






问题:当我们标注完成新的类别后后直接删除classes.txt中不需要的类别之后再次打开labelimg会闪退,如何删除不需要的标签并且能够正确运行呢?(yolo格式)
原因:当我们打开labelimg进行标注的时候,自动生成的classes.txt文件会包含一些预设存在的类别,例如,刚安装时,生成的文件内容就是labelImg-master/data/predefined_classes.txt文件 + 你所标注的标签,此时标注生成的txt文件每一行的第一个位置就是类别的序号,因为你删除了部分标签,导致重新打开labelimg的时候读取出错了故导致闪退。具体过程如下:
-
安装时自带的文件内容:
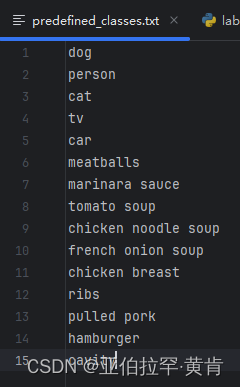
-
添加例如类别other后生成的classes.txt文件就为:
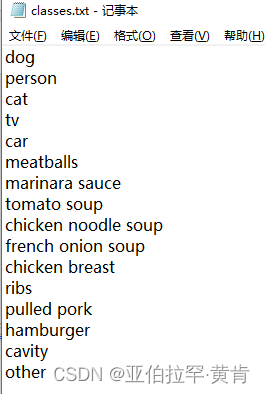
-
标注后生成的内容:

解决办法:可以看到此时的标注文件第一行的类别为15,因为我们标注时的classes.txt文件为十六个标签,而’other’标签的所在序列下标就是15,这就是报错内容所在。由此我们可以知道只需要在删除classess.txt中不需要的标签以外,再将所有txt文件的每一行表示标签的位置改成classes.txt序列的下表即可。例如我只需要other标签,那么我就将classes.txt中删除掉除other以外的标签,并且将所有生成的yolo格式的标注文件txt的每一行标签的位置改为0即可,故可以用以下的代码进行实现:
import os
def modify_labels(folder_path):
# 获取labels文件夹中所有的txt文件
txt_files = [file for file in os.listdir(folder_path) if file.endswith('.txt')]
#逐个遍历
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
lines = f.readlines()
# 将类别15替换为类别9
new_lines = [modify_line(line) for line in lines]
# 覆盖原来的txt文件内容
with open(os.path.join(folder_path, txt_file), 'w') as f:
f.writelines(new_lines)
def modify_line(line):
#只需要改变标签所在位置
class_id, *values = line.split()
if class_id == '15':
class_id = '0'
new_line = class_id + " " + " ".join(values) + "\n"
return new_line
if __name__ == "__main__":
label_file = "label_file"#写你存放label的位置
modify_labels(label_file)
labelimg的下载与使用
可以直接到github上下载
- 下载完成后用编译软件(pycharm)打开其中的labelimg.py即可
注:若缺失库则需要在此环境下进行pip安装即可。 - 运行后的界面如下,选择好文件位置即可进行标注。

- 若要改变某一类别拉框的颜色,例如第一个类别,则到
labelImg-master/libs/utils.py文件中的generate_color_by_text函数中进行修改: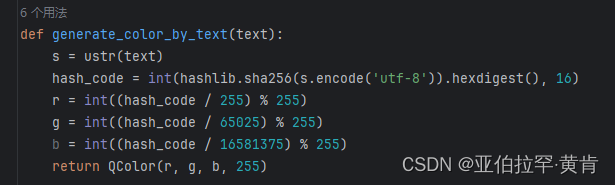
















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









