









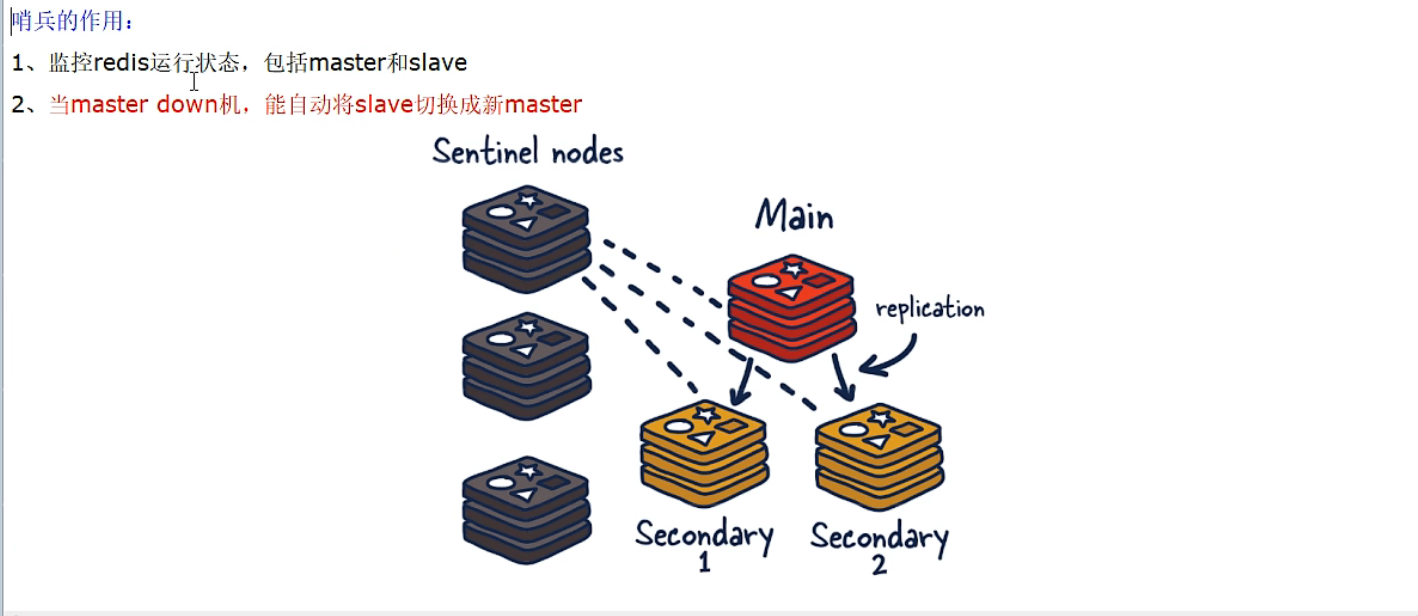
1、是什么
吹哨人巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一格从库转换为新主库,继续对外服务。
作用:俗称无人值守运维。
官网理论:https://redis.io/docs/manual/sentinel/
2、能干嘛
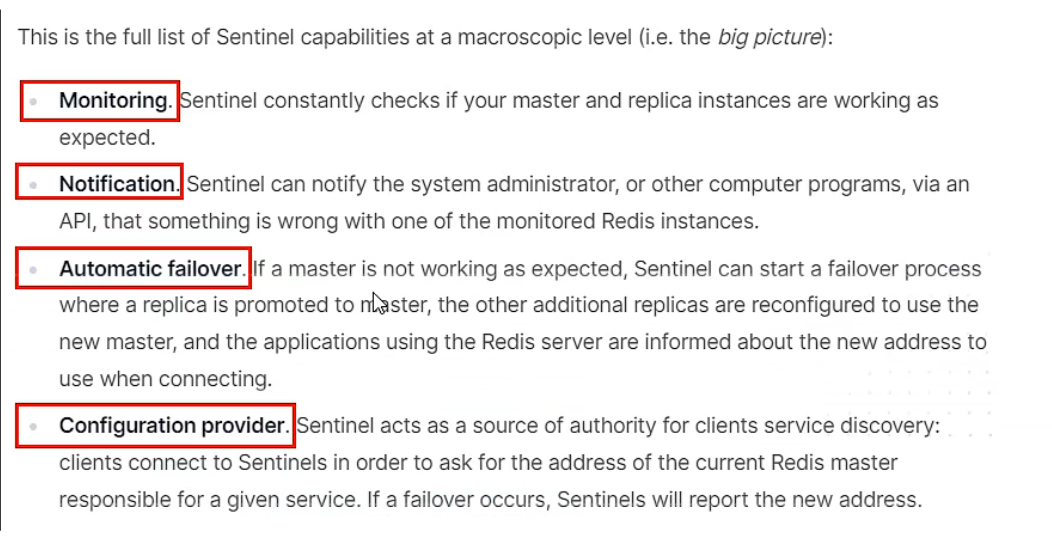
主从监控
- 监控主从redis库运行是否正常
消息通知
- 哨兵可以将故障转移的结果发送给客户端
故障转移
- 如果master异常,则会进行主从切换,将其中一个slave作为新的master
配置中心
- 客户端通过连接哨兵来获得当前redis服务的主节点地址
3、怎么玩(案例演示实战步骤)
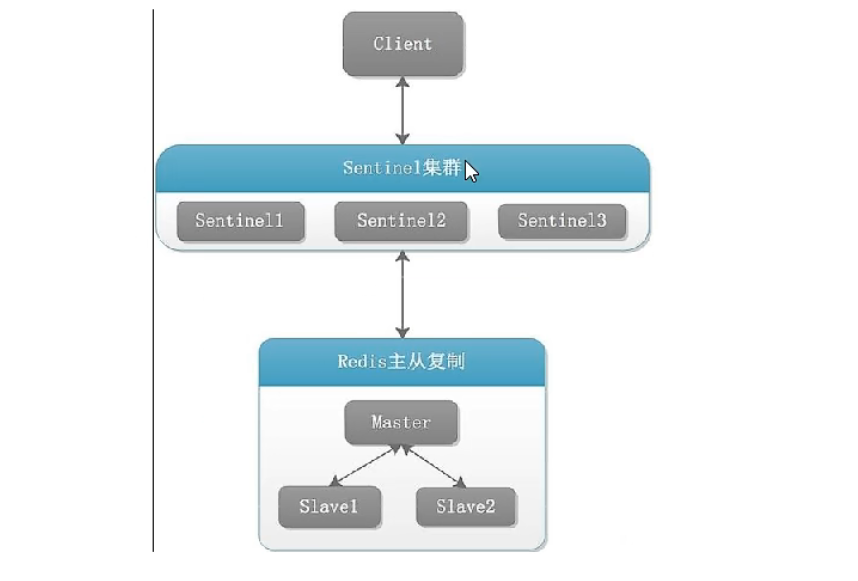
3.1、Redis Sentinel架构,前提说明
- 三个哨兵:自动监控和维护集群,不存放数据,只是吹哨人
- 一主二从:用于数据读取和存放
这里我把三个哨兵都放在同一个虚拟机上了,6379端口号的主机(也就是之前使用的主库虚拟机)。
3.2、案例步骤,不服就干
/myredis目录下新建或者拷贝sentinel.conf文件,名字绝对不能错。
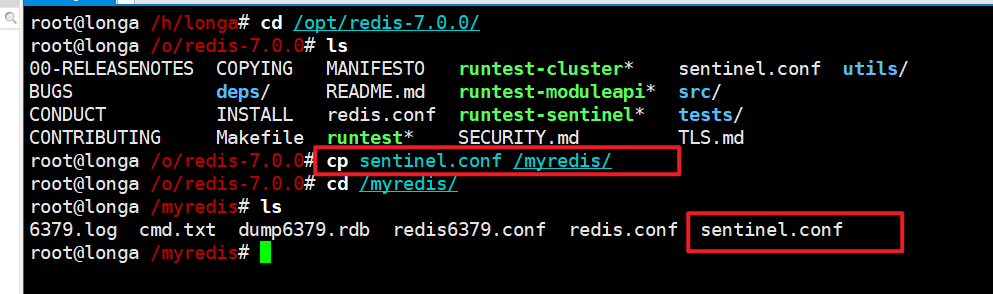
先看看/opt目录下默认的sentinel.conf文件的内容
重点参数项说明
bind:服务器监听地址,用于客户端连接,默认本机地址
daemonize:是否以后台daemon方式运行
protected-mode:安全保护模式
port:端口
logfile:日志文件路径
pidfile:pid文件路径
dir:工作目录
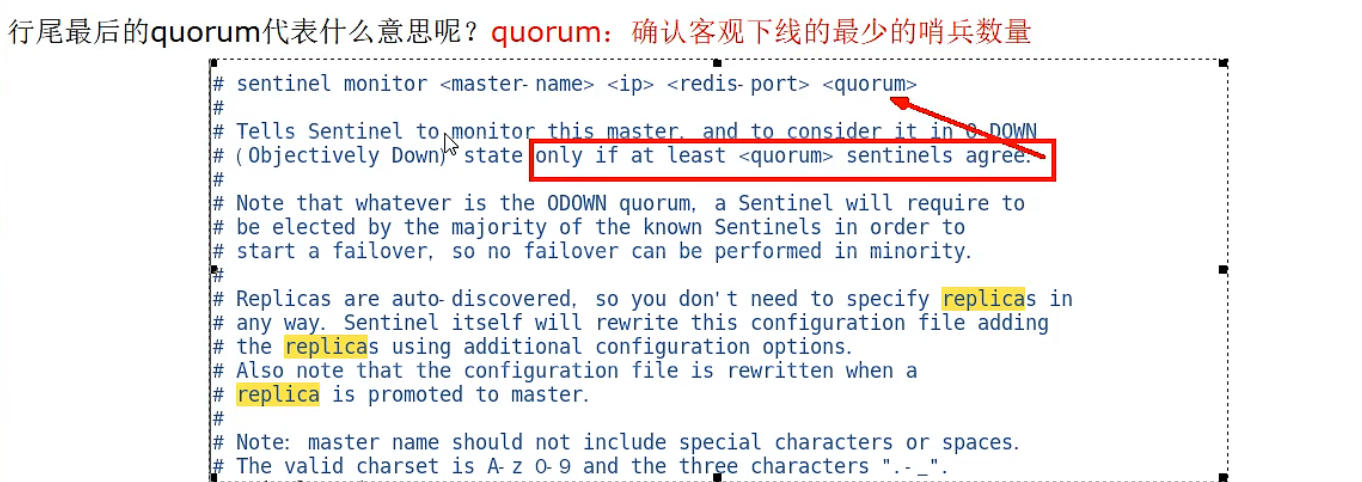
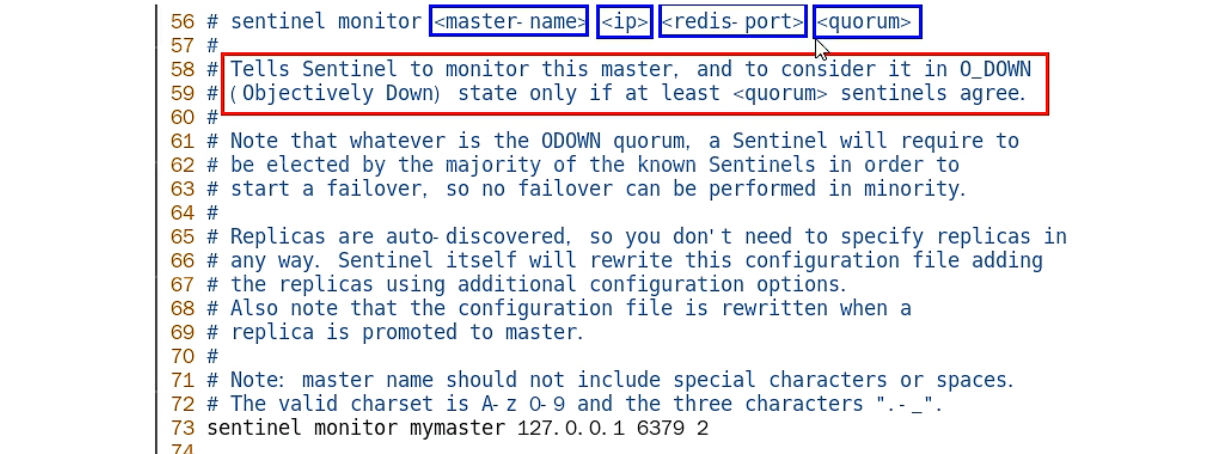
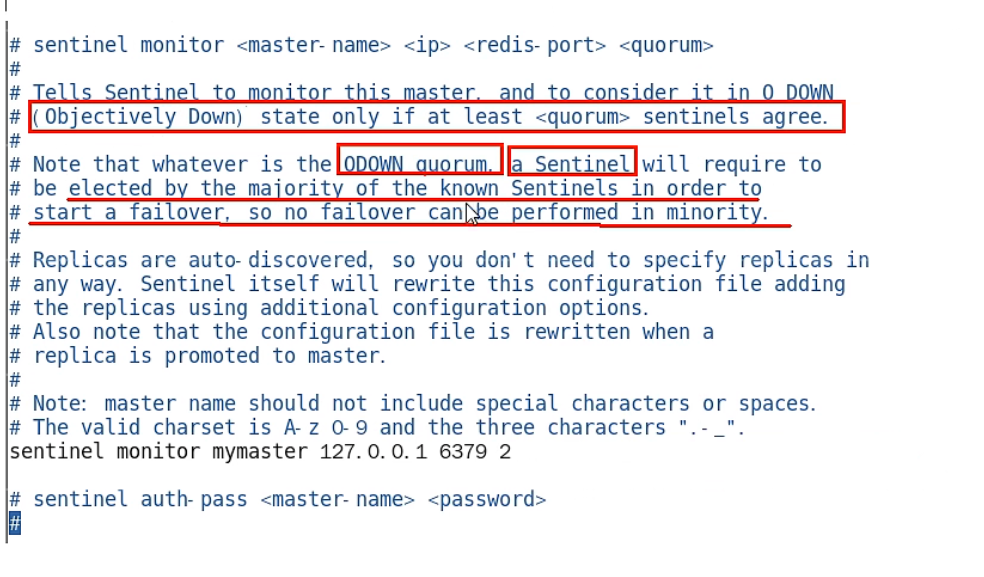
sentinel monitor <master-name> <ip> <redis-port> <quorum>:
- 设置要监控的master服务器
- quorum表示最少有几个哨兵认可客观下线,同一故障迁移的发动票数。

sentinel auth-pass <master-name> <password>:master设置了密码,连接master服务的密码。
其他:

本次案例哨兵sentinel文件通用配置
- 由于机器硬件关系,我们三个哨兵都同时配置进192.168.100.100同一台机器。
- sentinel26379.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/myredis/sentinel26379.log"
pidfile /var/run/redis-sentinel26379.pid
dir /myredis
sentinel monitor mymaster 192.168.100.100 6379 2
sentinel auth-pass mymaster 111111
- sentinel26380.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26380
logfile "/myredis/sentinel26380.log"
pidfile /var/run/redis-sentinel26380.pid
dir /myredis
sentinel monitor mymaster 192.168.100.100 6379 2
sentinel auth-pass mymaster 111111
- sentinel26381.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26381
logfile "/myredis/sentinel26381.log"
pidfile /var/run/redis-sentinel26381.pid
dir /myredis
sentinel monitor mymaster 192.168.100.100 6379 2
sentinel auth-pass mymaster 111111
- 请看一眼sentinel26379.conf/sentinel26380.conf/sentinel26381.conf我们自己填写的内容
- master主机配置文件说明
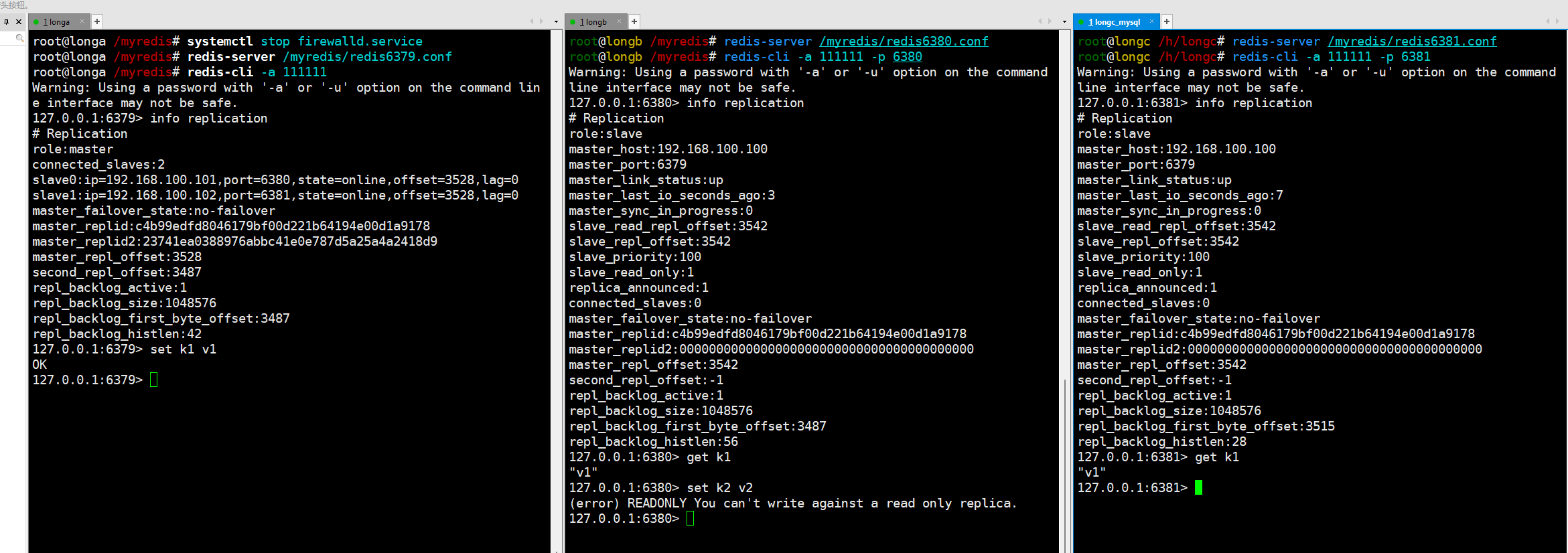
先启动一主二从三个redis实例,测试正常的主从复制
架构介绍:
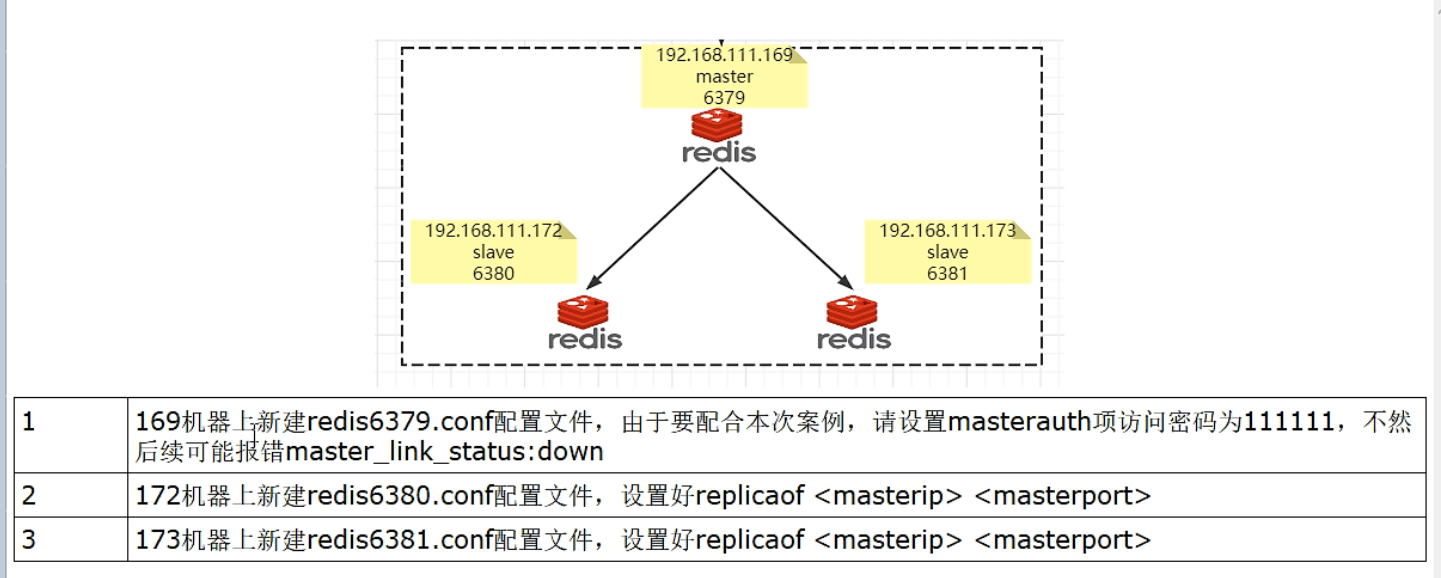
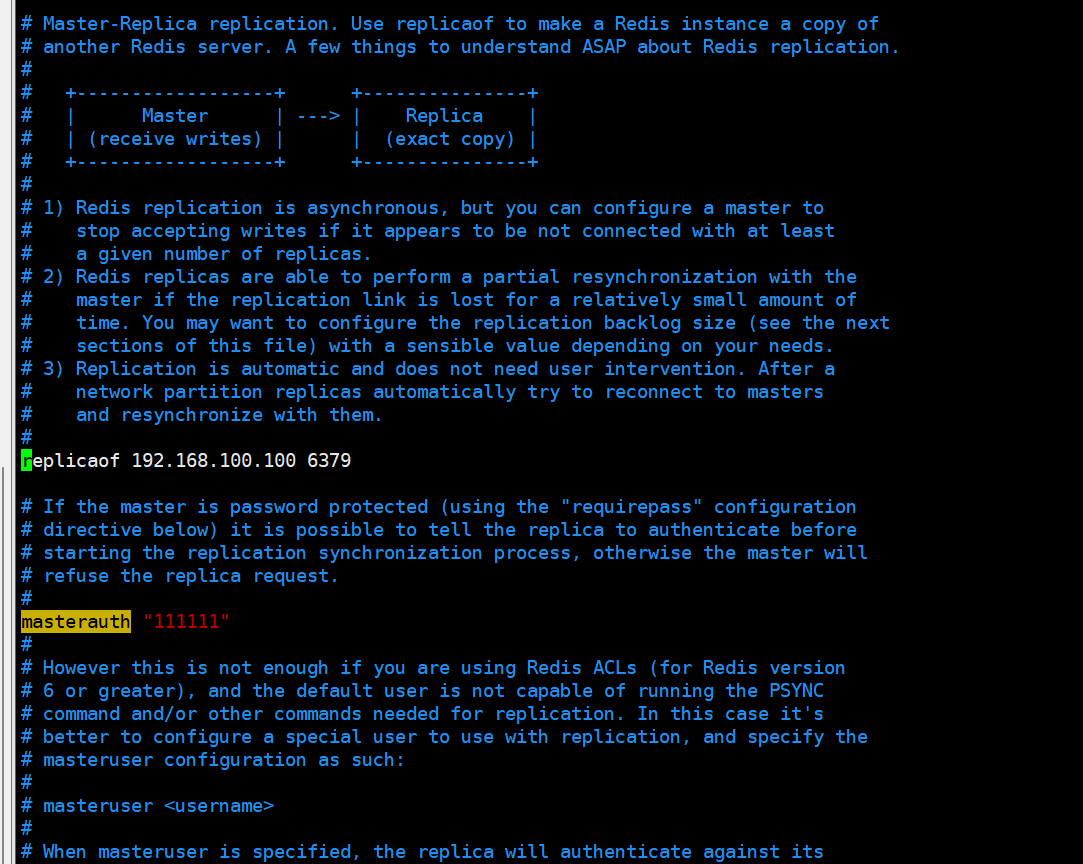
请看一眼redis6379.conf/redis6380.conf/redis6381.conf我们自己填写主从复制相关的内容:
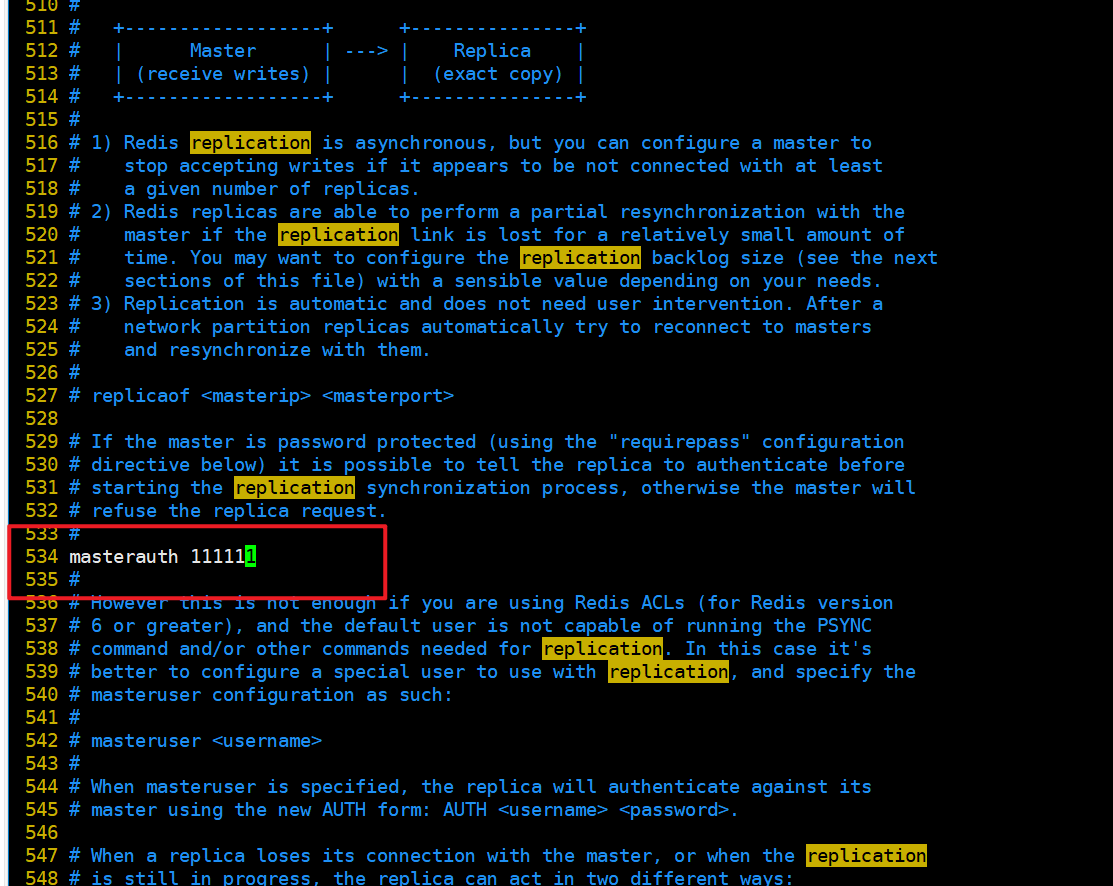
- 主机6379
6379后续可能会变成从机,需要设置访问新主机的密码,请设置masterauth项访问密码为111111.
不然后续可能报错master_link_status:down
- 从机6380
三台不同的虚拟机实例,启动三部真实机器实例并连接:
再启动三个哨兵,完成监控
两种启动方式:
启动:
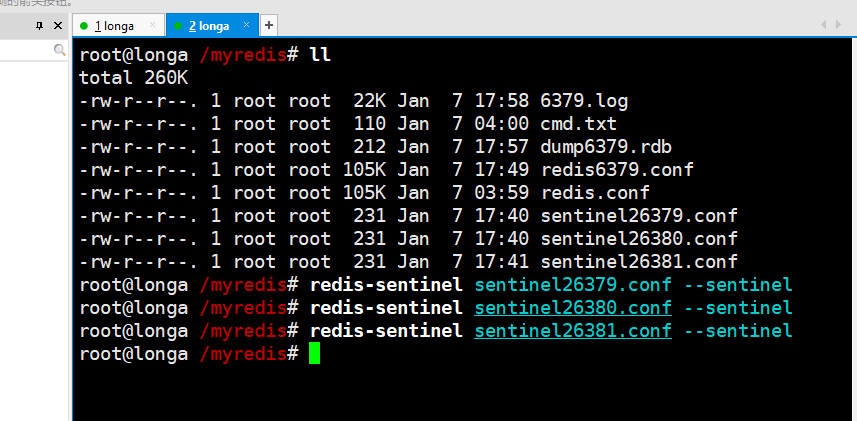
启动三个哨兵监控后再测试一次主从复制-岁月静好一切OK


哨兵启动后的配置文件和日志文件:(以sentinel26379为例)
sentinel26379.log:
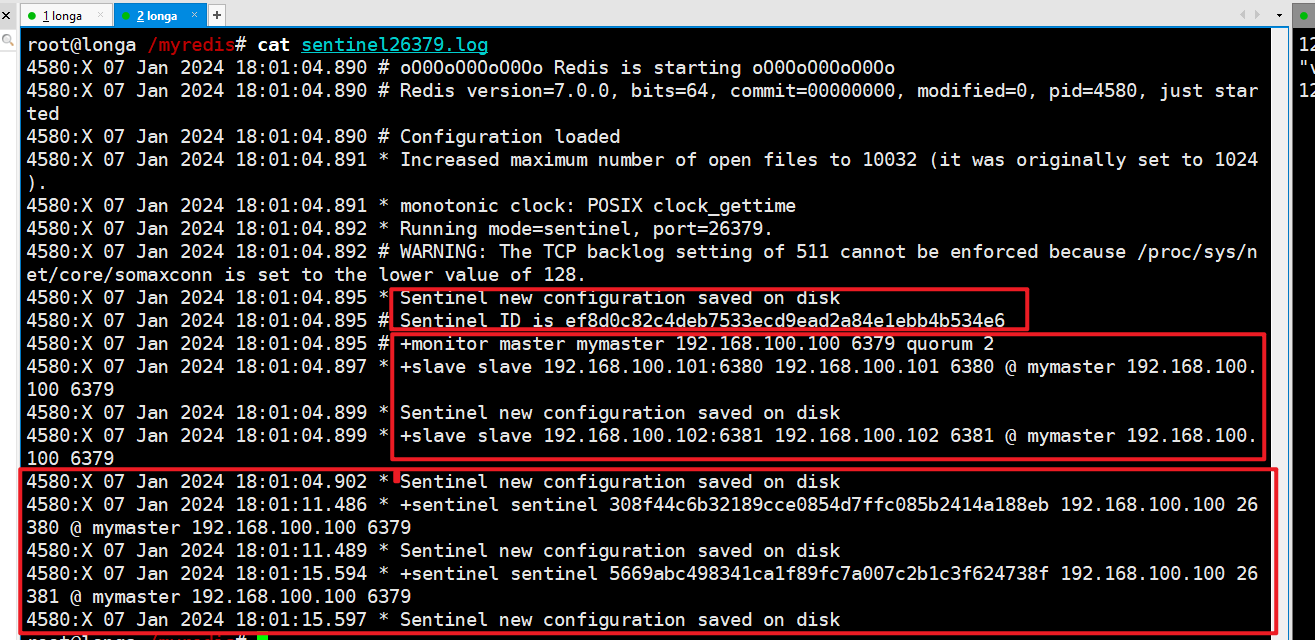
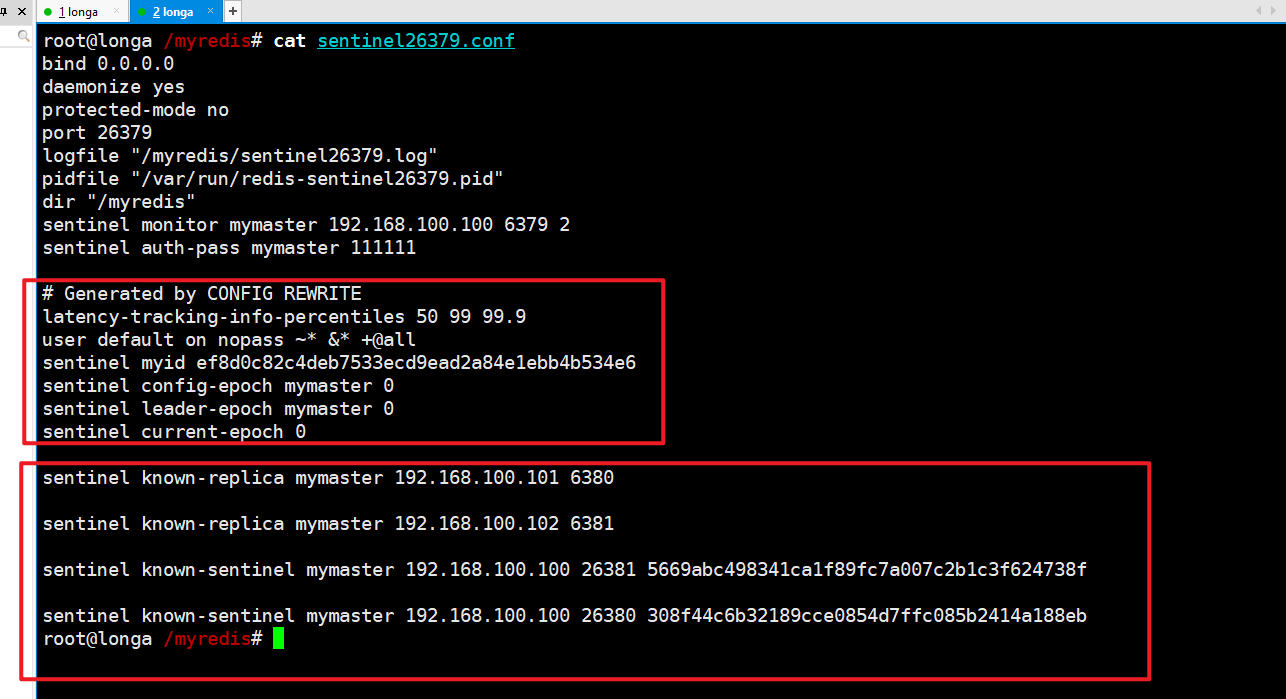
sentinel26379.conf:
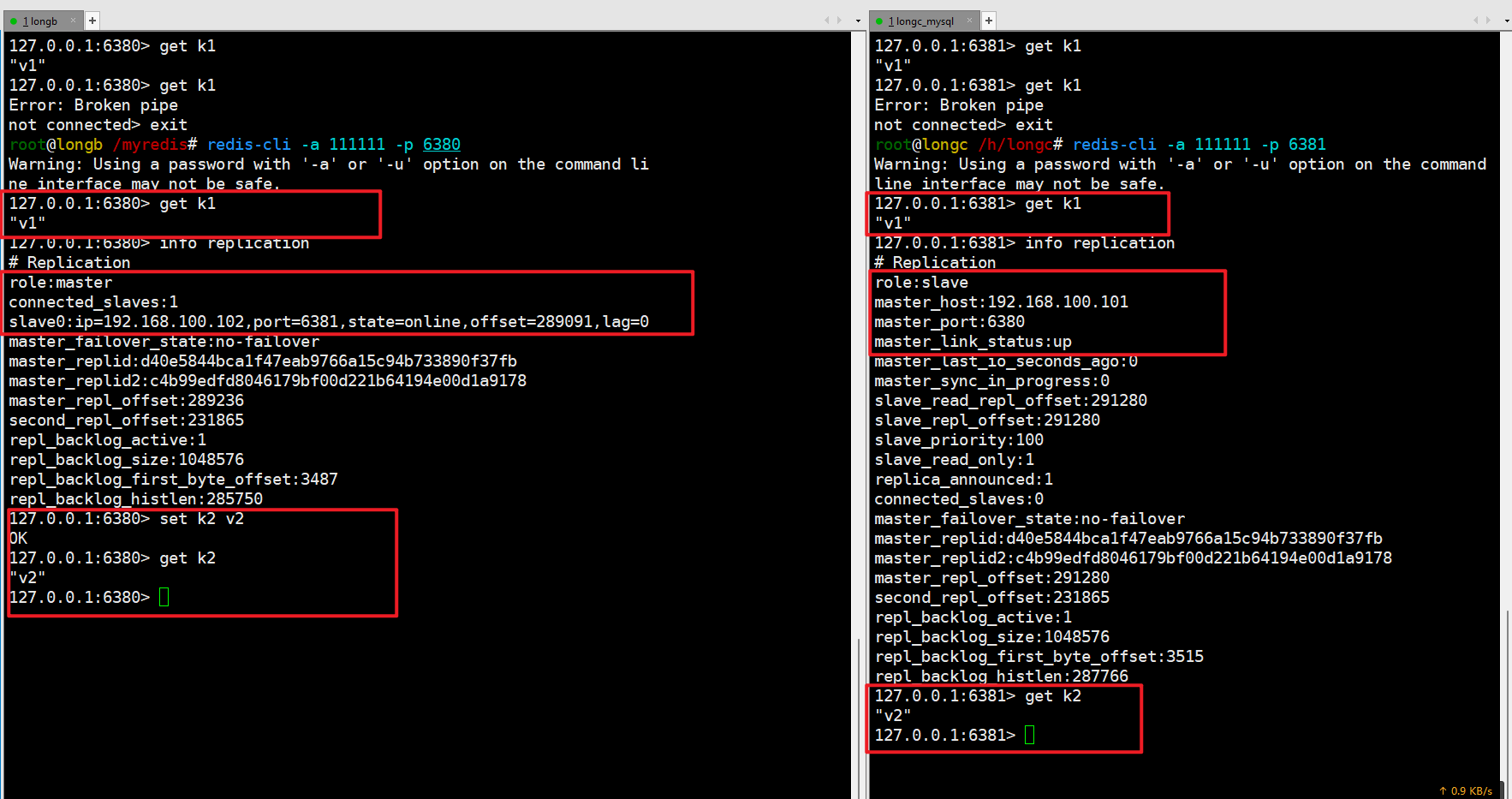
原有的master挂了
- 我们自己手动关闭6379服务器,模拟master挂了。

问题思考:
- 两台从机数据是否OK

- 是否会从省下2台机器上选出新的master
- 之前down机的master机器重启回来,谁将会是新的老大?会不会双master冲突?
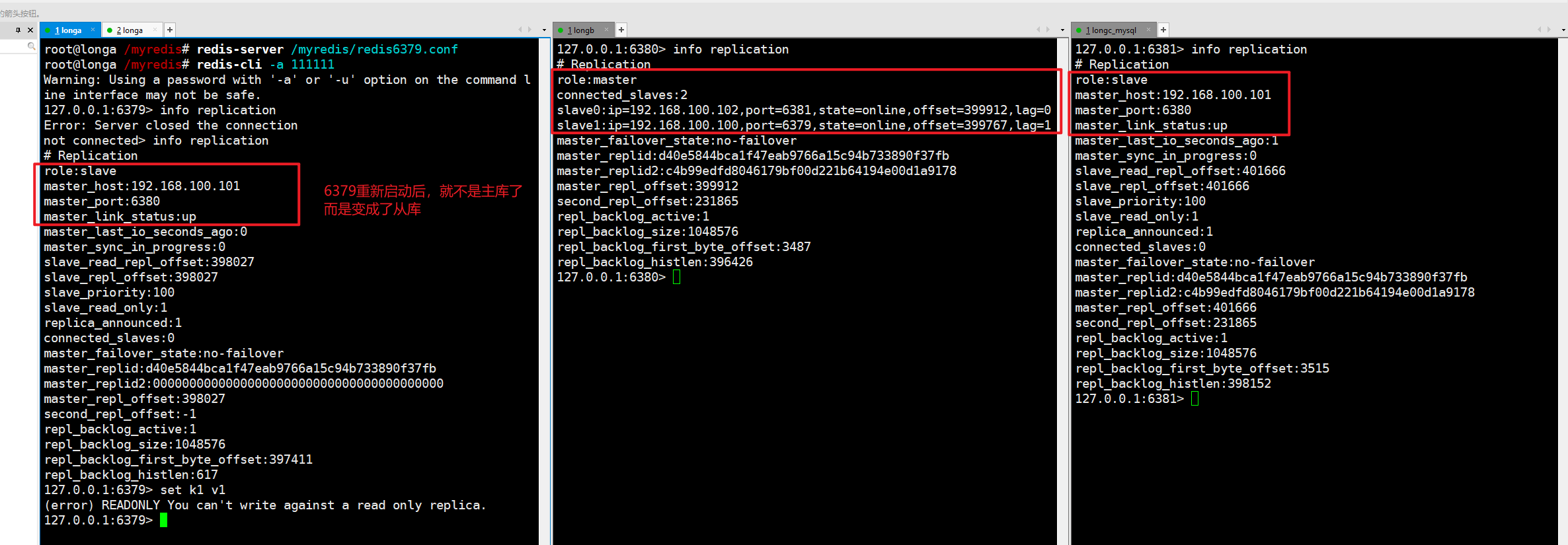
揭晓答案:(其实日志问价写的非常清楚)
- 数据OK
两个小问题:
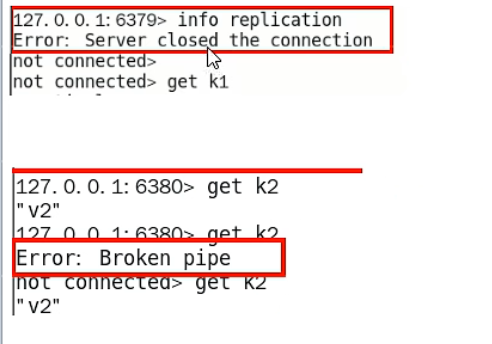
了解broken pipe:

- 投票新选
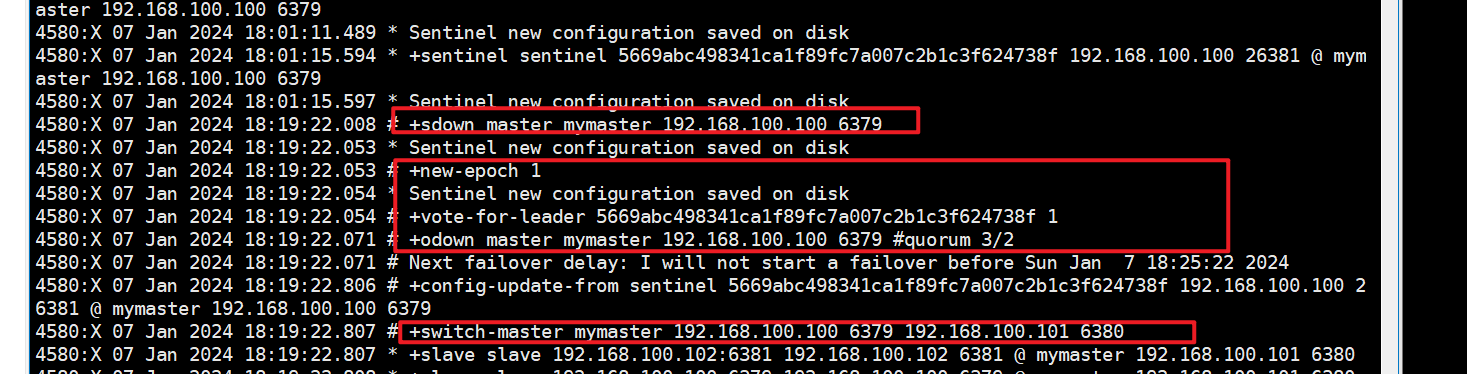
- 谁是master,限本次案例
- 6380被选为新的master,上位成功
- 以前的6379从master降级变成slave
- 6381还是slave,只不过换了个新老大6380(6379变6380),6381还是slave
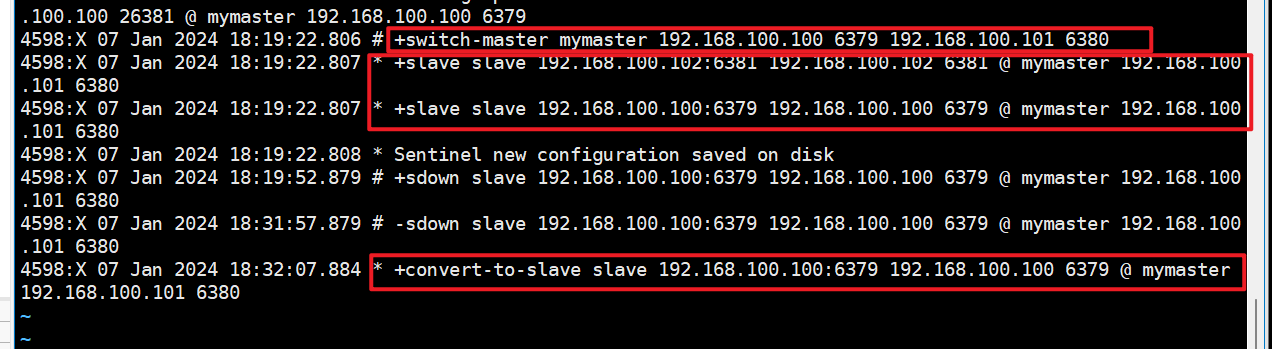
对比配置文件
vim sentinel26379.conf:
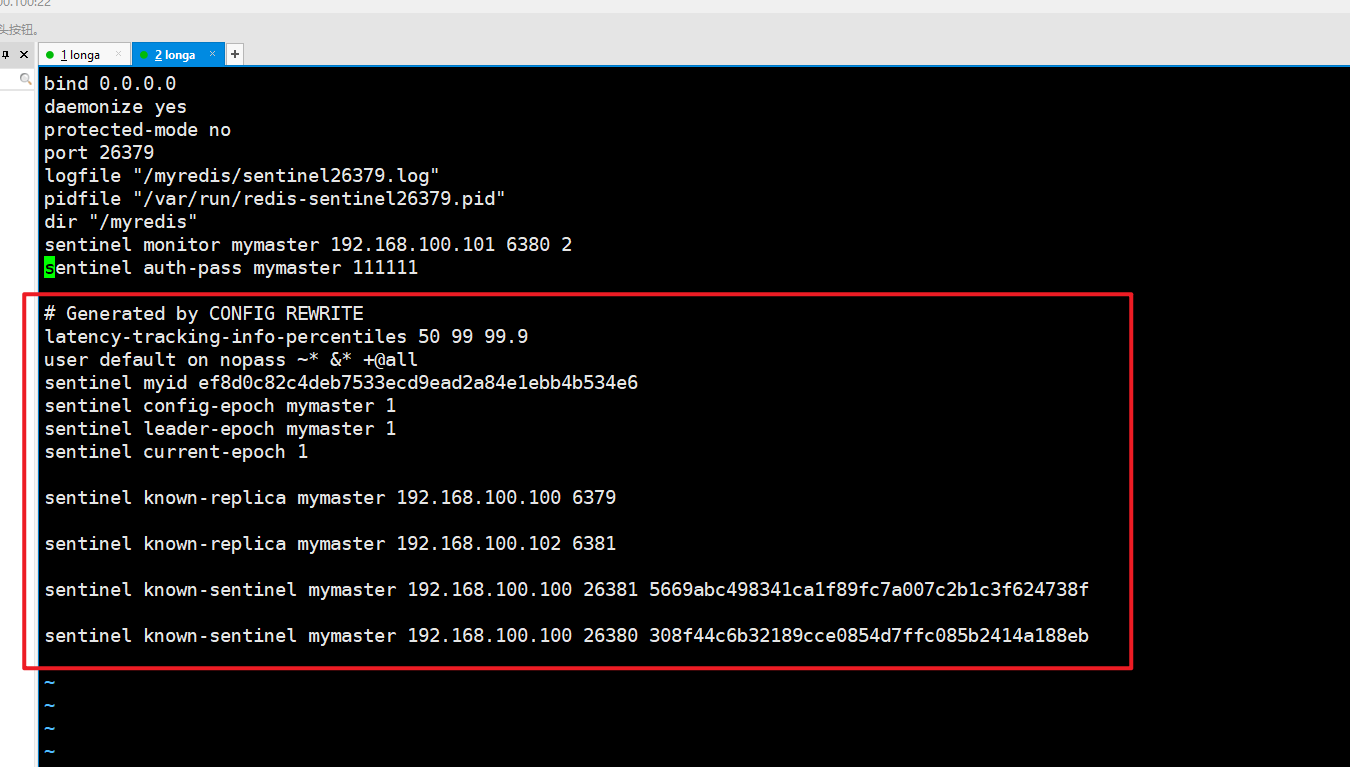
老master,vim redis6379.conf:
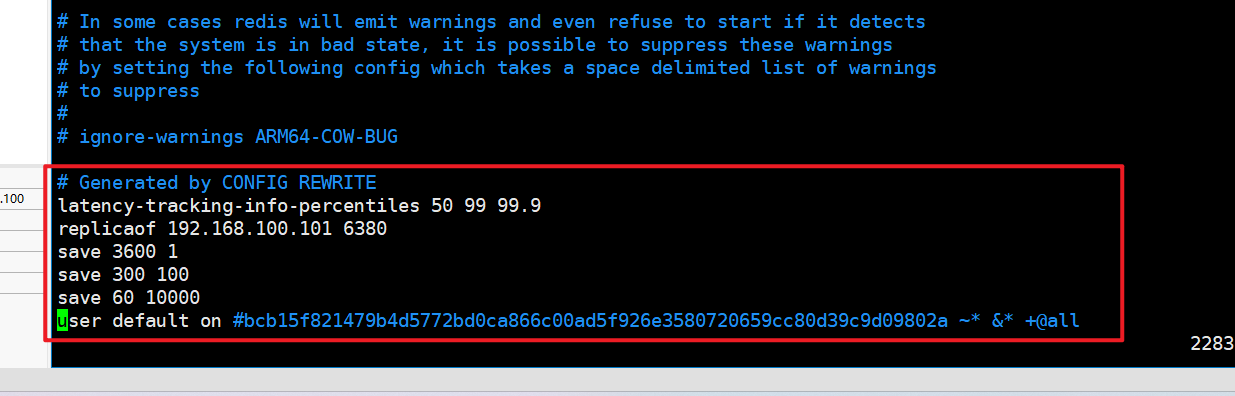
新master,vim redis6381.conf:
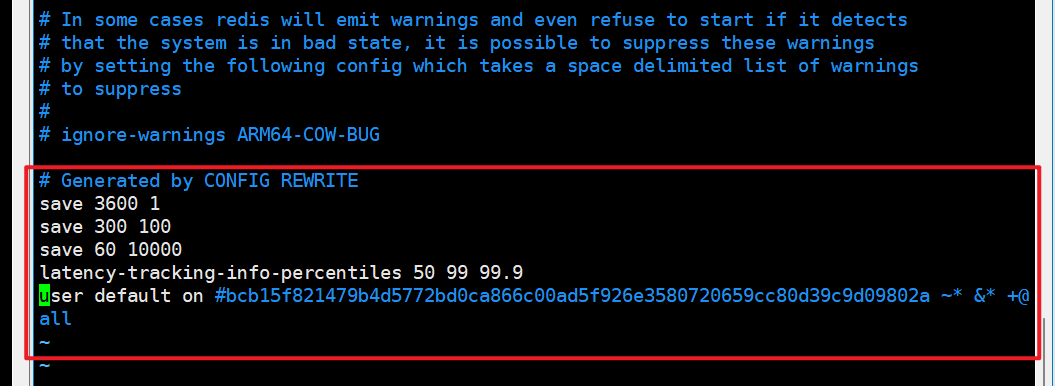
结论:
- 文件的内容,在运行期间会被sentinel动态进行更改。
- Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换
3.3、其他备注
- 生产都是不同机房不同服务器,很少出现3个哨兵全挂掉的情况
- 可以同时监控多个master,一行一个
4、哨兵运行流程和选举原理
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master用于自动替换原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。一般建议sentienl采取奇数台,防止某一台sentinel无法连接到master导致误切换。
4.1、运行流程、故障切换
三个哨兵监控一主二从,正常运行中。。。
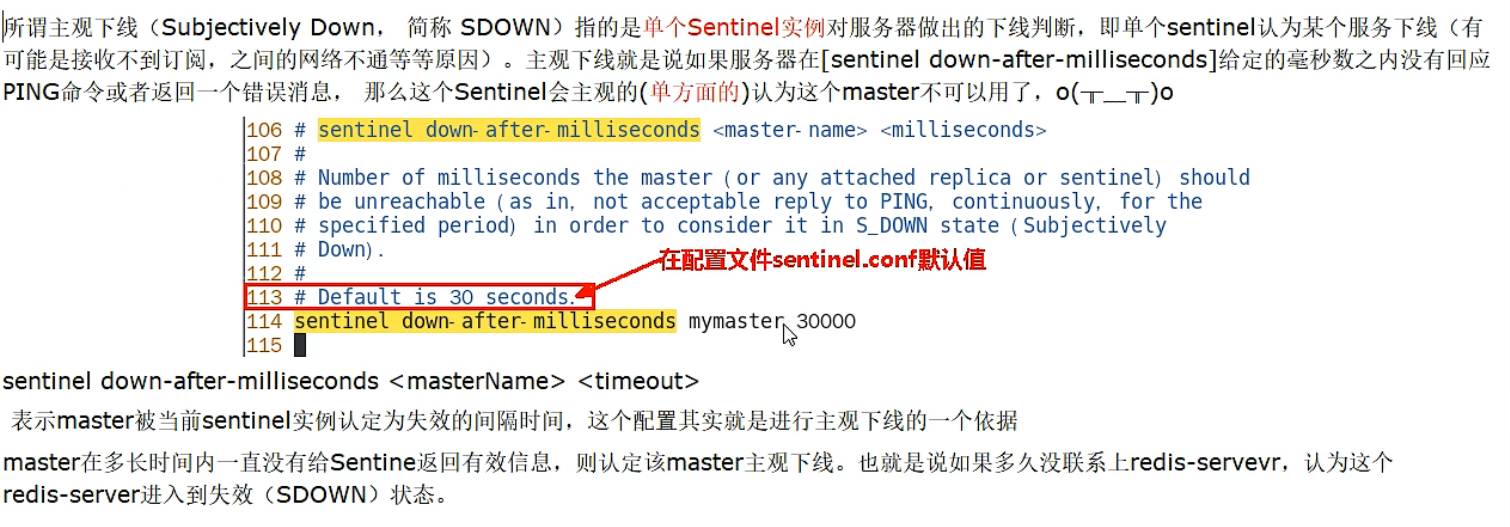
SDown主观下线(Subjectively Down)
- SDOWN(主观不可用)是单个sentinel自己主观上检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了SDOWN的条件。
- sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度。
说明:
ODown客观下线(Objectively Down)
- ODown需要一定数量的sentinel,多个哨兵达成一致意见才能人为一个master客观上已经宕掉
说明:

选举出领导者哨兵(哨兵中选出兵王)
**当主节点被判断客观下线以后,各个哨兵节点会进行协商,先选举出一个****领导者哨兵节点(兵王)**并由该领导者节点,也即被选举出的兵王进行failover(故障迁移)
三哨兵日志文件2次解读分析:
- sentinel26379.log
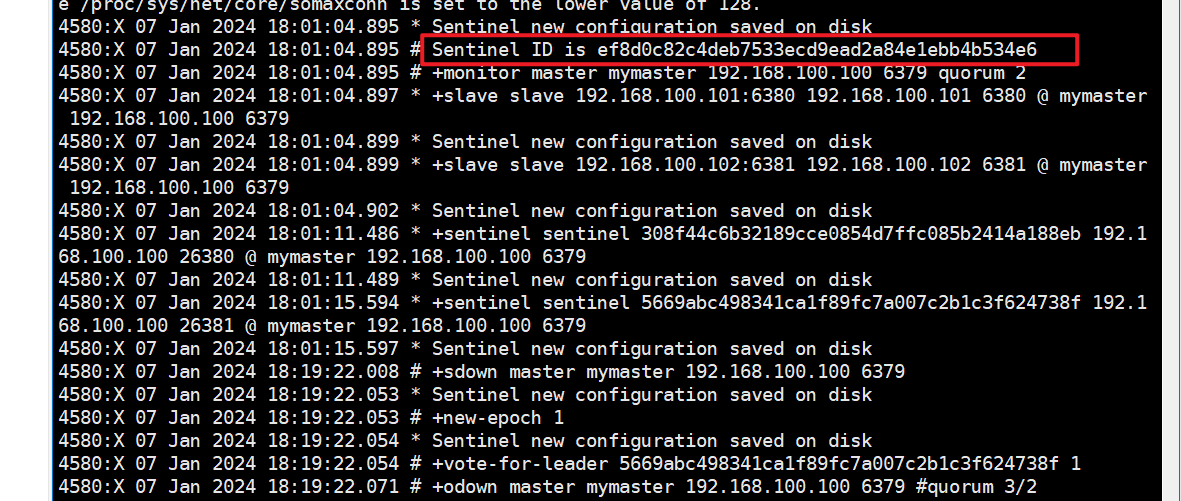
- sentinel26380.log
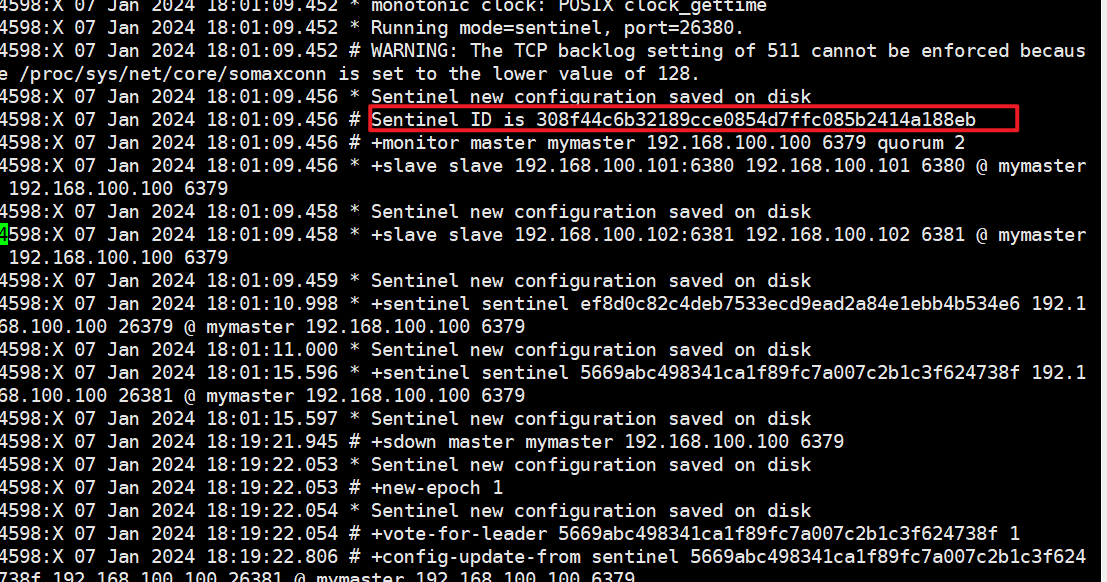
- sentinel26381.log
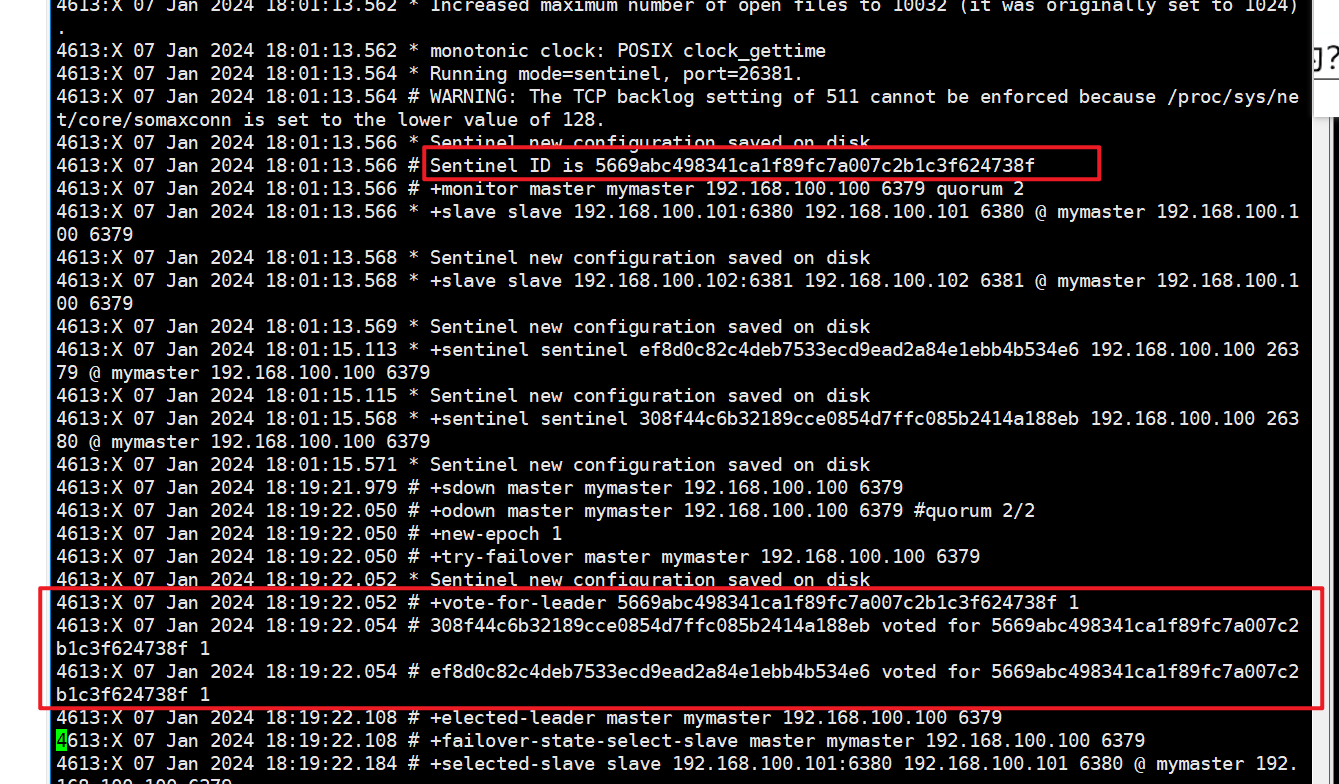
哨兵领导者,兵王是如何选出来的?
- Raft算法

由兵王开始推动故障切换流程并选出一个新master
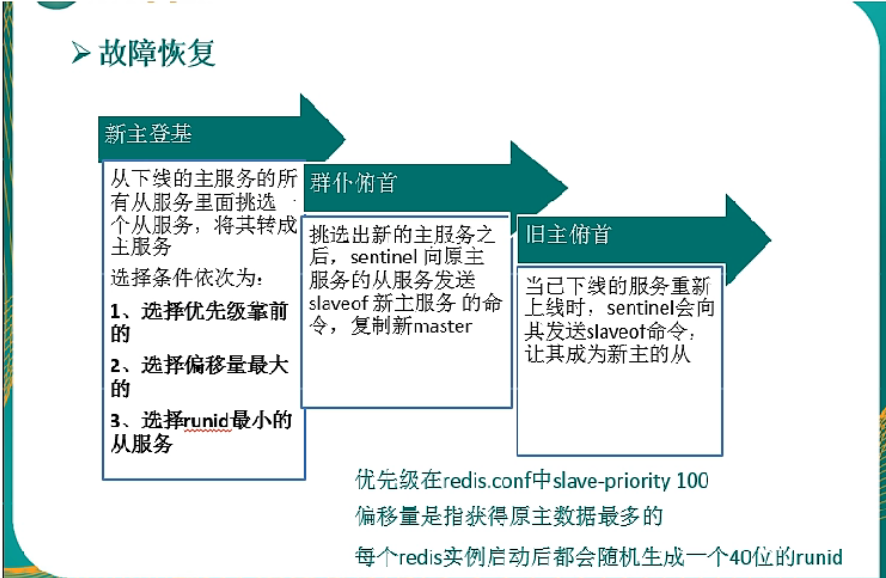
三步骤:
- 新主登基
某个Slave被选中成为新的master。
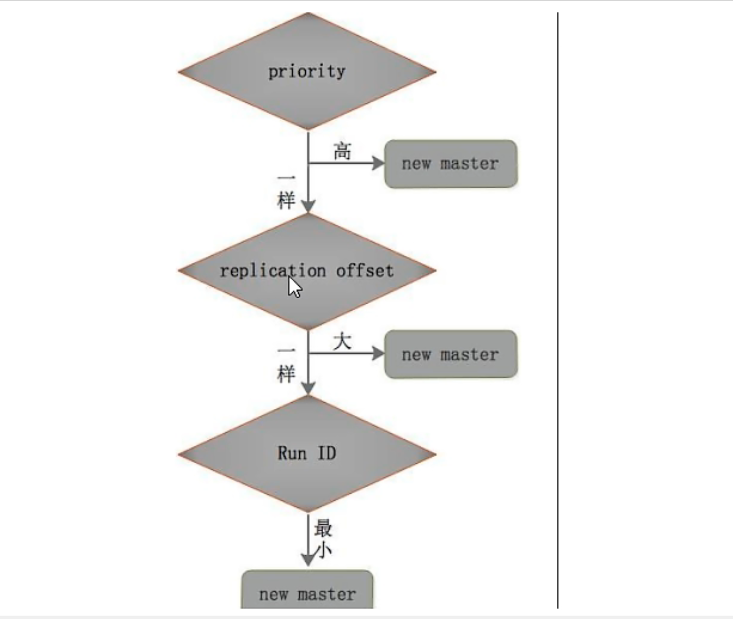
选出新master的规则,剩余slave节点健康情况下:
- redis.conf文件中,优先级slave-priority或者replica-priority最高的从节点(数字越小优先级越高)

- 复制偏移位置offset最大的从节点
- 最小的Run ID的从节点:字典顺序,ASCII码。
- 群臣俯首
一朝天子一朝臣,换个码头重新拜
执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其它节点成为其从节点。
sentinel leader会对选举出的新master执行slaveof no one操作,将其提升为master节点。
sentinel leader向其他slave发送命令,让剩余的slave成为新的master节点的slave。
- 旧主拜服
老master回来也认怂
将之前已下线的老master设置为新选出的新master的从节点,当老master重新上线后,他会成为新master的从节点。
sentinel leader会让原来的master降级为slave并恢复正常工作。
- 小总结
- 上述的failover操作均由sentinel自己独立完成,完全无需人工干预。
5、哨兵使用建议
- 哨兵节点的数量应该为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该是奇数。
- 各个哨兵节点的配置应一致。
- 各个哨兵节点部署在Docker等容器里面,尤其要注意端口的正确映射
- 哨兵集群+主从复制,并不能保证数据零丢失:承上启下引出集群。














 1594
1594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









