







来源:简书(FesonX)
简介
首先必须明确,分类和聚类是两个不同的东西。
分类的目的是确认数据属于哪个类别。分类必须有明确的边界,或者说分类是有标准答案的。通过对已知分类数据进行训练和学习,找出已知分类特征,再对未知分类的数据进行分类。因此分类通常是有监督学习。
聚类的目的是找出数据间的相似之处。聚类对边界的要求不是很高,是开放性命题。聚类只使用无标签数据,通过聚类分析将数据聚合成几个,因此采用无监督学习算法。
现在的做法是先用无监督聚类对数据进行聚类,把聚类效果结合实际进行评估,然后小部分数据进行标注,送到分类器分类,这也就是半监督学习。
有监督分类学习算法在学术界已经有非常详尽的理论化的评价指标,例如正确率,召回率,精准率,ROC曲线,AUC曲线。但是关于无监督学习的聚类评价指标在教材上尚无统一表述。根据 Sk-learn 官方文档结合现有资料做一个总结。需要说明的是没有哪一种指标是万能的,正如没有哪一种聚类算法是万金油.
聚类效果的衡量指标分为两大类,一类是外部信息评价,一类是内部信息评价。
评价聚类效果的好坏,才能确定聚类能否被应用到实际中做进一步处理。度量聚类结果的好坏不是简单地统计错误的数量,比如极端情况下,聚类算法把要分类的每一个文档都划分为一个类,那么错误数量为零,能代表这个聚类算法是最优的吗?这里的统计错误数量实际上就是去分析外部信息,靠人去判断样本是不是划分类准确,但是数据量增大了,比如增大到 10w+ 篇文章还能靠人去逐个判断吗?
外部信息指标
除了上面的准确率外,笔者另外选出比较容易操作的几个指标。
假设数据已经标注完毕,作为参考簇C,算法聚类形成簇D,样本总数为 m。下面以D作为Different的缩写,S为Same的缩写。那么,
a = 在C中为相同簇在D中为相同簇的样本数量(SS)
b = 在C中为相同簇在D中为不同簇的样本数量(SD)
c = 在C中为不同簇在D中为相同簇的样本数量(DS)
d = 在C中为不同簇在D中为不同簇的样本数量(DD)
调整后的 Rand 指数(Adjusted Rand Index,ARI)
这个指标用于测量标注的样本(labels_true,C)与预测的样本(labels_pred,D)之间的相似度,忽略样本的排列顺序,标签的命名对结果无影响,同时由于该指标是对称的,交换参数不影响得分。
数学表示
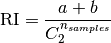
Rand Index

Adjusted Rand Index
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24242424242424246
# Exchange Position
>>> labels_pred = [0, 1, 0, 1, 2, 2]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24242424242424246
# Alter Tag Name
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24242424242424246
# Exchange Parameter Position
metrics.adjusted_rand_score(labels_pred, labels_true)
0.24242424242424246
优点:
- 范围有界,[-1, 1],值越大聚类效果越好。
- 随机标签获得接近 0 的值。
- 对簇的结果不需要做任何假设。
缺点:
- 实际操作中大数据量基本不可用,需要人工标注。
Fowlkes-Mallows 指数(Fowlkes-Mallows index,FMI)
这个指标被定义为成对的准确率(pairwise precision )与召回率(recall)的几何平均值
数学表示
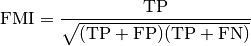
FMI
如果用前面假设的字母表示,则表示为
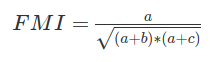
FMI
再说明一次,a就是SS,b就是SD,c就是DS,d就是DD。FMI 与 ARI 一样忽略样本的排列顺序,标签的命名对结果无影响。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
优点与缺点和 ARI 基本一致,不过 FMI 的范围是 0 到 1。
Jaccard 指数
这个指标用于量化两个数据集之间的相似性,1表示两个数据集是相同的,0则表示二者没有共同的元素。
数学表示
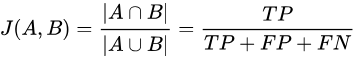
Jaccard
按前面的假设,也可以是

image.png
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.jaccard_similarity_score(labels_pred, labels_true)
0.5
内部信息指标
上面外部信息评价指标的缺点均为人工标注在大规模数据下不可行,因此,我们需要借助其他的数字指标,来分析聚类的内部信息。聚类是为了让同一个簇内样本尽可能的近,不同簇的样本尽可能远(类内高聚合、类间低耦合)。理想情况下,我们希望每个簇只包含一个类的成员(也就是所谓的同质性(homogeneity)),给定类的所有成员都分配给同一个簇(也就是所谓的完整性(completeness))。
从上面的表述中,在没有已标注数据的情况下,需要寻找能表达聚类紧凑度和分离度的内部信息指标。
轮廓系数(Silhouette Coefficient )
轮廓系数由两个得分组成,一是样本与同一个簇中其他点之间的平均距离(记为a)。二是样本与下一个距离最近的簇中其他点的平均距离(记为b),根据公式计算出单个样本的轮廓系数,然后计算整组的轮廓系数平均值。
数学表示

单个样本轮廓系数
优点
簇紧凑且分离度高时分数更高。
缺点
凸簇比其他类型的簇分数更高。比如基于密度的 DBSCAN 算法在这种情况下表现更好。
这里的凸簇如果降维到一定程度,会接近于凸集。根据定义,对于集合内的每一对点,连接该对点的直线段上的每个点也在该集合内。凸集的边界总是凸曲线。
Calinski-Harabaz 指数
此指标又被称为方差比标准(Variance Ratio Criterion),定义为簇内色散平均值(dispersion,量化一组事件是聚类还是分散的度量)与簇间色散的比值。
数学表示

CHI
其中,k表示聚类的数目,N为数据的点数,Tr(Bk)为簇内色散矩阵的迹,Tr(Wk)为簇间色散矩阵的迹。Cq为簇q的点集,cq为簇q的中心店,nq为簇q的点数。
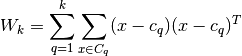
Wk
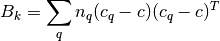
Bk
优点
簇紧凑且分离度高时分数更高。
缺点
凸簇比其他类型的簇分数更高。比如基于密度的 DBSCAN 算法在这种情况下表现更好。
除了上述指标外,在分析聚类算法效果优劣时,还要讨论算法处理噪声的能力,对数据维度是否敏感,对数据密度是否有要求等。















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









