







1.输入部分
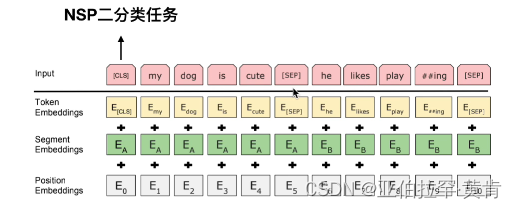
Input = token emb + segment emb + position emb
Embedding:将离散变量转变为连续向量
表示类别变量的理想解决方案则是我们是否可以通过较少的维度表示出每个类别,并且还可以一定的表现出不同类别变量之间的关系,这也就是 embedding 出现的目的。
CLS向量不能代表整个句子的语义信息
2.预训练 MLM和NSP
MLM
- AR 自回归模型;只能考虑单侧的信息,例如GPT
- AE:自编码模型;从损坏的输入数据中构建原始数据,可以使用上下文的信息,BERT就是使用AE.(完形填空)

MASK的概率:

NSP
NSP样本:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同的文档中随机创建一对段落作为负样本
3.微调Bert
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









