







 本文深入解析了全球注意力(global attention)和局部注意力(local attention)机制在序列到序列模型中的应用。介绍了如何通过不同方式生成语境向量,以提高模型对输入序列的理解能力。包括基于内容的分数计算方法,如dot、general和concat,以及两种局部注意力的变形:单调对齐(local-m)和预测对齐(local-p)。
本文深入解析了全球注意力(global attention)和局部注意力(local attention)机制在序列到序列模型中的应用。介绍了如何通过不同方式生成语境向量,以提高模型对输入序列的理解能力。包括基于内容的分数计算方法,如dot、general和concat,以及两种局部注意力的变形:单调对齐(local-m)和预测对齐(local-p)。
一、概要
时间步t
1 首先使用最顶层堆叠LSTM的隐含层ht作为输入,以获得语境向量ct
2 进而预测出目标单词yt
global和local的区别仅在于语境向量ct的获取方式
3 拼接隐含层ht和语境向量ct,以获得注意力隐含层状态
![]()
4 接着注意力向量ht通过softmax层去生成预测分布
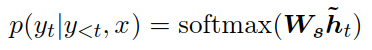
二、global attention 关注全局
思想:在生成语境向量ct时,考虑编码器里所有的隐含层状态
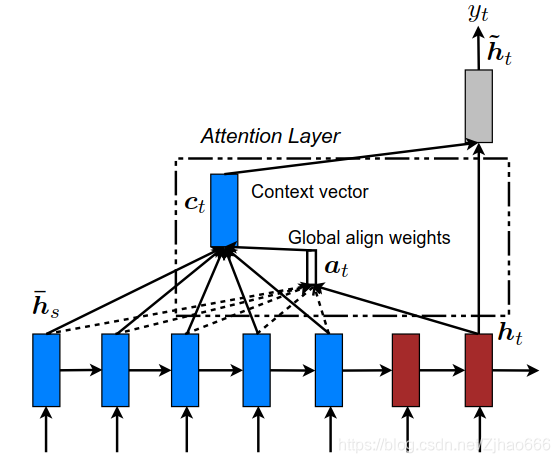
通过比较当前目标隐含层状态ht和每一个源隐含层状态hs,生成变长对齐向量at
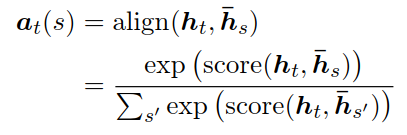
score是基于内容的函数,计算方式有dot、general、concat三种。
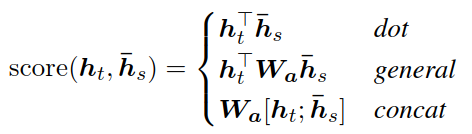
在论文的早期尝试中,作者曾使用基于定位location-based的方式,其对齐score函数是仅通过目标隐含层ht计算出来
![]()
给出了对齐向量作为权重,语境向量ct就被计算为所有的源隐含层状态hs的加权平均值
三、local attention 关注局部
global attention的局限:需要在关注源端的每一个目标单词,计算复杂度高且可能导致翻译长句子的时候出现问题。
local attention的思想:只需要关注源位置附近的单词子集。
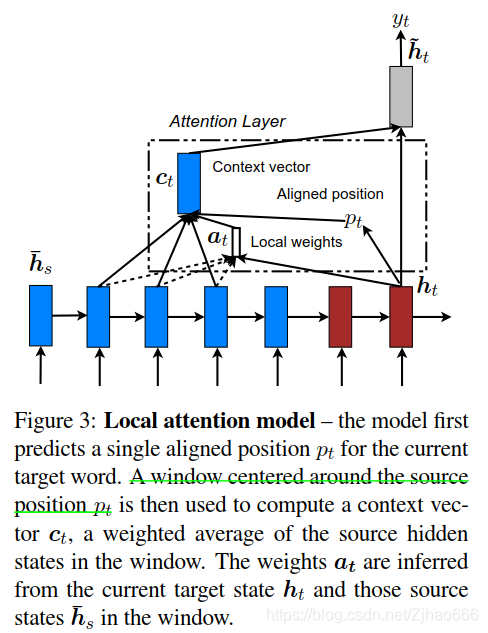
关注一个窗口,且是可微的
- 时间步t
- 先生成一个对齐位置pt
- 语境向量ct即为窗口pt-D到pt+D中源隐含层hs的加权平均。
和global不一样的,local的对齐向量是固定维度的。
两种变形
1 monotonic alignment(local-m)
pt=t,即假设源和目标序列是粗略地单调对齐
2 predictive alignment (local-p)
![]()
其中,
wp和vp是待学习的模型参数
S是源句子长度
为选择pt附近的对齐点,放置一个以pt为中心的高斯分布
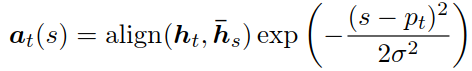
根据经验设定![]()
四、输入feeding方法
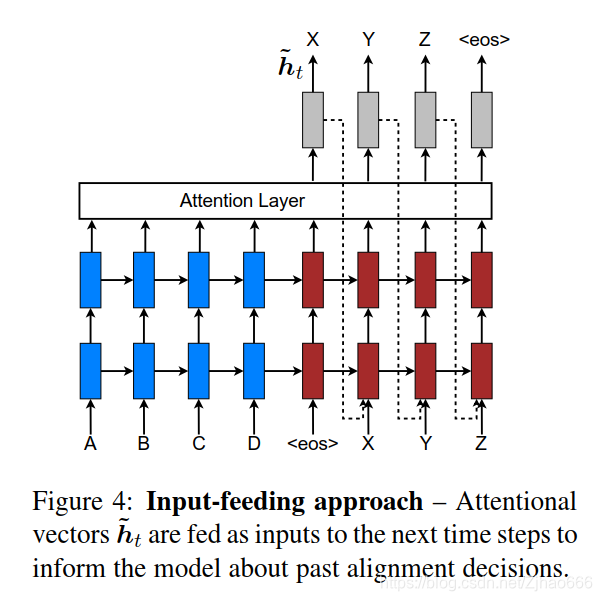
global和local的问题:注意力的决定是独立的。
解决:注意力向量ht被拼接进LSTM的下一步输入中。
好处:
- 完整考虑之前的对齐选项
- 网络在广度和深度都是深的

















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









