





机器学习示例
Where’s Wally? Let’s scan the faces: “no no no no no no no.. yes!” From your eyes taking in the visual stimuli, you can associate whether the faces in the sea of people belong to the one you’re looking for or not.
沃利在哪里? 让我们扫描一下脸部:“不,不,不,不,不,是。!” 通过眼睛的视觉刺激,您可以关联人海中的面Kong是否属于您要寻找的面Kong。
You have just performed a function to identify a particular face — something that we are evolutionarily fantastic at. Your smartphone may have a facial recognition unlock function based on a neural network that maps an image of your face to your identity. A neural network is a type of mathematical function that maps a given input to a desired output.
您刚刚执行了一项功能来识别一张特定的面Kong- 我们在进化上很赞 。 您的智能手机可能具有基于神经网络的面部识别解锁功能,该功能将您的面部图像映射到您的身份。 神经网络是将给定输入映射到所需输出的一种数学函数。

So how does a neural network learn to do this? Like trying to make a dog play fetch we must train it!
那么神经网络如何学习做到这一点呢? 就像想让狗玩起来一样,我们必须训练它!
For comparative purposes; a toddler may have the capacity to learn what a puppy is after seeing one or two examples..Whereas a data hungry neural network takes a lot of time and energy to learn feature representations of a particular class after seeing up to tens of thousands of samples during training.
出于比较目的; 幼儿可能会在看到一个或两个示例后就具有学习小狗的能力。而数据饥渴的神经网络在查看了成千上万个样本后需要花费大量的时间和精力来学习特定类别的特征表示。在训练中。
This is madness! What is this training you speak of? There are two primary components of training a neural network. First we have forward propagation, in the beginning this is essentially a guess as to what the correct answer/output might be. I also talk about how this occurs in computer vision in my first article.
这太疯狂了! 您说的是什么培训? 训练神经网络有两个主要组成部分。 首先,我们进行正向传播 ,从一开始,这实际上是对正确答案/输出可能是什么的猜测。 在第一篇文章中,我还将讨论计算机视觉中的这种情况。
Then we compare the correctness (or error) of our guess to the actual answer and based on that, recursively update parts of the network backwards so that future guesses are more accurate. This step is called backpropagation.
然后,我们将猜测的正确性(或错误)与实际答案进行比较,并在此基础上向后递归更新部分网络,以使将来的猜测更加准确。 此步骤称为反向传播。
Over multiple iterations our network gets better and better at guessing the right answer.. One might even say it is making predictions! ;o
经过多次迭代,我们的网络在猜测正确答案方面变得越来越好。甚至有人说它正在做出预测! ; o
Keep in mind the initial intuition behind a neural network is loosely to replicate the firing of neurons in the brain, reinforcing the firing of particular sequences of neurons in response to a given stimulus.
请记住, 神经网络背后的最初直觉是宽松地复制大脑中神经元的放电,从而增强对特定神经元序列的放电,以响应给定的刺激。
Let’s introduce the components of a neural network:
让我们介绍一下神经网络的组成部分:
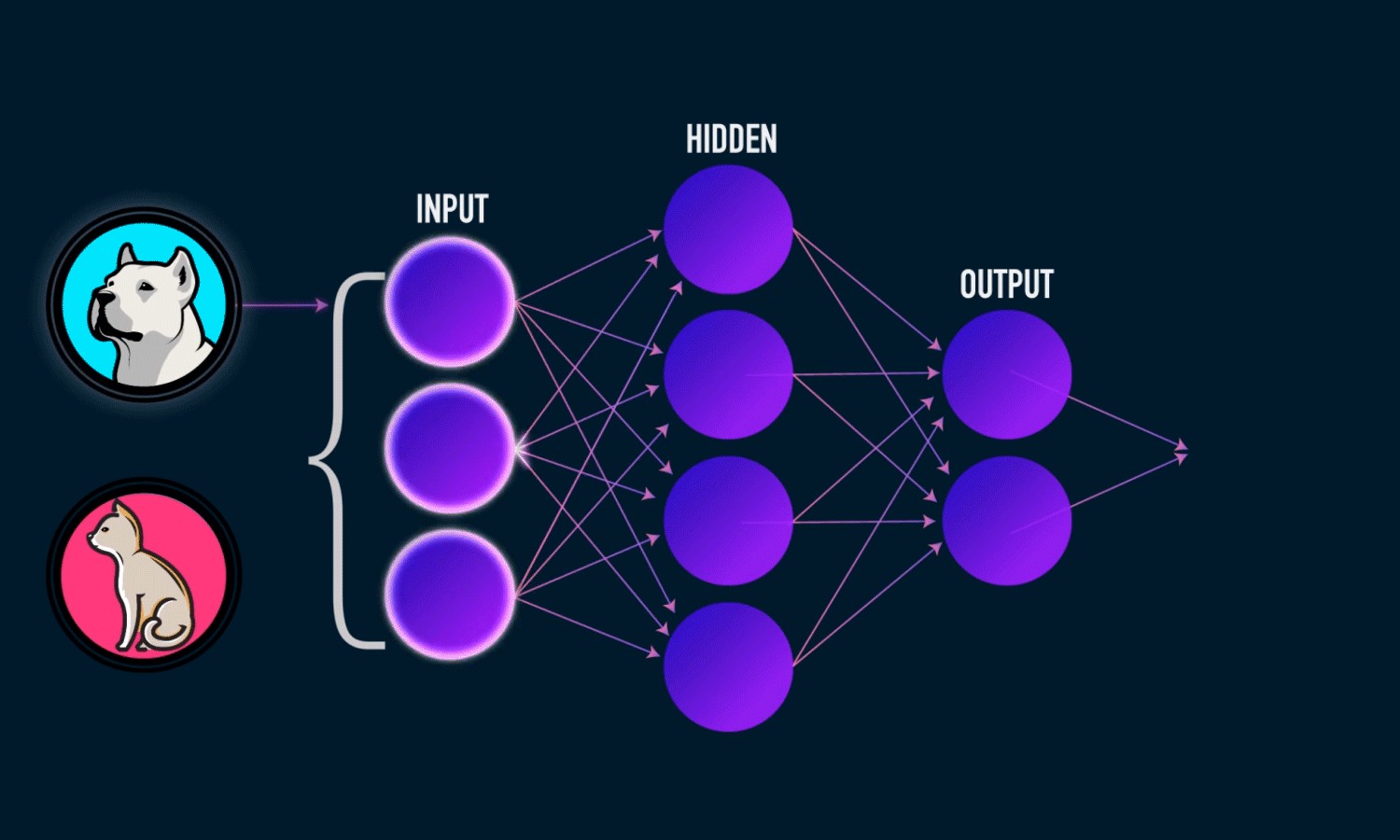
Input Layer, x
输入层, x
- Hidden Layer(s) 隐藏层
Output Layer, ŷ
输出层, ŷ
Weighted Connections, Wᵢ and biases, bᵢ between each layer
每一层之间的加权连接Wᵢ和偏置bᵢ
You can see these are connected as an acyclic graph, where neurons in each layer have weighted connections — synapses to the next layer. These weights amplify or dampen the response of it’s inputs.
您可以看到它们以无环图的形式连接在一起,其中每一层中的神经元都有加权连接- 突触到下一层。 这些权重会放大或减弱其输入的响应。
Additionally we do not count the input layer, so the figure you see above is a two-layer neural network; we have one output layer and one hidden layer.
另外,我们不计算输入层,因此您在上面看到的图是两层神经网络。 我们有一层输出层和一层隐藏层。
As for an individual neuron’s input, what this does is:
至于单个神经元的输入,它的作用是:
- Multiply the inputs by the weights 输入乘以权重
- Sum these values and add the bias 对这些值求和并加上偏差
- Pass the entire value through an activation function 通过激活函数传递整个值
And that’s Forward Propagation! What we’ve done is pass input values through our network to get an output value, voila.
这就是正向传播 ! 我们要做的是通过网络传递输入值以获得输出值voila。
For those more interested in the calculus behind this you check out the Appendix at the bottom.
对于那些对背后的演算更感兴趣的人,请查看底部的附录。
Now we determine how close our model output ŷ is to the actual value y. For this we use a loss function. One simple loss function is taking the sum of squared errors over our samples:
现在我们确定模型输出ŷ与实际值y有多接近。 为此,我们使用损失函数 。 一个简单的损失函数是对样本进行平方误差总和:

Recall that in training we want to optimise the weights and biases to minimise the loss function. To do this we propagate the error backwards using a popular method called gradient descent. Again the calculus behind this will be covered in the Appendix for those interested.
回想一下,在训练中,我们希望优化权重和偏差以最小化损失函数 。 为此,我们使用一种称为梯度下降的流行方法将误差向后传播。 同样,对此感兴趣的人将在附录中涵盖其背后的计算。
With gradient descent we backpropagate the error through our model neural network to update the weights and biases which incrementally reduces the error of our loss function until we can do so no more, reaching the local minima.
借助梯度下降,我们通过模型神经网络 反向传播误差,以更新权重和偏差,从而逐步减少损失函数的误差,直到我们不再这样做,达到局部最小值为止。
Whilst there are other nuances that can be considered such as the learning rate, overfitting, normalisation etc.. and much more to get stuck into. We have just gone through how a neural network is able to ‘learn’ a function which takes an input and maps it to a desired output!
同时,还可以考虑其他细微差别,例如学习率,过度拟合,归一化等,还有很多其他问题需要坚持。 我们刚刚介绍了神经网络如何“学习”一个接受输入并将其映射到所需输出的函数!

And now for the examples! In our everyday life we interact with perhaps more than we think and this is likely to increase in the future, below are a few:
现在为示例! 在我们的日常生活中,与我们的互动可能比我们想象的要多,并且在未来可能会增加,以下是一些:
Targeted Advertising: Using your details and information as input parameters, say age, sex and location, one could train a neural network to determine which adverts will have the highest engagement rates with personalised marketing.
定向广告:使用您的详细信息作为年龄,性别和位置等输入参数,可以训练神经网络来确定哪些广告将通过个性化营销获得最高的参与度。
Automated Chatbots: Faster interactions in online chat experiences to answer your questions and upgrade user experiences. This falls under the natural language processing domain and is offered as a service by Microsoft.
自动化的聊天机器人:在线聊天体验中的互动速度更快,可以回答您的问题并提升用户体验。 这属于自然语言处理领域,由Microsoft作为服务提供。
Credit Rating: Determining the risk of individual customers can be possible as Oracle writes about it in their blog.
信用等级: Oracle可以在个人博客中确定个人客户的风险,这一点可以确定。
Financial Forecasting: Investors willing to utilise neural networks to make investments hope to gain a competitive advantage, one such company is TwoSigma.
财务预测:愿意利用神经网络进行投资的投资者希望获得竞争优势, TwoSigma是一家这样的公司。
Fraud Detection: Many companies handling any kind of transaction may have to deal with fraudulent transactions. To stay one step ahead, organisations can utilise neural networks to detect anomalies.
欺诈检测:处理任何类型交易的许多公司可能不得不处理欺诈交易。 为了保持领先地位,组织可以利用神经网络来检测异常 。
Awesome! We made it to the end!
太棒了! 我们做到了!

More examples related to computer vision in my prior two articles:
在我之前的两篇文章中,有关计算机视觉的更多示例:
Computer Vision AI: Explainer and Examples — Analytics Vidhya
Further Resources:
更多资源:
Thanks for reading, hope you learnt something! Also ❤❤ Calvin & Venus.
感谢您的阅读,希望您学到了一些东西! 也是❤❤加尔文和维纳斯。
Steven Vuong, Data Scientist
数据科学家Steven Vuong
Open to comments, feedback and suggestions for the next article.stevenvuong96@gmail.comhttps://www.linkedin.com/in/steven-vuong/https://github.com/StevenVuong/
开放下一篇文章的评论,反馈和建议。 stevenvuong96@gmail.com https://www.linkedin.com/in/steven-vuong/ https://github.com/StevenVuong/
Appendix: S’more Calculus behind Forward and Back Propagation for the mathematical marshmallows
附录:数学棉花糖向前和向后传播背后的S'more微积分
First, we have Forward Propagation. To explain this, better we can look at first how an individual neuron takes inputs and produces an output:
首先,我们有正向传播 。 为了解释这一点,更好的是,我们首先来看一个神经元如何获取输入并产生输出:
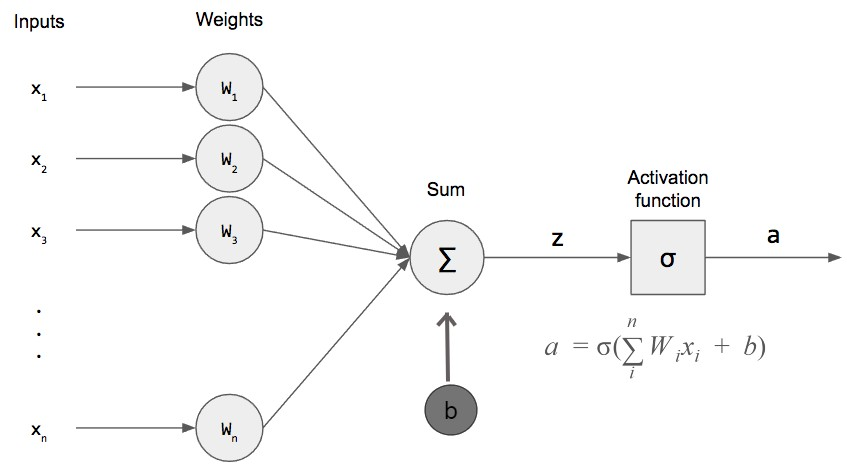
What we see above are the inputs being multiplied by the weights and summed with the bias. These are then passed through an activation function, denoted with sigma, to produce an output.
上面我们看到的是输入乘以权重并加上偏差。 然后将它们传递给激活函数 (用sigma表示)以产生输出。
One commonly used activation function is the sigmoid function:
S型函数是一种常用的激活函数:
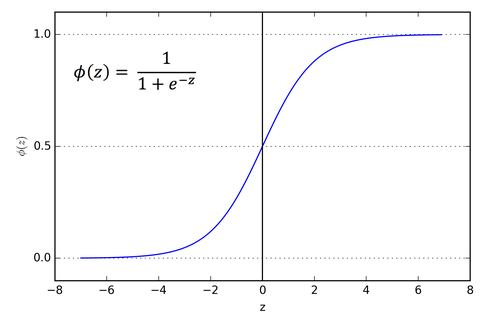
An important feature is that it is differentiable at any point, meaning we can determine the slope between any two points along the z-axis.
一个重要的特征是它在任何点都是可微的,这意味着我们可以确定沿z轴的任意两个点之间的斜率。
Activation functions are required to introduce non-linearity to our model.
需要激活函数才能将非线性引入我们的模型。
So for initial inputs x₁, our first layer outputs are the first layer weights multiplied by the input and summed with the bias before inserting it into our activation function.
因此,对于初始输入x₁,我们的第一层输出是将第一层权重乘以输入并与偏差相加,然后再将其插入到激活函数中。
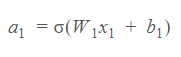
And as our first layer output is the same as our second layer input, we can state:
并且由于我们的第一层输出与我们的第二层输入相同,我们可以声明:

Giving us our second layer output of:
给我们第二层输出:
And because our second layer is our final layer, we have:
由于我们的第二层是最后一层,因此我们具有:
Bing bang boom! Piecing this all together for our two-layer neural network, we have:
砰砰的繁荣! 为我们的两层神经网络将所有这些结合在一起,我们有:
Which gives us our model output ŷ, hurrah!
这给了我们模型输出ŷ,哇!
Before we continue, gif break!
在继续之前,gif中断!

Recall from earlier that we use the sum-of-squared error as our loss function:
回想一下,我们使用平方误差作为损失函数 :
For backpropagation we use the chain rule to calculate the partial derivatives with respect to our weights and biases in order to adjust these accordingly. These allow us to determine the local minima of the cost function over multiple steps. For this we use gradient descent.
对于反向传播,我们使用链式规则来计算相对于我们的权重和偏差的偏导数,以便相应地进行调整。 这些使我们能够通过多个步骤确定成本函数的局部最小值。 为此,我们使用梯度下降 。
So as an example of determining the amount we update W₂ by, we can calculate:
因此,作为确定更新W 2的数量的示例,我们可以计算:

And finally we can update the parameter W₂:
最后我们可以更新参数W²:

Where μ is how much we want to adjust W₂. This is known as the learning rate. After applying the same principles to b₂, then our first layer parameters W₁ and b₁, we have completed one whole training epoch!
μ是我们要调整W 2的量。 这就是所谓的学习率 。 在将相同的原理应用于b2之后,然后将我们的第一层参数W 1和b 4应用于b2,我们已经完成了一个完整的训练时期 !
翻译自: https://medium.com/analytics-vidhya/how-machines-learn-ai-explainer-and-examples-daa71a472716
机器学习示例















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









