










目录
(2)、模型复杂度(输出flops,params)(官方说,仅供参考)
(4)、COCO 分离和遮挡实例分割性能评估(只适用于实例分割模型(mmdet3.0.0))(只适用于coco本体数据集)
一、相关网页
- https://openmmlab.com/(官网)
- OpenMMLab · GitHub(github官网)
- [mmsegmentation] mmsegmentation的linux安装记录_captain飞虎大队的博客-CSDN博客
- mirrors / open-mmlab / mmdetection · GitCode(csdn加速)
二、不同用途网页
(一)、detect
- Swin Transformer目标检测4——训练自己数据集 - beyonderwei
- 开始你的第一步 — MMDetection 3.0.0 文档(6.19测试安装mmdet有误)(6.19修正:完全按照官网教程测试demo成功,mmdet需要使用git源码,mim安装有误,csdn加速有误)
- 深度学习之目标检测(Swin Transformer for Object Detection)_swin l目标检测_qq_41627642的博客-CSDN博客
- Swin Transformer 代码学习笔记(目标检测)_swin transformer目标检测_athrunsunny的博客-CSDN博客
- Swin Transformer做主干的 Faster RCNN 目标检测网络(mmdetection)_swintransformer为主干的_Beyonderwei的博客-CSDN博客
- 在标准数据集上训练预定义的模型(待更新) — MMDetection 3.0.0 文档(按照这个流程成功开始训练)
- 使用mmdetection训练自己的coco数据集(免费分享自制数据集文件)_coco mmdetection_gy-7的博客-CSDN博客
- mmdetection测试阶段生成各种评价指标,pkl,mAP,APm,APs,APl等_pkl文件是怎么训练出来的_北京纯牛奶的博客-CSDN博客
- mmdetection目标检测过程参数_mmdetection参数_盛世芳华的博客-CSDN博客
(二)、segment
三、个人训练测试心得
(一)、detect
按照官方教程进行训练与测试,其过程分为以下几步:
1、创建数据集
将数据集转换为coco格式,将图片与标签信息共同生成json文件,分为训练集与测试集两个json,分别与图片一起放置在不同文件夹当中,其格式如下:

以下是几种将其他数据格式转换为coco的方式:
(1)、将yolo格式txt文件转换为coco数据集json格式
(2)、等用到了再说。
2、创建配置文件(需改进,系统化)
在config文件夹下,创建自定义参数文件夹,例如person,并在其中创建配置文件,例如mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py,其内容如下所示:
# 新配置继承了基本配置,并做了必要的修改
_base_ = '../mask_rcnn/mask-rcnn_r50-caffe_fpn_ms-poly-1x_coco.py'
# 我们还需要更改 head 中的 num_classes 以匹配数据集中的类别数
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1), mask_head=dict(num_classes=1)))
# 修改数据集相关配置
data_root = 'data/balloon/'
metainfo = {
'classes': ('balloon', ),
'palette': [
(220, 20, 60),
]
}
train_dataloader = dict(
batch_size=1,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='train/annotation_coco.json',
data_prefix=dict(img='train/')))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='val/annotation_coco.json',
data_prefix=dict(img='val/')))
test_dataloader = val_dataloader
# 修改评价指标相关配置
val_evaluator = dict(ann_file=data_root + 'val/annotation_coco.json')
test_evaluator = val_evaluator
# 使用预训练的 Mask R-CNN 模型权重来做初始化,可以提高模型性能
load_from = 'https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'
主要包含即修改的部分:使用的模型信息(_base_)、需要检测的类别数(num_classes=1、不算背景)、数据集位置(data_root)、数据集类别名称(classes)、训练集与测试集json文件名称(ann_file、有三处)、训练集与测试集名称(data_prefix,有两处)、预训练文件下载地址(load_from,自己搭的网络应该是没有的)。
有关于预训练文件的部分,如果使用的模型代码中包含预训练文件的下载地址,最好是自行下载后,将其替换为自己存放的位置,例如:
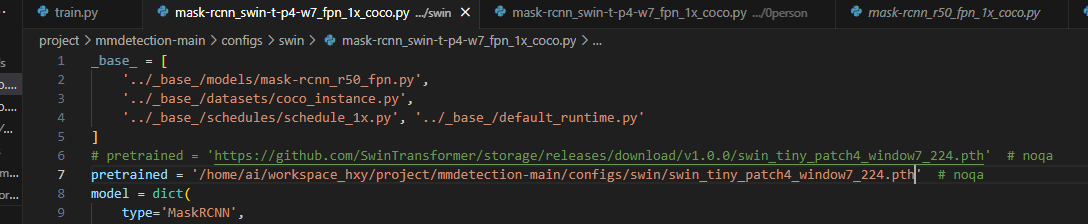
因为在训练过程中下载可能会出问题,比如网络无法连接。
其文件夹格式如下:
最好在文件夹名称前加个0,这样能够区分自己创建的和原先的。
3、训练
训练时,首先通过cd进入工程所在文件夹,即mmdetection,然后在终端输入:
python tools/train.py --config configs/balloon/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py其中,“--config”后跟的是前面创建的配置文件。
在训练时,会在主目录下创建文件夹work_dirs(如果之前没有),并在其下产生与配置文件同名的文件夹,训练好的参数文件就在其中(不足之处:没有将效果最好的模型参数单独提取出来),另外还会生成一个py文件,其中包含配置内容的全部信息,可以从此处修改所有需要修改的参数(除了上面介绍的,还有像是max_epochs,checkpoint interval(训练多少轮保存一次参数)、val_interval(训练多少轮进行一次验证))。
根据训练的时间不同,会在该文件夹下产生不同的带时间戳文件夹,内部包含终端产生的日志。
其文件夹格式如下所示:
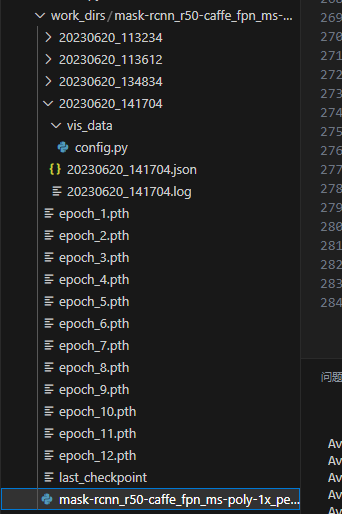
其中,json文件为训练或测试时的结果输出,config为训练或测试时的全部参数,与配置文件相同。
训练时会看到以下内容:
06/20 16:55:09 - mmengine - INFO - Epoch(train) [3][2250/3207] lr: 1.0000e-04 eta: 1:55:59其中eta代表剩余训练时长
4、测试
测试时,在终端输入:
python tools/test.py --config xxxxxx --checkpoint xxxxxx其中,‘--config’后跟的是配置文件(可以选择训练时的配置文件,也可以选择work_dirs中的文件),‘--checkpoint’后跟的是训练好的参数(在work_dirs中,也可以是预训练参数)。
在进行测试时,同样会在work_dirs中对应的文件夹下生成带时间戳文件夹,内部包含信息参考上一节说明。
如果在终端输入(比上面慢许多,可能是因为在一张张进行推理,官方文档说是默认一张,但是可以同时处理多张,经过测试,发现在速度上并没有明显变化,其代码为 --cfg-options test_dataloader.batch_size=16):
python tools/test.py --config xxxxxx --checkpoint xxxxxx --show-dir result将会在带时间戳文件夹下,生成一个result文件夹,其中包含测试图像对比,左边为带gt标签的原始图像,右边为带预测标签的预测图像,例如:
(这里先不放图了,想起来这个数据集需要保密)
此外,还可以在终端输入‘--out result.pkl’生成文件,可以使用mmset提供的数据分析工具对该文件进行分析,从而得到测试时的一些结果,例如混淆矩阵。
上面是直接利用之前的验证集进行测试的结果,如果想测试一批无标签数据,那么需要做以下几步:
(1)、通过在终端输入以下内容,利用待测数据生成json文件:
python tools/dataset_converters/images2coco.py --img_path xxxxx --classes xxxx --out xxxx其中,img_path为图片所在文件夹,classe为类列表文本文件名,文本中每一行存储一个类别,out为输出文件位置,需要为json文件。
(2)、修改配置文件中的test_dataloader,具体如下图所示: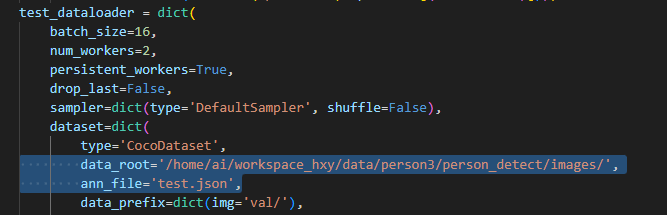
(3)、跟上方带标签测试相同,在终端输入代码、配置文件、模型参数等信息进行测试。
5、实用工具
mmdet官方提供了一些实用工具,下面列出几个我觉得比较重要的(其他的内容参考官方链接):
(1)、模型服务部署
(2)、模型复杂度(输出flops,params)(官方说,仅供参考)
(3)、混淆矩阵
在终端输入:
python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} 其中config为配置参数文件,detection results为.pkl文件,save dir为混淆矩阵图像保存界面。
该代码有部分问题需要解决:
①、保存图像显示不完全:
②、数值显示部分按以下标注内容修改:
# draw confution matrix value
thresh = confusion_matrix.max() / 2.#设置颜色阈值
for i in range(num_classes):
for j in range(num_classes):
ax.text(
j,
i,
'{:.2f}%'.format(confusion_matrix[i,j] if not np.isnan(confusion_matrix[i, j]) else -1),#显示百分比保留两位小数
ha='center',
va='center',
color="white" if confusion_matrix[i, j] < thresh else "black",#在不同阈值范围内,字体显示不同的颜色
size=5)#字体大小修改为5③、遇到报错:
UserWarning: Tight layout not applied. The left and right margins cannot be made large enough to accommodate all axes decorations.
fig.tight_layout()这个应该是在提醒显示不完全,待解决。
(4)、COCO 分离和遮挡实例分割性能评估(只适用于实例分割模型(mmdet3.0.0))(只适用于coco本体数据集)
在终端输入:
python tools/analysis_tools/coco_occluded_separated_recall.py results.pkl --out occluded_separated_recall.json --ann val.json其中results.pkl为测试时保存的pkl文件,out后跟结果保存地址,ann后跟测试集json地址。
经过测试后发现,该代码只适用于coco文件,原因如下:
class CocoOccludedSeparatedMetric(CocoMetric):
def __init__(
self,
*args,
occluded_ann:
str = 'https://www.robots.ox.ac.uk/~vgg/research/tpod/datasets/occluded_coco.pkl', # noqa
separated_ann:
str = 'https://www.robots.ox.ac.uk/~vgg/research/tpod/datasets/separated_coco.pkl', # noqa
score_thr: float = 0.3,
iou_thr: float = 0.75,
metric: Union[str, List[str]] = ['bbox', 'segm'],
**kwargs) -> None:
super().__init__(*args, metric=metric, **kwargs)
self.occluded_ann = load(occluded_ann)
self.separated_ann = load(separated_ann)
self.score_thr = score_thr
self.iou_thr = iou_thr def compute_recall(self,
result_dict: dict,
gt_ann: list,
is_occ: bool = True) -> tuple:
correct = 0
prog_bar = mmengine.ProgressBar(len(gt_ann))
for iter_i in range(len(gt_ann)):
cur_item = gt_ann[iter_i]
cur_img_name = cur_item[0]
assert cur_img_name in result_dict.keys()occluded_ann与separated_ann两个文件时coco数据集的文件,目前没有发现应该替换成什么,这两个应该指的是有遮挡的数据与无遮挡的数据,检测其中的数据是否在测试集当中时,报错。
















 554
554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









