









目录
3、在检测中,相同设置下,detect与val生成图像中,检测框数量不同。
本文是我在使用YOLOv5时,做的一些过程记录,按照步骤走应该能够跟我获得相同的结果,初次写这种类型的文章,排版之类的可能不太好看,内容也不够充分,之后混慢慢修改补充。
本文内容包含代码的直接使用方式,与在自定义数据集上的使用方式,目前未使用过其他公开数据集进行试用。
一、直接试用方式
1、准备工作
配置conda,虚拟环境与torch,这一部分有很多教程,这里就不写了。
代码下载:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
环境准备:pip install -r requirements.txt。
或者按照官方教程文件:
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install
import torch
import utils
display = utils.notebook_init() # checks2、代码测试
(1)、模型训练(可以跳过)
打开segment/train.py,直接运行,会自动下载预训练模型参数yolov5s-seg.pt与数据集coco128-seg,模型参数会下载到yolov5目录下,数据集会下载到yolov5父目录下。训练结果会保存在runs/train-seg/exp中。
或者自行下载模型参数:https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt

(2)、模型预测
打开segment/predict.py,直接运行,会将/home/w/下载/yolov5-master/data/images中的两张图像进行分割预测(没有使用上面的训练参数),分割结果会保存在runs/predict-seg/exp。
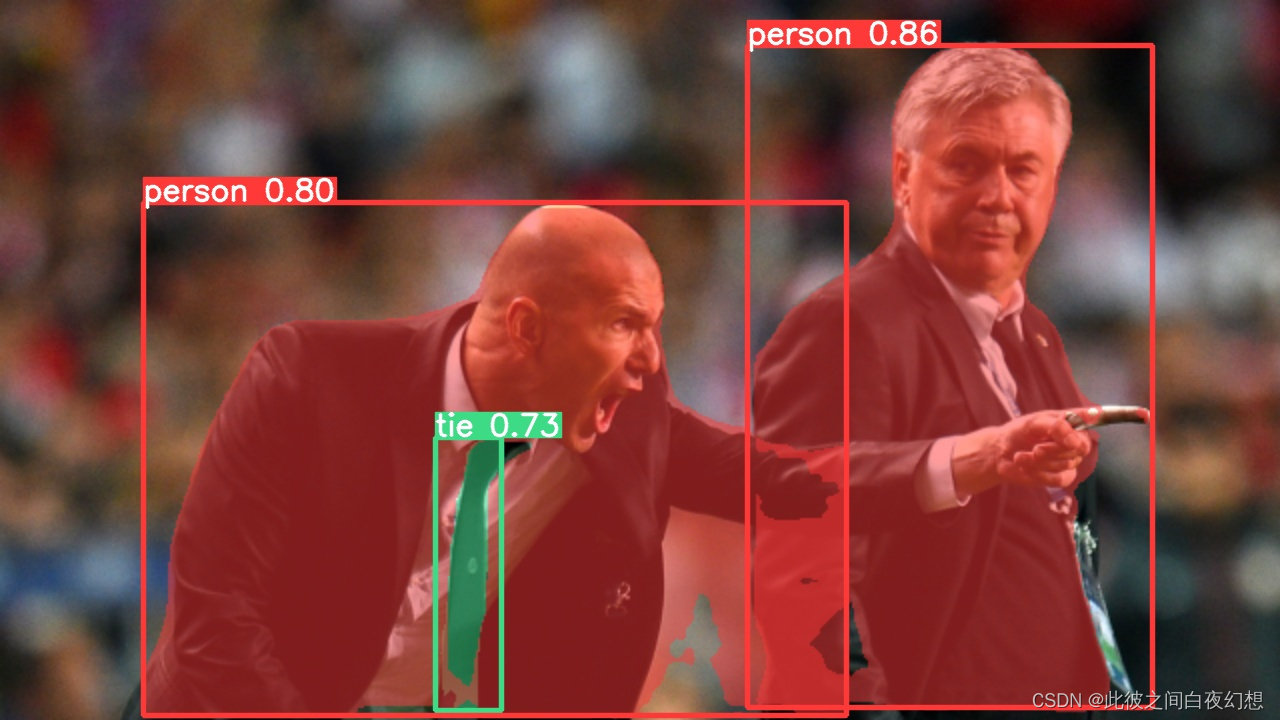
分割结果如下:

二、制作自己的数据集
1、格式
数据集文件夹格式:
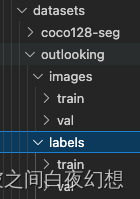
其中images文件夹下放的是原始图像,labels文件夹下放的是满足YOLOv5要求的txt标签文件。
将原始数据按照文件夹格式复制可参考:
https://blog.csdn.net/a1004550653/article/details/128329796
txt文件格式:
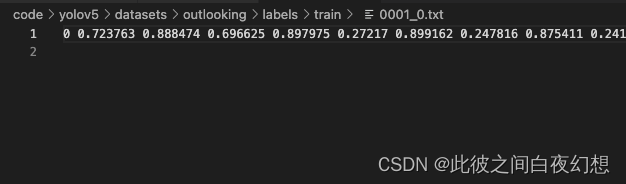
第一个数字为类别,后面每两个数字代表一个点对于整张图像的相对位置。每一行代表图像中的一个mask。
2、labelme制作标签
制作自己的数据集的话,打标签是无可避免的,用labelme就足以满足基本需求。这一部分的教程也很多,也就先不写了,有机会再加。
3、json转txt
通过labelme可以得到json格式的mask标签。按照下面的代码可以将其修改为需要的格式。
https://blog.csdn.net/a1004550653/article/details/128320398
4、修改数据集参数
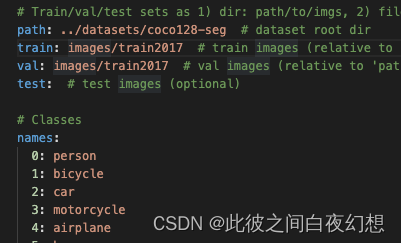
复制coco123_seg.yaml,修改名称,例如mydataset.yaml。
修改内部参数:
path为数据集目录,train为其子目录相对路径,val可以与train相同,test不用设置。names为不同的分类与名称,改成自己的就好。
三、用YOLOv5跑自己的数据集
1、train.py参数修改

weigeht是预训练模型,可以使用自己的,也可以下载官方的。
data是数据集格式,改成刚才创建的yaml名称。
hyp是数据增强,可以按照需求在文件内自行增改。
epochs为训练轮数,训练中会自动保存最好与最后一次的模型参数。
batch--size为一次训练的图片个数,配置够的话可以增加。
imgsz等为训练时的图像重置大小。
基本上只用动上面几个参数就够了,如果还有别的需求,可以看help里面的描述,自行修改。
例如下面还有个optimizer,优化器,默认sgd。
当参数带有action='store_true',那么默认不会运行,运行时需要用终端加上--xxx(例如Python train.py --nosave)。
2、predict.py参数修改
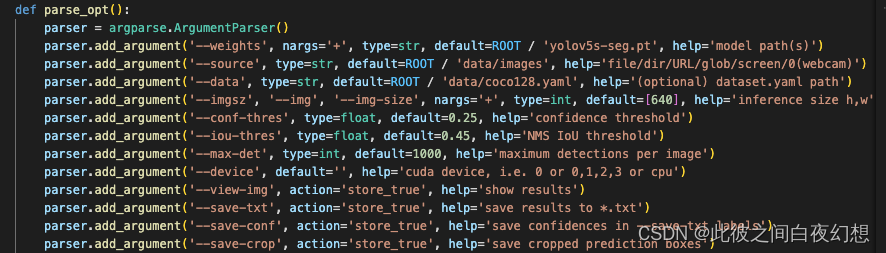
weight修改为训练得到的自己的权重,默认位置在run/train-seg/exp/weight下。
source为需要预测的图像文件夹。
data设置与train相同。
imgsz建议使用默认的640,数值增大,结果可能会更精细,但是检测框可能会不够大。
conf-thres为置信阈值,只有检测框的概率高于阈值时,才会被留下。
iou-thres为交并比阈值,在进行NMS(非极大值抑制)时,超过阈值的检测框会被删除。
max-det为一张图中检测框存在的最大数量,因为个人需要,我会设置为1。
save-txt会将分割结果按照YOLOv5的格式保存为txt文件,可以通过txt文件再转换为需要的mask。
save-crop会将检测框内部图像截图保存。
如果不加别的处理,原始图像经过predict.py后,会得到一张实例分割的图像。
3、txt2mask
将预测得到的txt转换为需要的mask图像。
https://blog.csdn.net/a1004550653/article/details/128313599
四、遇到过的报错与解决方式
- urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed_知·味的博客-CSDN博客
- https://ask.csdn.net/questions/7646221
五、原理(部分)
1、图像标签转换
在yolov5-seg中,准备的txt文件中包含的是类别与seg点位,在实际训练的过程中,seg点位会被转换为检测用的box信息,即xywh。具体的转换代码如下:
def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
if clip:
clip_boxes(x, (h - eps, w - eps)) # warning: inplace clip
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
return y
def segments2boxes(segments):
# Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
boxes = []
for s in segments:
x, y = s.T # segment xy
boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
return xyxy2xywh(np.array(boxes)) # cls, xywh2、分割原理
在yolov5s-seg模型下,图像重置大小设置为640,将图片与标签输入模型后得到pred与proto。
其中pred形状为[1, 22680, 38],经过nms后得到检测框信息,每个检测框形状为[1, 38],向量中0-3为检测框位置,4为检测框的置信度,5为分类,6-37为mask协方差系数。
proto的形状为[1, 32, 160, 144],(160,144)是输入图像下采样两次后的大小。
mask的求取方法为,用pred中的mask的协方差系数,与proto做矩阵乘法,得到mask的具体输出,大小为[1, 160, 144],再经过crop_mask,只保留检测框范围内的数据,最后经过上采样,大小为[1, 640, 576]。
def crop_mask(masks, boxes):
"""
"Crop" predicted masks by zeroing out everything not in the predicted bbox.
Vectorized by Chong (thanks Chong).
Args:
- masks should be a size [h, w, n] tensor of masks
- boxes should be a size [n, 4] tensor of bbox coords in relative point form
"""
n, h, w = masks.shape
x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
def process_mask(protos, masks_in, bboxes, shape, upsample=False):
"""
Crop before upsample.
proto_out: [mask_dim, mask_h, mask_w]
out_masks: [n, mask_dim], n is number of masks after nms
bboxes: [n, 4], n is number of masks after nms
shape:input_image_size, (h, w)
return: h, w, n
"""
c, mh, mw = protos.shape # CHW
ih, iw = shape
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
downsampled_bboxes = bboxes.clone()
downsampled_bboxes[:, 0] *= mw / iw
downsampled_bboxes[:, 2] *= mw / iw
downsampled_bboxes[:, 3] *= mh / ih
downsampled_bboxes[:, 1] *= mh / ih
masks = crop_mask(masks, downsampled_bboxes) # CHW
if upsample:
masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
return masks.gt_(0.5)
for i, det in enumerate(pred):
masks = process_mask(proto[i], det[:, 6:], det[:, :4], im.shape[2:], upsample=True) # HWC六、答疑
1、分割出来的图像同一类都是一个颜色,这是语义分割吧?
我个人认为这是实例分割,因为即使是同一个颜色,实际上在输出标签的时候会看到,对于同一类的不同个体,实际上会用不同行来表示。
例如:以官方测试图像(bus)为例子,其分割结果示意图可以上翻,其分割输出标签文件为:

可以看出,类别0为人类,类别5为汽车,虽然人类有重叠部分但是仍然分为了不同的人。
另一张图(zidane)的结果应该更有说服力:

2、为什么分割出来的结果只占实际图像的一部分?
因为在分割过程中,有个crop的环节,就是只保留检测框内部的分割结果。这个检测框的大小是根据anchor的设置大小来决定的,如果我记得没错,应该是设置大小的0.25-4倍,如果图像大小超过检测框的大小,那么就无法完整分割。
这个时候有两种解决方式:
1、调整img-size,默认是640,可以调小。保持anchor的大小不变时,img-size越大,实际分割出来的部分越小。
2、调整anchor大小,理论上应该能自动调整,但是我目前使用的数据集还没有自动调整过。自己手动计算anchor我记得是用kmeans来着,yolov5里面有计算的代码,想不起来再哪里了,以后用到的时候我再更新这段。
3、在检测中,相同设置下,detect与val生成图像中,检测框数量不同。
我测试了一下,在经过nms后,两者的输出是相同的,例如在conf=0.7,iou=0.4的情况下,pred[0].shape=torch.Size([3, 6]),这意味着有三个检测框,各自图片也是这么显示的。但是,当conf=0.001时,val生成166个检测框,detect生成253个检测框,并且,图像显示中,detect显示了全部检测框,而val只显示了三个。
经过排查找到了原因,val与detect绘制检测框的代码不是同一个,val使用的/yolov5-master/utils/plots.py中的def plot_images(images, targets, paths=None, fname='images.jpg', names=None):,其中,在最后的部分,使用了一个固定的数值:

相当于又做了半次的nms。


















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









