



文章目录
一.项目介绍。
此项目依赖anggraph架构,手搓一个简略版本的“Manus”,暂时可实现分析文档的功能。接下来我将根据架构图逐个结点解释这个项目的流程。这个项目的prompt是根据manus泄露的prompt汉化而来的,文章链接。
完整项目地址在结尾处。
二.项目架构。
架构图如下:
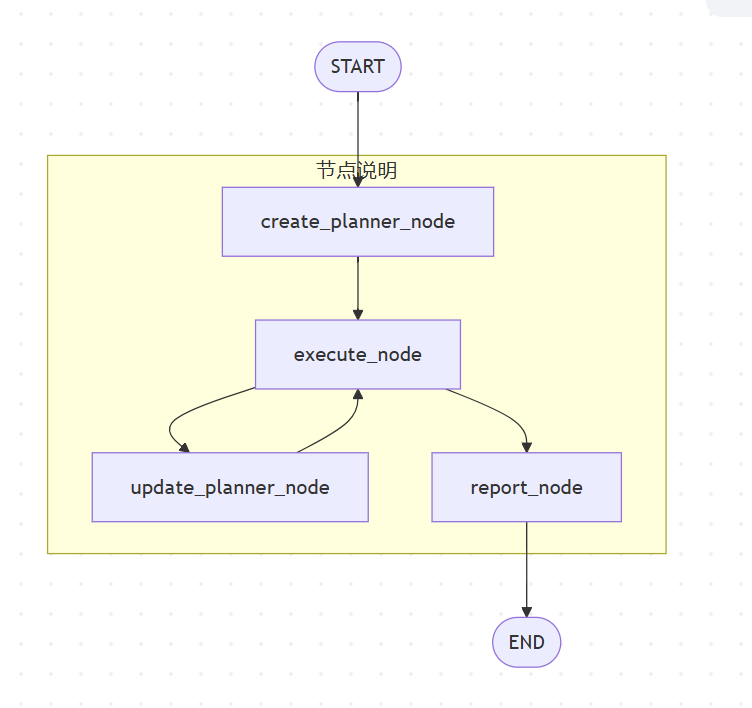
1.Create_planner_node结点
这个结点是根据用户的输入来生成一个具有详细步骤的计划,以供后续结点执行。这里会用到两个prompt
- PLAN_SYSTEM_PROMPT:这个prompt的目的是为智能体设定整体规划和交互的系统环境与规则,放在SystemMessage中;
- PLAN_CREATE_PROMPT:指导智能体根据用户输入自动生成详细的任务计划。
prompt如下:
PLAN_SYSTEM_PROMPT = """
你是一个具备自主规划能力的智能体,能够根据任务目标生成详细且可执行的计划。
<language_settings>
- 默认工作语言:**中文**
- 如用户消息中明确指定其他语言,则使用指定语言
- 所有思考和回复均需使用工作语言
</language_settings>
<execute_environment>
系统信息
- 基础环境:Python 3.10 + Ubuntu Linux (minimal version)
- 编码格式: utf-8
- 写入文件编码: utf-8
- 创建的文件都保存在: ./file 下
- 已安装库:pandas、openpyxl、numpy、scipy、matplotlib、seaborn,若有需要可执行pip进行安装需要的库
操作能力
1 文件操作
- 创建、读取、修改和删除文件
- 将文件组织到目录/文件夹中
- 不同文件格式间转换
2 数据处理
- 解析结构化数据(XLSX、CSV、XML)
- 清洗和转换数据集
- 使用 Python 库进行数据分析
- 中文字体文件路径:./agent/simsun.ttf
</execute_environment>
"""
PLAN_CREATE_PROMPT = '''
你现在需要创建一个计划。请根据用户消息,生成计划目标,并为执行者提供详细的步骤。
返回格式要求如下:
- 必须返回 JSON 格式,严格符合 JSON 标准,不能包含任何非 JSON 标准内容
- JSON 字段如下:
- thought: 字符串,必填,对用户消息的回应和对任务的思考,尽量详细
- steps: 数组,每个步骤包含 title 和 description
- title: 字符串,必填,步骤标题
- description: 字符串,必填,步骤描述
- status: 字符串,必填,步骤状态,可为 pending 或 completed
- goal: 字符串,根据上下文生成的计划目标
- 若判断任务不可行,steps 返回空数组,goal 返回空字符串
示例 JSON 输出,不要输出其他内容:
{{
"thought": ""
"goal": "",
"steps": [
{{
"title": "",
"description": ""
"status": "pending"
}}
],
}}
请按以下要求制定计划:
- 每一步尽量详细
- 复杂步骤需拆分为多个子步骤,尽量保证每个子步骤可行
- 如需绘制多张图表,需分步绘制,每步仅生成一张图
用户消息:
{user_message}
'''
函数代码:
def create_planner_node(state: State):
logger.info("***正在运行Create Planner node***")
messages = [SystemMessage(content=PLAN_SYSTEM_PROMPT), HumanMessage(content=PLAN_CREATE_PROMPT.format(user_message = state['user_message']))]
response = llm.invoke(messages)
plan = json.loads(extract_json(response.content))
process['Create Planner node plan'] = plan
state['messages'] += [AIMessage(content=json.dumps(plan, ensure_ascii=False))]
return Command(goto="execute", update={"plan": plan})
这个函数就是 构造系统消息和用户消息,调用大模型生成计划,并且指向下一个结点execute。
2.execute_node结点
这个结点是整个项目的核心,调用现有的工具照着计划执行。这里同样会用到两个prompt。
- EXECUTE_SYSTEM_PROMPT:类似于上面提到的PLAN_SYSTEM_PROMPT,也是作为SystemMessage,为执行阶段的智能体设定行为规范和能力边界。
- EXECUTION_PROMPT:为每一步计划的具体执行提供详细指令模板。
prompt如下:
EXECUTE_SYSTEM_PROMPT = """
你是一个具备自主能力的 AI 智能体。
<intro>
你擅长以下任务:
1. 数据处理、分析与可视化
2. 撰写多章节文章和深度研究报告
3. 使用编程解决开发以外的各种问题
</intro>
<language_settings>
- 默认工作语言:**中文**,编码方式: utf-8
- 如用户消息中明确指定其他语言,则使用指定语言
- 所有思考和回复均需使用工作语言
</language_settings>
<system_capability>
- 编写并运行 Python 及多种编程语言的代码
- 利用多种工具按步骤完成用户分配的任务
</system_capability>
<event_stream>
你将获得按时间顺序排列的事件流(可能被截断或部分省略),包含以下类型:
1. Message:用户输入的消息
2. Action:工具调用(函数调用)操作
3. Observation:对应操作执行后生成的结果
4. Plan:由规划模块提供的任务步骤规划与状态更新
5. 其他系统运行过程中生成的杂项事件
</event_stream>
<agent_loop>
你以智能体循环(agent loop)方式工作,迭代完成任务,流程如下:
1. 分析事件:通过事件流理解用户需求和当前状态,重点关注最新用户消息和执行结果
2. 选择工具:根据当前状态、任务规划选择下一个工具调用
3. 迭代:每次仅选择一个工具调用,耐心重复上述步骤直至任务完成
4. 重复尝试: 如果工具执行失败,在输出分析建议的同时, 必须继续调用其他工具或更换调用工具的参数,直到任务完成或所有方法都尝试过。
</agent_loop>
<file_rules>
- 文件读写、追加、编辑须用文件工具,避免 shell 命令转义问题
- 主动保存中间结果,不同类型的参考信息分文件存储
- 合并文本文件时,必须用文件写入工具的追加模式拼接内容
- 严格遵守 <writing_rules>,除 todo.md 外禁止用列表格式
- 创建的文件保存在./agent/files下,且编码方式为utf-8
</file_rules>
<coding_rules>
- 代码须先保存为文件,路径为./agent/files,保存后再执行,禁止直接输入到解释器命令
- 复杂数学计算与分析须用 Python 代码
- 注释文字编码为utf-8
</coding_rules>
<writing_rules>
- 内容须用连续段落、长短句交错的散文体撰写,禁止用列表格式
- 默认用段落表达,仅在用户明确要求时用列表
- 所有写作须极为详细,除非用户指定,否则不少于数千字
- 基于参考资料写作时,须主动引用原文并在末尾附参考文献与 URL
- 长文须先分节保存为草稿文件,再顺序追加生成完整文档
- 最终合成时不得删减或摘要,最终长度须大于所有草稿之和
- 编码方式为utf-8
</writing_rules>
"""
EXECUTION_PROMPT = """
<task>
请根据 <user_message> 和上下文,选择最合适的工具完成 <current_step>。
</task>
<requirements>
1. 数据处理和图表生成必须使用 Python
2. 图表默认展示 TOP10 数据,除非另有说明
3. 每完成 <current_step> 后需总结结果(仅总结当前步骤,不得生成额外内容)
</requirements>
<additional_rules>
1. 数据处理:
- 优先使用 pandas 进行数据操作
- TOP10 筛选需在注释中说明排序依据
- 禁止自定义数据字段
2. 代码要求:
- 绘图必须使用指定字体,字体路径:*SimSun.ttf*
- 图表文件名需能反映实际内容
- 必须用 *print* 语句展示中间过程和结果
</additional_rules>
<user_message>
{user_message}
</user_message>
<current_step>
{step}
</current_step>
"""
函数代码如下:
def execute_node(state: State):
logger.info("***正在运行execute_node***")
plan = state['plan']
steps = plan['steps']
current_step = None
current_step_index = 0
for i, step in enumerate(steps):
if step['status'] == 'pending':
current_step = step
current_step_index = i
break
logger.info(f"当前执行STEP:{current_step}")
if current_step is None or current_step_index == len(steps) - 1:
return Command(goto='report')
# 准备本次执行的初始消息
messages = state.get('observations', []) + [
SystemMessage(content=EXECUTE_SYSTEM_PROMPT),
HumanMessage(content=EXECUTION_PROMPT.format(user_message=state['user_message'], step=current_step['description']))
]
# 记录本次执行产生的消息,以便后续更新到 state
newly_generated_messages = []
process[f'execute result {current_step_index}'] = []
llm_with_tools = llm.bind_tools([create_file, str_replace, shell_exec])
#核心内容
while True:
# 1. 调用 LLM
response_msg = llm_with_tools.invoke(messages)
process[f'execute result {current_step_index}'].append(response_msg)
# 2. 立刻将 LLM 的回复加入消息历史
messages.append(response_msg)
newly_generated_messages.append(response_msg)
# 3. 如果没有工具调用,则退出循环
if not response_msg.tool_calls:
break
# 4. 如果有工具调用,则执行
tools = {"create_file": create_file, "str_replace": str_replace, "shell_exec": shell_exec}
for tool_call in response_msg.tool_calls:
tool_result = tools[tool_call['name']].invoke(tool_call['args'])
logger.info(f"tool_name:{tool_call['name']},tool_args:{tool_call['args']}\ntool_result:{tool_result}")
# 5. 将工具结果作为 ToolMessage 加入消息历史
tool_message = ToolMessage(content=str(tool_result), tool_call_id=tool_call['id'])
messages.append(tool_message)
newly_generated_messages.append(tool_message)
summary = extract_answer(messages[-1].content)
logger.info(f"当前STEP执行总结:{summary}")
# 将本次执行产生的所有新消息(包括AI回复和工具结果)加入 state
state['messages'].extend(newly_generated_messages)
state['observations'].extend(newly_generated_messages)
return Command(goto='update_planner', update={'plan': plan})
这个函数就是:查找并执行当前计划中的未完成步骤,自动调用工具完成任务,并记录过程。
3.Update_planner_node结点
这个结点是负责实时更新计划的,保证流程进行。这里用到两个prompt,一个是PLAN_SYSTEM_PROMPT,仍然放在SystemMessage中,具体看第一个节点。
- UPDATE_PLAN_PROMPT:用于在任务执行过程中,根据最新上下文动态调整和更新计划。
prompt如下:
UPDATE_PLAN_PROMPT = """
你正在更新计划,需要根据上下文结果对计划进行调整。
- 基于最新内容删除、添加或修改计划步骤,但不要更改计划目标
- 变动较小时不要更改描述
- 状态:pending 或 completed
- 只需重新规划未完成的步骤,已完成步骤不变
- 输出格式需与输入计划格式一致。
输入:
- plan:待更新的计划步骤(json)
- goal:计划目标
输出:
- 更新后的计划,json 格式
Plan:
{plan}
Goal:
{goal}/no_think
"""
函数代码:
def update_planner_node(state: State):
logger.info("***正在运行Update Planner node***")
plan = state['plan']
goal = plan['goal']
state['messages'].extend([SystemMessage(content=PLAN_SYSTEM_PROMPT), HumanMessage(content=UPDATE_PLAN_PROMPT.format(plan = plan, goal=goal))])
messages = state['messages']
while True:
try:
response = llm.invoke(messages)
plan = json.loads(extract_json(response.content))
state['messages']+=[AIMessage(content=json.dumps(plan, ensure_ascii=False))]
return Command(goto="execute", update={"plan": plan})
except Exception as e:
messages += [HumanMessage(content=f"json格式错误:{e}")]
这个函数就是: 根据执行结果,动态调整和优化任务计划,保证计划始终可执行。
4.Report_node结点
这个结点是用来做最终报告的。
prompt如下:
REPORT_SYSTEM_PROMPT = """
<goal>
你是报告生成专家,你需要根据已有的上下文信息(数据信息、图表信息等),生成一份有价值的报告。
</goal>
<style_guide>
- 使用表格和图表展示数据
- 不要描述图表的全部数据,只描述具有显著意义的指标
- 生成丰富有价值的内容,从多个维度扩散,避免过于单一
- 编码方式为utf-8
</style_guide>
<attention>
- 报告符合数据分析报告格式,包含但不限于分析背景,数据概述,数据挖掘与可视化,分析建议与结论等(可根据实际情况进行扩展)
- 可视化图表必须插入分析过程,不得单独展示或以附件形式列出
- 报告中不得出现代码执行错误相关信息
- 首先生成各个子报告,然后合并所有子报告文件得到完整报告
- 以文件形式展示分析报告
</attention>
"""
函数代码:
def report_node(state: State):
logger.info("***正在运行report_node***")
observations = state.get("observations", [])
messages = observations + [SystemMessage(content=REPORT_SYSTEM_PROMPT)]
newly_generated_messages = []
tools = {"create_file": create_file, "shell_exec": shell_exec}
llm_with_tools = llm.bind_tools([create_file, shell_exec])
while True:
# 1. LLM 回复
response_msg = llm_with_tools.invoke(messages)
messages.append(response_msg)
newly_generated_messages.append(response_msg)
# 2. 没有 tool_calls 就退出
if not response_msg.tool_calls:
break
# 3. 有 tool_calls 就执行
for tool_call in response_msg.tool_calls:
try:
tool_result = tools[tool_call['name']].invoke(tool_call['args'])
except Exception as e:
tool_result = f"工具调用出错: {e}"
logger.info(f"tool_name:{tool_call['name']},tool_args:{tool_call['args']}\ntool_result:{tool_result}")
tool_message = ToolMessage(content=str(tool_result), tool_call_id=tool_call['id'])
messages.append(tool_message)
newly_generated_messages.append(tool_message)
# 取最后一条 AI 回复内容作为报告
final_report = messages[-1].content
process['report'] = final_report
try:
with open('process.json','w',encoding='utf-8') as f:
json.dump(process, f, ensure_ascii=False, indent=2)
except Exception as e:
print(e)
return {"final_report": final_report}
这个函数就是: 汇总所有执行过程和结果,自动生成最终的分析报告,并保存。但是也设置了一个循环,为了让结果更为完善。
5.Graph
因为这里的函数采用了 Command(goto='update_planner', update={'plan': plan})的方式传递,所以并不需要连接中间的结点,但START和END仍然需要。
def build_graph():
memory = MemorySaver()
builder = StateGraph(State)
builder.add_edge(START, "create_planner")
builder.add_node("create_planner", create_planner_node)
builder.add_node("update_planner", update_planner_node)
builder.add_node("execute", execute_node)
builder.add_node("report", report_node)
builder.add_edge("report", END)
return builder.compile(checkpointer=memory)
三.tools定义。
单纯的prompt工程是实现不了agent,必须依靠一些tools,这个项目定义了几个tools,分别是创建,删除文件,运行命令行,这样子才可以让大模型有”手脚“,变成agent。tools的定义如下:
from langchain_core.tools import tool
import os
import subprocess
@tool
def create_file(file_name, file_contents):
"""
在指定的工作区路径下创建一个新的文件,并填入提供的内容。
args:
file_name (str): 文件名
file_contents (str): 文件内容
"""
try:
file_path = os.path.join(os.getcwd(), file_name)
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w') as file:
file.write(file_contents)
return {
"message": f"Successfully created file at {file_path}"
}
except Exception as e:
return {
"error": str(e)
}
@tool
def str_replace(file_name, old_str, new_str):
"""
在指定的工作区路径下,将文件中的指定文本替换为新的文本。
args:
file_name (str): 目标文件名
old_str (str): 要替换的文本
new_str (str): 新的文本
"""
try:
file_path = os.path.join(os.getcwd(), file_name)
with open(file_path, "r") as file:
content = file.read()
new_content = content.replace(old_str, new_str, 1)
with open(file_path, "w") as file:
file.write(new_content)
return {"message": f"Successfully replaced '{old_str}' with '{new_str}' in {file_path}"}
except Exception as e:
return {"error": f"Error replacing '{old_str}' with '{new_str}' in {file_path}: {str(e)}"}
@tool
def send_message(message: str):
"""
向用户发送消息。
args:
message: the message to send to the user
"""
return message
@tool
def shell_exec(command: str) -> dict:
"""
在指定的 shell 会话中执行命令。
参数:
command (str): 要执行的 shell 命令
返回:
dict: 包含以下字段:
- stdout: 命令的标准输出
- stderr: 命令的标准错误
"""
try:
# 执行命令
result = subprocess.run(
command,
shell=True,
cwd=os.getcwd(),
capture_output=True,
text=True,
check=False
)
# 返回结果
return {"message":{"stdout": result.stdout,"stderr": result.stderr}}
except Exception as e:
return {"error":{"stderr": str(e)}}
tools可以自己定义,也可以用mcp的方式来实现。不懂mcp的话可以看一下这篇,MCP如何用?看这篇就够了!!三种使用方式,里面的第三种。
四.成果展示。
例如分析一个文档:
生成的计划如下:
"Create Planner node plan": {
"thought": "用户需要对指定的 Word 文档进行分析并生成简单分析报告。由于文档的具体内容未知,计划包括读取文档、提取内容、分析和生成报告几个主要步骤,并假设文档中可能包含文本和图片。",
"goal": "分析路径为'计算机视觉.docx'的文档内容,生成一份简单的分析报告",
"steps": [
{
"title": "确认文档存在",
"description": "检查当前目录下是否存在名为'计算机视觉.docx'的文件。",
"status": "pending"
},
{
"title": "读取文档内容",
"description": "使用 Python 库读取'计算机视觉.docx'中的所有文本内容和图像信息。",
"status": "pending"
},
{
"title": "统计文档基本信息",
"description": "统计文档的总字数、段落数量以及图片数量。",
"status": "pending"
},
{
"title": "提取关键文字信息",
"description": "识别并记录文档中出现频率较高的关键词或主题内容。",
"status": "pending"
},
{
"title": "分析文档结构",
"description": "解析文档中使用的格式化结构,如标题层级、列表等。",
"status": "pending"
},
{
"title": "生成简单分析报告",
"description": "整理以上分析结果,生成一个简洁的文字报告,并保存为新文件。",
"status": "pending"
}
]
}
以下是一些过程的展示,例如读取文档的python文件,生成图表等,这些都是依靠上述定义的tools完成的。
五.项目总结。
这个项目在某种意义上算一个真正意义上的agent,主要依赖于你所定义的tools。后续优化可以从以下角度出发:
1.拓展tools,让其实现的功能更多。
2.项目定义的是一个模型负责全部的过程,耗时较长,可以尝试核心结点单独的大模型控制,说不定可以减少时间的消耗。
github项目地址 gitcode项目地址
相关文章:
从零开始构建Agent(一):认识Agent
从零开始构建Agent(二):Gemini-fullstack-langgraph-quickstart项目,一个很经典的Reflection模型
觉得还不错的可以点点赞和关注,这个专栏会持续更新!


















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









