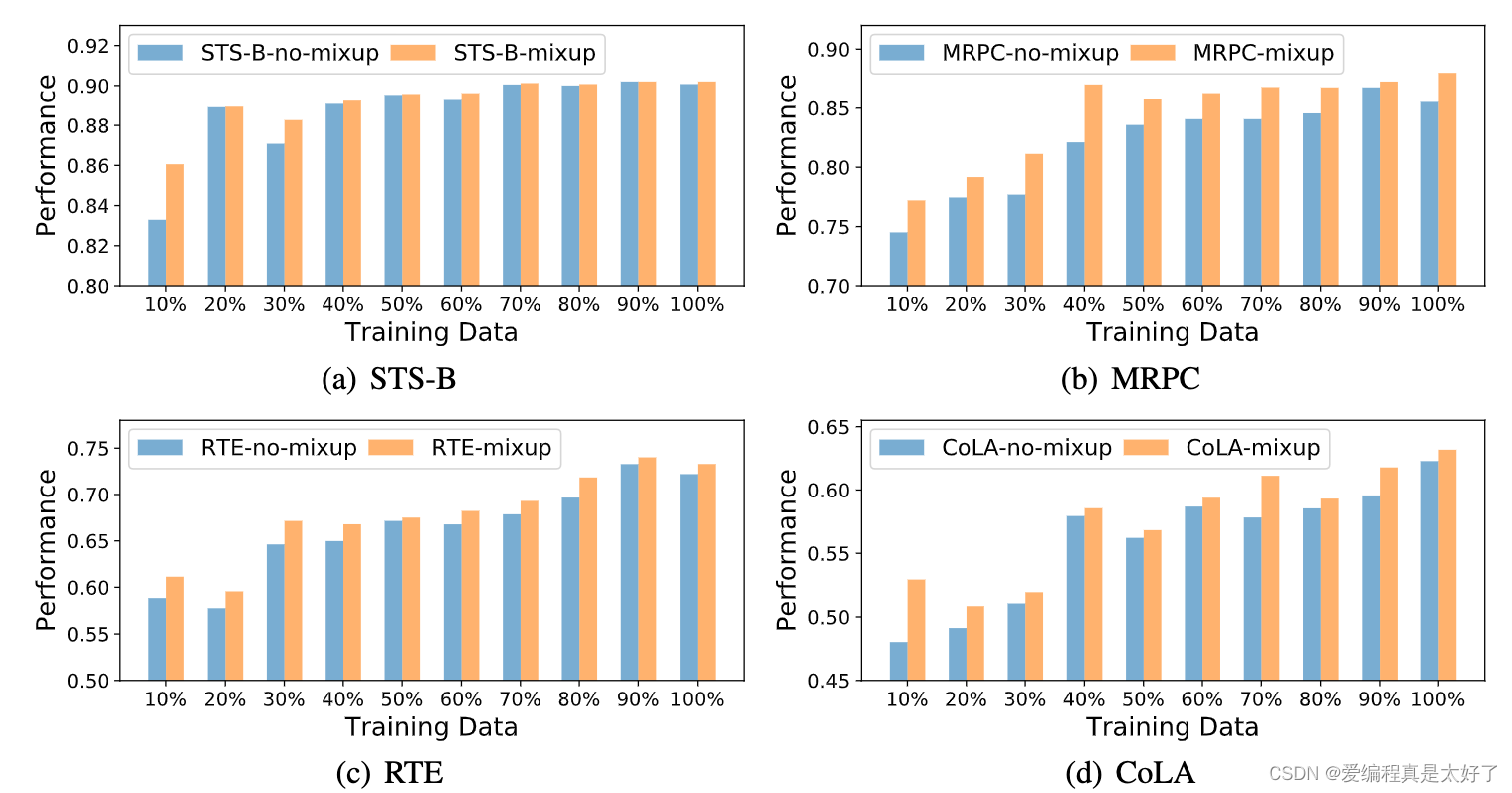
从下图可以看到数据量少的时候做了mixup效果有明显的提升
下图绿色和黄色分别是两类不同的样本,mixup让决策边界从一类线性过渡到另一类提供了更平滑的不确定性估计,从而提高泛化能力

Mixup的计算如下,其中 λ ∽ b e t a [ 0 , 1 ] ( α , α ) \lambda \backsim beta_{[0,1]}(\alpha,\alpha) λ∽beta[0,1](α,α)。简单来看Mixup就是对输入的一对 x x x做线性插值的融合,再对标签 y y y做了同样的融合处理。

看到这里相信大家已经有疑问了
- λ \lambda λ为什么要服从beta分布
- i 、 j i、j i、j随机选择,那么两句意思完全不同的文本也做Mixup为什么还能给模型带来效果上的提升?
Beta分布
我们先来看第一个问题beta分布,简单来说beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出所有概率出现的可能性大小,而这个可能性大小取决于 b e t a ( α , β ) beta(\alpha,\beta) beta(α,β)分布中的两个参数,在mixup中这两个参数相同,因此就有如下的beta概率分布图

可以看到,这其实是一个对称的分布
- α < 1 \alpha < 1 α<1 时得到的概率分布集中于1或者0
- α = 1 \alpha = 1 α=1 时就是均匀分布
- α > 1 \alpha > 1 α>1 时概率集中于 0.5
在大部分mixup的paper中, α \alpha α的值都偏向于小于1,这样就会让mix的两项一项的权重比较大,另一项权重比较小,甚至可以理解为一个是主动项,另一个是扰动项、噪音项。
正则化
接下来我们看第二个疑问,mixup为什么有效,我们先回顾下正则化项。
正则化在机器学习中是一种很重要的防止过拟合的方法,例如 LASSO 回归、岭回归,包括在xgboost中也存在正则化项,其次正则化在深度学习中也扮演着同样重要的角色,例如 drop out、batch norm 等。正则化通常包括两种形式,显式正则化与隐式正则化。
显式正则化包括:
-
各类惩罚项,例如L1/L2正则
-
对模型的中间层添加噪音,例如dropout、adversarial learning
-
归一化,例如batch normalization
隐式正则化包括:
- 参数共享,例如卷积的kernel
- 优化器,例如adam、adamW
- 数据增强
显式正则化方案通常是从控制模型的具体特性如鲁棒性的分析出发的,而隐式正则化的形式通常是从泛化的角度来理解的,数据增强过程的正则化效应在理论上的解释较少,不过数据量多一定程度是能提升模型的泛化能力,防止模型过拟合,因此也可以把数据增强理解为正则化。mixup作为数据增强的其中的一种方法,自然可以先简单理解为是给模型添加了隐式的正则化项,这也就解释了为什么mixup为什么能提升模型效果。但是这个正则化项是怎么体现出来的,就值得我们做更深入的分析了。
基于泰勒展开的Mixup正则化解释
注:本节内容比较偏理论,不影响你对mixup的使用,如果不感兴趣可以直接看下一节。
在On Mixup Regularization这篇paper中,采用了泰勒展开的方法分析了Mixup为什么有效,其证明了Mixup可以被重新解释为一个标准的经验风险最小化过程,我们来详细看下这个过程。
在监督学习中,我们的目标是找到一个从
X
X
X到
Y
Y
Y的映射函数
f
∈
F
f \in F
f∈F,这个数据通常会满足某种分布
P
(
X
,
Y
)
P(X,Y)
P(X,Y),定义loss用
l
\mathscr{l}
l表示,那么真实误差的期望风险就是
R
(
f
)
=
∫
ℓ
(
f
(
x
)
,
y
)
d
P
(
x
,
y
)
\LARGE R(f)=\int \ell(f(x), y) \mathrm{d} P(x, y)
R(f)=∫ℓ(f(x),y)dP(x,y)
但是大多数情况下,这个分布
P
P
P都是未知的,我们只能从现有的数据中采样出一部分来估计训练集整体误差,这样我们就能得到一个近似的经验分布
P
δ
(
x
,
y
)
=
1
n
∑
i
=
1
n
δ
(
x
=
x
i
,
y
=
y
i
)
\LARGE P_{\delta}(x, y)=\frac{1}{n} \sum_{i=1}^{n} \delta\left(x=x_{i}, y=y_{i}\right)
Pδ(x,y)=n1i=1∑nδ(x=xi,y=yi)
R δ ( f ) = ∫ ℓ ( f ( x ) , y ) d P δ ( x , y ) = 1 n ∑ i = 1 n ℓ ( f ( x i ) , y i ) \LARGE R_{\delta}(f)=\int \ell(f(x), y) \mathrm{d} P_{\delta}(x, y)=\frac{1}{n} \sum_{i=1}^{n} \ell\left(f\left(x_{i}\right), y_{i}\right) Rδ(f)=∫ℓ(f(x),y)dPδ(x,y)=n1i=1∑nℓ(f(xi),yi)
因此下面的公式通常被称为empirical risk minimization (ERM),经验风险最小化,其中
l
l
l表示的是各类损失函数,可以是平方损失,交叉熵损失等等,
f
f
f表示具体的某个模型
E
Empirical
(
f
)
=
1
n
∑
i
=
1
n
ℓ
(
y
i
,
f
(
x
i
)
)
(1)
\LARGE \mathcal{E}^{\text {Empirical }}(f)=\frac{1}{n} \sum_{i=1}^{n} \ell\left(y_{i}, f\left(x_{i}\right)\right) \tag{1} \\
EEmpirical (f)=n1i=1∑nℓ(yi,f(xi))(1)
在数据量足够时即可保证ERM训练的收敛性,但是如果数据量不够这就造成:
- 模型倾向于记忆训练样本,而不是泛化
- 难以抵御分布外样本,如肉眼感官没有区别的对抗样本
解决这一问题的一个途径就是使用邻域风险最小化原则Vicinal Risk Minimization(VRM),即通过先验知识构造训练样本在训练集分布上的邻域值,例如给输入加上一个Gaussian noise再进行训练,而mixup实际上就是基于VRM即采用线性插值的方法得到新的扩展数据。既然如此我们把mixup的变换后的
x
x
x与
y
y
y替换到的公式(1)中
E
Mixup
(
f
)
=
1
n
2
∑
i
=
1
n
∑
j
=
1
n
E
λ
ℓ
(
λ
y
i
+
(
1
−
λ
)
y
j
,
f
(
λ
x
i
+
(
1
−
λ
)
x
j
)
)
(2)
\large \mathcal{E}^{\text {Mixup }}(f)=\frac{1}{n^{2}} \sum_{i=1}^{n} \sum_{j=1}^{n} \mathbb{E}_{\lambda} \ell\left(\lambda y_{i}+(1-\lambda) y_{j}, f\left(\lambda x_{i}+(1-\lambda) x_{j}\right)\right) \tag{2}
EMixup (f)=n21i=1∑nj=1∑nEλℓ(λyi+(1−λ)yj,f(λxi+(1−λ)xj))(2)
为了简化公式,我们令
m
i
j
(
λ
)
=
ℓ
(
λ
y
i
+
(
1
−
λ
)
y
j
,
f
(
λ
x
i
+
(
1
−
λ
)
x
j
)
)
\LARGE m_{i j}(\lambda)=\ell\left(\lambda y_{i}+(1-\lambda) y_{j}, f\left(\lambda x_{i}+(1-\lambda) x_{j}\right)\right)
mij(λ)=ℓ(λyi+(1−λ)yj,f(λxi+(1−λ)xj))
带入公式(2)中有
E
Mixup
(
f
)
=
1
n
2
∑
i
=
1
n
∑
j
=
1
n
E
λ
m
i
j
(
λ
)
,
λ
∼
B
e
t
a
(
α
,
α
)
\LARGE \mathcal{E}^{\text {Mixup }}(f)=\frac{1}{n^{2}} \sum_{i=1}^{n} \sum_{j=1}^{n} \mathbb{E}_{\lambda} m_{ij}(\lambda),\lambda \sim Beta(\alpha,\alpha)
EMixup (f)=n21i=1∑nj=1∑nEλmij(λ),λ∼Beta(α,α)
把
λ
\lambda
λ分成两个部分的加和,一部分取值在[0,0.5]另一部分的取值在[0.5,1],如下
λ
=
π
λ
0
+
(
1
−
π
)
λ
1
,
λ
0
∼
B
e
t
a
[
0
,
1
2
]
(
α
,
α
)
,
λ
1
∼
B
e
t
a
[
1
2
,
1
]
(
α
,
α
)
,
π
∼
B
e
r
(
1
2
)
\large \lambda = \pi \lambda_0 + (1-\pi) \lambda_1, \lambda_0 \sim Beta_{[0,\frac{1}{2}]}(\alpha,\alpha), \lambda_1 \sim Beta_{[\frac{1}{2}, 1]}(\alpha,\alpha), \pi \sim Ber(\frac{1}{2})
λ=πλ0+(1−π)λ1,λ0∼Beta[0,21](α,α),λ1∼Beta[21,1](α,α),π∼Ber(21)
因为
π
\pi
π服从概率为0.5的伯努利分布,因此最终的结果就是概率一样的两个部分中的其中一个部分。把上式带入
m
i
j
m_{ij}
mij中,因为
π
∼
B
e
r
(
1
2
)
\pi \sim Ber(\frac{1}{2})
π∼Ber(21)期望是
1
2
\frac{1}{2}
21,所以可以把
1
2
\frac{1}{2}
21提取到外面,因为
m
i
j
(
λ
)
=
m
j
i
(
1
−
λ
)
m_{ij}(\lambda)=m_{ji}(1-\lambda)
mij(λ)=mji(1−λ) 注意看下标,所以
m
i
j
(
λ
0
)
=
m
j
i
(
1
−
λ
0
)
m_{ij}(\lambda_0)=m_{ji}(1-\lambda_0)
mij(λ0)=mji(1−λ0)
E
λ
m
i
j
(
λ
)
=
E
λ
0
,
λ
1
,
π
m
i
j
(
π
λ
0
+
(
1
−
π
)
λ
1
)
=
1
2
[
E
λ
0
m
i
j
(
λ
0
)
+
E
λ
1
m
i
j
(
λ
1
)
]
=
1
2
[
E
λ
0
m
j
i
(
1
−
λ
0
)
+
E
λ
1
m
i
j
(
λ
1
)
]
\LARGE \begin{aligned} \mathbb{E}_{\lambda} m_{i j}(\lambda) &=\mathbb{E}_{\lambda_{0}, \lambda_{1}, \pi} m_{i j}\left(\pi \lambda_{0}+(1-\pi) \lambda_{1}\right) \\ &=\frac{1}{2}\left[\mathbb{E}_{\lambda_{0}} m_{i j}\left(\lambda_{0}\right)+\mathbb{E}_{\lambda_{1}} m_{i j}\left(\lambda_{1}\right)\right] \\ &=\frac{1}{2}\left[\mathbb{E}_{\lambda_{0}} m_{j i}\left(1-\lambda_{0}\right)+\mathbb{E}_{\lambda_{1}} m_{i j}\left(\lambda_{1}\right)\right] \end{aligned}
Eλmij(λ)=Eλ0,λ1,πmij(πλ0+(1−π)λ1)=21[Eλ0mij(λ0)+Eλ1mij(λ1)]=21[Eλ0mji(1−λ0)+Eλ1mij(λ1)]
因为
λ
0
\lambda_0
λ0与
λ
1
\lambda_1
λ1都是服从同一个beta分布的只是值的范围不同,所以有
1
−
λ
0
=
λ
1
1-\lambda_0=\lambda_1
1−λ0=λ1 带入到(2)中则有
E
Mixup
(
f
)
=
1
2
n
2
∑
i
=
1
n
∑
j
=
1
n
[
E
λ
1
m
j
i
(
λ
1
)
+
E
λ
1
m
i
j
(
λ
1
)
]
=
1
n
2
∑
i
=
1
n
∑
j
=
1
n
E
λ
1
m
i
j
(
λ
1
)
=
1
n
∑
i
=
1
n
[
1
n
∑
j
=
1
n
E
λ
1
m
i
j
(
λ
1
)
]
=
1
n
∑
i
=
1
n
ℓ
i
\LARGE \begin{aligned} \mathcal{E}^{\text {Mixup }}(f) &=\frac{1}{2 n^{2}} \sum_{i=1}^{n} \sum_{j=1}^{n}\left[\mathbb{E}_{\lambda_{1}} m_{j i}\left(\lambda_{1}\right)+\mathbb{E}_{\lambda_{1}} m_{i j}\left(\lambda_{1}\right)\right] \\ &=\frac{1}{n^{2}} \sum_{i=1}^{n} \sum_{j=1}^{n} \mathbb{E}_{\lambda_{1}} m_{i j}\left(\lambda_{1}\right) \\ &=\frac{1}{n} \sum_{i=1}^{n}\left[\frac{1}{n} \sum_{j=1}^{n} \mathbb{E}_{\lambda_{1}} m_{i j}\left(\lambda_{1}\right)\right] \\ &=\frac{1}{n} \sum_{i=1}^{n} \ell_{i} \end{aligned}
EMixup (f)=2n21i=1∑nj=1∑n[Eλ1mji(λ1)+Eλ1mij(λ1)]=n21i=1∑nj=1∑nEλ1mij(λ1)=n1i=1∑n⎣⎢⎢⎢⎡n1j=1∑nEλ1mij(λ1)⎦⎥⎥⎥⎤=n1i=1∑nℓi
ℓ i = E θ , j ℓ ( θ y i + ( 1 − θ ) y j , f ( θ x i + ( 1 − θ ) x j ) ) , θ ∼ Beta [ 1 2 , 1 ] ( α , α ) , j ∼ Unif ( [ n ] ) \normalsize \ell_{i}=\mathbb{E}_{\theta, j} \ell\left(\theta y_{i}+(1-\theta) y_{j}, f\left(\theta x_{i}+(1-\theta) x_{j}\right)\right), \quad \theta \sim \operatorname{Beta}_{\left[\frac{1}{2}, 1\right]}(\alpha, \alpha), \quad j \sim \operatorname{Unif}([n]) ℓi=Eθ,jℓ(θyi+(1−θ)yj,f(θxi+(1−θ)xj)),θ∼Beta[21,1](α,α),j∼Unif([n])
接下来我们分析下
ℓ
i
\ell_i
ℓi,我们把
ℓ
i
\ell_i
ℓi写做如下形式
ℓ
i
=
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
\LARGE \ell_i= \ell(\tilde y_i,f(\tilde x_i))
ℓi=ℓ(y~i,f(x~i))
那么有
{
x
~
i
=
E
θ
,
j
[
θ
x
i
+
(
1
−
θ
)
x
j
]
y
~
i
=
E
θ
,
j
[
θ
y
i
+
(
1
−
θ
)
y
j
]
\LARGE \left\{\begin{array}{l} \tilde{x}_{i}=\mathbb{E}_{\theta, j}\left[\theta x_{i}+(1-\theta) x_{j}\right] \\ \widetilde{y}_{i}=\mathbb{E}_{\theta, j}\left[\theta y_{i}+(1-\theta) y_{j}\right] \end{array}\right.
⎩⎪⎨⎪⎧x~i=Eθ,j[θxi+(1−θ)xj]y
i=Eθ,j[θyi+(1−θ)yj]
把期望化简下因此有
{
x
~
i
=
x
ˉ
+
θ
ˉ
(
x
i
−
x
ˉ
)
y
~
i
=
y
ˉ
+
θ
ˉ
(
y
i
−
y
ˉ
)
\LARGE \left\{\begin{array}{l} \widetilde{x}_{i}=\bar{x}+\bar{\theta}\left(x_{i}-\bar{x}\right) \\ \tilde{y}_{i}=\bar{y}+\bar{\theta}\left(y_{i}-\bar{y}\right) \end{array}\right.
⎩⎪⎨⎪⎧x
i=xˉ+θˉ(xi−xˉ)y~i=yˉ+θˉ(yi−yˉ)
接下来我们再定义两个差值项
δ
i
、
ϵ
i
\delta_i、\epsilon_i
δi、ϵi,这两个插值的期望是0
{
δ
~
i
=
θ
x
i
+
(
1
−
θ
)
x
j
−
E
θ
,
j
[
θ
x
i
+
(
1
−
θ
)
x
j
]
ε
~
i
=
θ
y
i
+
(
1
−
θ
)
y
j
−
E
θ
,
j
[
θ
y
i
+
(
1
−
θ
)
y
j
]
\LARGE \left\{\begin{array}{l} \widetilde{\delta}_{i}=\theta x_{i}+(1-\theta) x_{j}-\mathbb{E}_{\theta, j}\left[\theta x_{i}+(1-\theta) x_{j}\right] \\ \widetilde{\varepsilon}_{i}=\theta y_{i}+(1-\theta) y_{j}-\mathbb{E}_{\theta, j}\left[\theta y_{i}+(1-\theta) y_{j}\right] \end{array}\right.
⎩⎪⎨⎪⎧δ
i=θxi+(1−θ)xj−Eθ,j[θxi+(1−θ)xj]ε
i=θyi+(1−θ)yj−Eθ,j[θyi+(1−θ)yj]
因为
E
θ
,
j
[
θ
y
i
+
(
1
−
θ
)
y
j
]
=
y
‾
+
θ
ˉ
(
y
i
−
y
‾
)
E
θ
,
j
[
θ
X
i
+
(
1
−
θ
)
X
j
]
=
X
‾
+
θ
ˉ
(
X
i
−
X
‾
)
\LARGE \begin{aligned} &\mathbb{E}_{\theta, j}\left[\theta \mathbf{y}_{\mathbf{i}}+(1-\theta) \mathbf{y}_{\mathbf{j}}\right]=\overline{\mathbf{y}}+\bar{\theta}\left(\mathbf{y}_{i}-\overline{\mathbf{y}}\right) \\ &\mathbb{E}_{\theta, j}\left[\theta \mathbf{X}_{\mathbf{i}}+(1-\theta) \mathbf{X}_{\mathbf{j}}\right]=\overline{\mathbf{X}}+\bar{\theta}\left(\mathbf{X}_{i}-\overline{\mathbf{X}}\right) \end{aligned}
Eθ,j[θyi+(1−θ)yj]=y+θˉ(yi−y)Eθ,j[θXi+(1−θ)Xj]=X+θˉ(Xi−X)
所以有
{
δ
i
=
(
θ
−
θ
ˉ
)
x
i
+
(
1
−
θ
)
x
j
−
(
1
−
θ
ˉ
)
x
ˉ
ε
i
=
(
θ
−
θ
ˉ
)
y
i
+
(
1
−
θ
)
y
j
−
(
1
−
θ
ˉ
)
y
ˉ
\LARGE \left\{\begin{array}{l} \delta_{i}=(\theta-\bar{\theta}) x_{i}+(1-\theta) x_{j}-(1-\bar{\theta}) \bar{x} \\ \varepsilon_{i}=(\theta-\bar{\theta}) y_{i}+(1-\theta) y_{j}-(1-\bar{\theta}) \bar{y} \end{array}\right.
⎩⎪⎨⎪⎧δi=(θ−θˉ)xi+(1−θ)xj−(1−θˉ)xˉεi=(θ−θˉ)yi+(1−θ)yj−(1−θˉ)yˉ
最终我们可以把(2)式以如下形式表示
E
Mixup
(
f
)
=
1
n
∑
i
=
1
n
E
θ
,
j
ℓ
(
y
~
i
+
ε
i
,
f
(
x
~
i
+
δ
i
)
)
(3)
\LARGE \mathcal{E}^{\operatorname{Mixup}}(f)=\frac{1}{n} \sum_{i=1}^{n} \mathbb{E}_{\theta, j} \ell\left(\widetilde{y}_{i}+\varepsilon_{i}, f\left(\widetilde{x}_{i}+\delta_{i}\right)\right) \tag{3}
EMixup(f)=n1i=1∑nEθ,jℓ(y
i+εi,f(x
i+δi))(3)
分析下(3)式,其做了两个事
1、把数据从 ( x i , y i ) (x_i,y_i) (xi,yi)转变到了 ( x ~ i , y ~ i ) (\tilde x_i,\tilde y_i) (x~i,y~i),而这个转变的过程实际上是把输入和输出朝着它们的均值做了个收缩,并且这个收缩的过程有一个收缩比即 θ ∈ [ 0.5 , 1 ] \theta \in [0.5,1] θ∈[0.5,1],如果我们让beta分布的参数小于1,那么这里的压缩比就会集中在1附近, x ~ i \tilde x_i x~i就会接近原来的值,反之就会接近均值。对于 y y y来说,实际上是做了一个类似于label smoothing的处理,所以在运用了mixup之后预测出来的结果不会太大,这个会在后续的实验中看到。
2、给 ( x ~ i , y ~ i ) (\tilde x_i,\tilde y_i) (x~i,y~i)添加了一个均值为0的随机扰动,看到这里大家是不是感觉有正则那味了,接下来我们就详细分析下这个扰动
对(3)式做二阶泰勒展开有
ℓ
Q
(
i
)
(
y
~
i
+
ε
,
f
(
x
~
i
+
δ
)
)
=
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
+
∇
y
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
ε
+
∇
u
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
∇
x
f
(
x
~
i
)
δ
+
1
2
⟨
δ
δ
⊤
,
∇
f
(
x
~
i
)
⊤
∇
u
u
2
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
∇
f
(
x
~
i
)
+
∇
u
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
∇
2
f
(
x
~
i
)
⟩
+
1
2
⟨
ε
ε
⊤
,
∇
y
y
2
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
⟩
+
⟨
ε
δ
⊤
,
∇
y
u
2
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
∇
f
(
x
~
i
)
⟩
,
(4)
\large \begin{aligned} \ell_{Q}^{(i)}\left(\widetilde{y}_{i}+\varepsilon, f\left(\widetilde{x}_{i}+\delta\right)\right) &=\ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right)+\nabla_{y} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right) \varepsilon+\nabla_{u} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right) \nabla_{x} f\left(\widetilde{x}_{i}\right) \delta \\ &+\frac{1}{2}\left\langle\delta \delta^{\top}, \nabla f\left(\widetilde{x}_{i}\right)^{\top} \nabla_{u u}^{2} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right) \nabla f\left(\widetilde{x}_{i}\right)+\nabla_{u} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right) \nabla^{2} f\left(\widetilde{x}_{i}\right)\right\rangle \\ &+\frac{1}{2}\left\langle\varepsilon \varepsilon^{\top}, \nabla_{y y}^{2} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right)\right\rangle+\left\langle\varepsilon \delta^{\top}, \nabla_{y u}^{2} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right) \nabla f\left(\widetilde{x}_{i}\right)\right\rangle, \end{aligned} \tag{4}
ℓQ(i)(y
i+ε,f(x
i+δ))=ℓ(y
i,f(x
i))+∇yℓ(y
i,f(x
i))ε+∇uℓ(y
i,f(x
i))∇xf(x
i)δ+21⟨δδ⊤,∇f(x
i)⊤∇uu2ℓ(y
i,f(x
i))∇f(x
i)+∇uℓ(y
i,f(x
i))∇2f(x
i)⟩+21⟨εε⊤,∇yy2ℓ(y
i,f(x
i))⟩+⟨εδ⊤,∇yu2ℓ(y
i,f(x
i))∇f(x
i)⟩,(4)
这里把展开的结果用
R
i
R_i
Ri来表示化简后有,具体推导请参考paper附录A.3部分,这里不做详细说明

其中
Σ
x
~
x
~
(
i
)
=
σ
2
(
x
~
i
−
x
ˉ
)
(
x
~
i
−
x
ˉ
)
⊤
+
γ
2
Σ
x
~
x
~
θ
ˉ
2
,
Σ
y
~
y
~
(
i
)
=
σ
2
(
y
~
i
−
y
ˉ
)
(
y
~
i
−
y
ˉ
)
⊤
+
γ
2
Σ
y
~
y
~
θ
ˉ
2
Σ
x
~
y
~
(
i
)
=
σ
2
(
x
~
i
−
x
ˉ
)
(
y
~
i
−
y
ˉ
)
⊤
+
γ
2
Σ
x
~
y
~
θ
ˉ
2
.
\large \begin{aligned} \Sigma_{\widetilde{x} \tilde{x}}^{(i)} &=\frac{\sigma^{2}\left(\widetilde{x}_{i}-\bar{x}\right)\left(\tilde{x}_{i}-\bar{x}\right)^{\top}+\gamma^{2} \Sigma_{\widetilde{x} \tilde{x}}}{\bar{\theta}^{2}}, \\ \Sigma_{\widetilde{y} \tilde{y}}^{(i)} &=\frac{\sigma^{2}\left(\widetilde{y}_{i}-\bar{y}\right)\left(\widetilde{y}_{i}-\bar{y}\right)^{\top}+\gamma^{2} \Sigma_{\widetilde{y} \tilde{y}}}{\bar{\theta}^{2}} \\ \Sigma_{\widetilde{x} \tilde{y}}^{(i)} &=\frac{\sigma^{2}\left(\widetilde{x}_{i}-\bar{x}\right)\left(\widetilde{y}_{i}-\bar{y}\right)^{\top}+\gamma^{2} \Sigma_{\widetilde{x} \tilde{y}}}{\bar{\theta}^{2}} . \end{aligned}
Σx
x~(i)Σy
y~(i)Σx
y~(i)=θˉ2σ2(x
i−xˉ)(x~i−xˉ)⊤+γ2Σx
x~,=θˉ2σ2(y
i−yˉ)(y
i−yˉ)⊤+γ2Σy
y~=θˉ2σ2(x
i−xˉ)(y
i−yˉ)⊤+γ2Σx
y~.
最后,我们可以把结果表示成ERM的结果加上了四个子项也即我们的扰动项,每一个子项又都可以看成一个惩罚项,其中
R
1
R1
R1与
R
2
R2
R2表示的是对输入值x的正则化,并且
R
1
R1
R1就是Jacobian正则化,
R
3
R3
R3表示的是对输出值y的正则化,而
R
4
R4
R4是对x与y的正则化。到此我们就解释清楚了为什么说mixup也是在做正则化,同时这个结果也就解释了为什么mixup需要同时mix输入值与输出值。
E
Q
Mixup
(
f
)
=
1
n
∑
i
=
1
n
ℓ
(
y
~
i
,
f
(
x
~
i
)
)
+
R
1
(
f
)
+
R
2
(
f
)
+
R
3
(
f
)
+
R
4
(
f
)
,
\large \begin{aligned} &\mathcal{E}_{Q}^{\text {Mixup }}(f)=\frac{1}{n} \sum_{i=1}^{n} \ell\left(\widetilde{y}_{i}, f\left(\widetilde{x}_{i}\right)\right)+R_{1}(f)+R_{2}(f)+R_{3}(f)+R_{4}(f), \\ \end{aligned}
EQMixup (f)=n1i=1∑nℓ(y
i,f(x
i))+R1(f)+R2(f)+R3(f)+R4(f),
Transformer中的Mixup
看了这么多理论分析,这个部分我们就来看下应用,笔者主要是做nlp的因此本部分的内容以nlp为主。目前nlp的模型基本都是embedding+encoder+classifier,包括基于transformer的预训练模型也是如此,因此在transformer中进行mixup的时候,我们实际上可以mixup三个部分的值,分别是embedding层的值,encoder的中间层的值,给到classifer前的值,如下图。

我们测试了两种规模大小的模型,在我们自己的数据集mixup不同位置都有一定的效果
3层的roberta对比效果如下
| roberta 3层 | F1 | Kappa |
|---|---|---|
| Baseline | 0.9354 | 0.8988 |
| Embedding | 0.9169 | 0.8877 |
| Inner0 | 0.9297 | 0.8942 |
| Inner1 | 0.9320 | 0.8901 |
| Inner2 | 0.9398 | 0.9040 |
| Pooler | 0.9441 | 0.9107 |
base版本的roberta对比效果如下
| roberta 12层 | F1 | Kappa |
|---|---|---|
| Baseline | 0.9275 | 0.8991 |
| Embedding | 0.9316 | 0.9076 |
| Inner0 | 0.9288 | 0.9047 |
| Inner1 | 0.9333 | 0.9074 |
| Inner2 | 0.9252 | 0.8987 |
| Inner3 | 0.9310 | 0.9045 |
| Inner4 | 0.9326 | 0.8985 |
| Inner5 | 0.9386 | 0.9065 |
| Inner6 | 0.9339 | 0.8968 |
| Inner7 | 0.9337 | 0.9027 |
| Inner8 | 0.9283 | 0.8945 |
| Inner9 | 0.9344 | 0.9093 |
| Inner10 | 0.9345 | 0.9051 |
| Inner11 | 0.9416 | 0.9154 |
| Pooler | 0.9343 | 0.9059 |

不同的层效果有些波动,但整体来说还是满足一个结论:mixup的特征越接近目标效果越好。说下我的理解,越是接近目标的层其权重对结果影响越大,如果能对这些层的权重做一些正则的处理,那收益肯定会大于前面的层。
除了选择具体的某一层mixup,我们还测试了随机选择inner层,即每一个epoech都随机选择一层进行mixup,但是效果并不理想。
训练过程
这一部分聊一下mixup的训练过程,mixup目前通用的方案都是对一个batch内的数据进行shuffle,然后组合成对,如下伪代码,注意y需要是one-hot的形式
index = torch.randperm(batch_size)
y_mix = one_hot(y) * lam + one_hot(y[index]) * (1 - lam)
x_mix = x * lam + x[index] * (1 - lam)
那么这里就又有一些疑问了,shuffle后就是随机组合了,为啥要随机组合,取同样标签的数据进行mix可以吗?
考虑一下,如果是同样的标签,输入值做了mix,label mix后的结果还是one-hot的形式等于没有mix,不满足我们的公式公式(3),因此同样标签的mixup等于没有效果。而随机选择则刚好满足了对label 的smoothing处理。
除了如何mix,我们再看下如何更新权重,这里我们也对比了三种不同的方法
| methed | F1 | Kappa |
|---|---|---|
| 正常训练一个 epoch再mixup训练一个epoch | 0.9300 | 0.8941 |
| 正常训练不更新梯度再mixup训练后做梯度累加 | 0.9439 | 0.9177 |
| 正常训练N个epoch再mixup训练M个epoch | 0.9436 | 0.9127 |
最终我们保留了第二种方法,第三种方法需要去选择合适的N与M也就是额外多了两个超参数,炼丹成本高。
在考虑如何更新权重时我们遇到了一个很有意思的事,在做梯度累加时,第一次我们并没有把loss除以2,理论上来说就不是在做梯度累加,这会导致梯度可能会很大,但是最终的结果却还不错,这是为什么呢?

看下上面这个图,mixup相比于ERM梯度会小很多,也就是说模型每次更新权重会更加“谨慎”,从而缓解了我们上面的“错误的梯度累加”带来的问题。
在我们上线第一个版本你的mixup模型时,发现一个问题,之前的模型logits较高的softmax之后的值都会集中在0.99+,而mixup会让这个结果降低到0.98+,也就是说mixup实际上会让模型的置信度降低,关键原因其实就是label smoothing,我们的训练结果包含很多非one-hot形式的label,因此如果你在项目中有设置阈值那就要重新分析下了。

代码与实现
最后简单介绍下代码实现,模型基于transformers,目前mixup开源的代码基本都是在模型结构的内部就行集成,耦合较高,这里给大家介绍一种新的方法,使用pytorch的hook,从而在前向传播的时候拿到中间值,这时对中间值进行插值即可。
input_ids = data['input_ids'].to(self.device)
attention_mask = data['attention_mask'].to(self.device)
label = data['labels'].to(self.device).long()
batch_size = len(input_ids)
# 打乱顺序用于计算mix embedding
index = torch.randperm(batch_size).to(self.device)
lam = np.random.beta(1, 1)
label_mix = one_hot(label, self.num_labels) * lam + one_hot(label[index], self.num_labels) * (1 - lam)
hook = None
def single_forward_hook(module, inputs, outputs):
mix_input = outputs * lam + outputs[index] * (1 - lam)
return mix_input
def multi_forward_hook(module, inputs, outputs):
mix_input = outputs[0] * lam + outputs[0][index] * (1 - lam)
return tuple([mix_input])
if self.layer == 'embedding':
hook = self.model.bert.embeddings.register_forward_hook(single_forward_hook)
elif self.layer == 'pooler':
hook = self.model.bert.pooler.register_forward_hook(single_forward_hook)
elif self.layer == 'inner':
# 随机选一层
layer_num = random.randint(1, self.model.config.num_hidden_layers) - 1
hook = self.model.bert.encoder.layer[layer_num].register_forward_hook(multi_forward_hook)
outputs = self.model(input_ids=input_ids,
attention_mask=attention_mask,
labels=label.to(self.device))
logits = outputs.logits
hook.remove()
# 计算loss
loss = self.cross_entropy(logits, label_mix)
总结
本文对mixup做了一个“非”全面的介绍与原理分析,整体来说mixup是一种较为有效且实现简单的数据增强方案,无论工作还是比赛,都能让你的模型稳定提分。目前mixup也还有很多新的工作,例如结合无标签数据,应用在半监督、无监督学习中,相信未来mixup还能为我们带来更多精彩的操作。
本文所有内容都是本人自己的理解,如有疑问或理解上的偏差欢迎留言交流。
References
mixup: Beyond Empirical Risk Minimization
How Does Mixup Help With Robustness and Generalization
Mixup-Transformer: Dynamic Data Augmentation for NLP Tasks
Augmenting Data with Mixup for Sentence Classification: An Empirical Study
SeqMix: Augmenting Active Sequence Labeling via Sequence Mixup
Mixup Inference: Better Exploiting Mixup to Defend Adversarial Attacks
MixUp as Locally Linear Out-Of-Manifold Regularization

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









