







文章转载自:https://blog.csdn.net/weixin_41108334/article/details/83029582 (作者:work_coder)
基础概念 Multiple-Instance learning( MIL )
根据训练数据的歧义性大小,大致可以把在该领域进行的研究划分为三种学习框架:监督学习、非监督学习和强化学习。监督学习的样本示例带有标记;非监督学习的样本示例没有标记,因而该学习模型的歧义性较大。多示例学习可以认为是与三种传统学习框架并列的第四种学习框架,由Dietterich等人于1997年提出,提出的背景是通过一项对分子活性的研究,文章是"Solving the Multiple-Instance Problem with Axis Parallel Rectangles" ,下面就对多示例问题做一个概念性的介绍。
多示例学习可以被描述为:假设训练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。(这里说包中的示例没有标记,而后面又说包中至少存在一个正标记的示例时包为正标记包,是相对训练而言的,也就是说训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别)。通过定义可以看出,与监督学习相比,多示例学习数据集中的样本示例的标记是未知的,而监督学习的训练样本集中,每个示例都有一个一已知的标记;与非监督学习相比,多示例学习仅仅只有包的标记是已知的,而非监督学习样本所有示例均没有标记。但是多示例学习有个特点就是它广泛存在真实的世界中,潜在的应用前景非常大。
多示例学习近几年已经逐渐被用于基于机器学习框架的组织病理学图像癌症检测等方面,是计算机辅助诊断这一学科中一种新崛起的方法,下面就按照我在论文和网上学到的知识对多示例学习进行一下简单的介绍。
在介绍多示例学习之前,首先要了解两个概念:包(bags)和示例(instance)。包是由多个示例组成的,举个例子,在图像分类中,一张图片就是一个包,图片分割出的patches就是示例。在多示例学习中,包带有类别标签而示例不带类别标签,最终的目的是给出对新的包的类别预测。有人说多示例学习是监督学习的一种扩展,不过我更加倾向于认为多示例学习是介于监督学习与无监督学习之间且不同于半监督学习的一种学习方法,因为用于训练分类器的示例是没有类别标记的,但是包却是有类别标记存在的,这一点与以往的所有框架均不甚相同。还有一点就是多示例学习特有的规则:如果一个包里面存在至少一个被分类器判定标签为+的示例,则该包为正包;如果一个包里面所有的示例都被分类器判定标签为-,则该包为负包。
多示例学习仅仅在全局注释的图片上进行训练,但却往往可以给出patch级或者像素级的标签。在我看过的几篇论文中,如果要求MIL框架可以给出patch级别的标签也就是给出instance级别的标签,那么训练样本中的instance必须存在标签(仅仅标注一部分也可以)。
特征
多示例学习中,定义“包”为多个示例的集合。与其他Classification方法不同,此方法仅对“包”作标签,“包”中的示例并无标签。定义“正包”:包中至少有一个正示例;反之,当且仅当“包”中所有示例为负示例时,该“包”为“负包”。
多示例学习的目的:①归纳出单个示例的标签类别的概念。②计算机通过对这些已标注的“包”学习,尽可能准确地对新的“包”的标签做出判断。
我们就拿图像分类举个例子:图像分类是基于图像内容来确定图像目标的类别。例如:一张图片上存在“sand”、“water"等各种示例,我们研究的目标是"beach”。在多示例学习中,一张图像作为一个“包”:
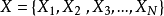 ,
, 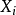 是特征向量(也就是我们所说的示例),是从图像中对应的第i个区域中提取出来的,总共存在N个示例区域。那么,“包”中当且仅当"sand"和"water"都存在时,此“包”才会作上“beach”标签。显然,利用这种方法来研究图像分类就考虑到了图像中元素之间关系,相比单示例方法在某些情况下得出的分类效果更好。
是特征向量(也就是我们所说的示例),是从图像中对应的第i个区域中提取出来的,总共存在N个示例区域。那么,“包”中当且仅当"sand"和"water"都存在时,此“包”才会作上“beach”标签。显然,利用这种方法来研究图像分类就考虑到了图像中元素之间关系,相比单示例方法在某些情况下得出的分类效果更好。
多示例学习方法是20世纪90年代人们在研究药物活性时提出来的。1997年,T. G. Dietterich 等人对药物活性预测问题进行了研究。其目的是构建一个学习系统,通过对已知适于或不适于制药的分子进行学习,尽可能正确地预测其他新的分子是否适合制药。由于每个分子都有很多种可能的稳定同分异构体共存,而生物化学家只知道哪些分子适于制药,并不知道其中的哪一种同分异构体起到了决定性作用。如果使用传统的有监督学习的方法,将适合制药的分子的所有稳定同分异构体作为正样本显然会引入很多噪声。因此,提出来多示例学习的问题。
多示例学习自提出十几年以来,一直成为研究的热点。从最初T. G. Dietterich等人提出该方法时给出的三个基于轴平行矩形的方法,到后来的DD、EMDD、Citation-kNN,以及SVM、神经网络、条件随机场方法在多示例学习中的运用。
多示例学习具有广泛的应用,例如:图像检索、文本分类等。















 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









