







基于PyQt5实时曲线绘制源代码和串口调试助手源代码带文件保存加载十六进制显示
Python两个工程的源代码
1.功能介绍:
包含两个程序:1.使用PyQt5编写实现的串口调试助手及源代码,2.pyqtgraph波形曲线显示源代码。
串口助手除了收发文本框外,还带有波特率数据位停止位校验位等参数设定,并具备十六进制收发,定时发送,保存到文件等功能。
波形绘制程序,除了曲线外,还带有开始停止测量,数据记录和数据加载等功能。
源代码均有详细的注释,并提供服务。
2.环境说明:
开发环境是PyQt5,使用Python自带的串口库serial,波形曲线采用pyqtgraph库。
源代码中包含注释,设计说明文档等。
请将源码放到纯英文路径下再编译。
3.使用介绍:
可直接运行在可执行程序里的exe文件,操作并了解软件运行流程。
也可以使用Edit With IDLE 3.7编辑工具来运行Python脚本。
4.子功能模块介绍:
串口调试助手带有十六进制收发功能;
串口参数设定功能;
数据保存功能,可保存到指定文件;
带有定时发送功能,时间可设定;
带有详细注释,初学者可快速上手;
波形曲线程序带有波形数据保存功能;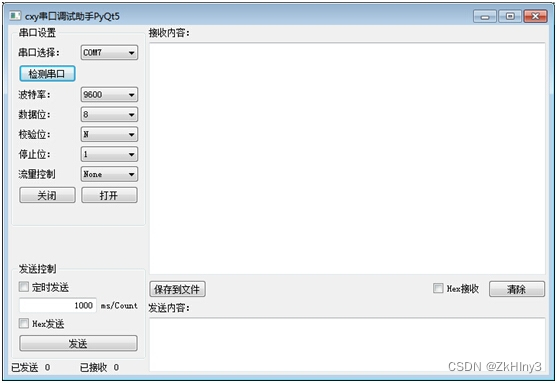
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3477
3477
08-10
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









