







目录
1 前言:
由于本人在学习该门课程时已经具备了一些ML、DL方面的基础知识,因此为了避免记录冗余知识,节约时间,本文仅在前人笔记的基础上记录一些对本人而言较为重要的知识点(相当于查漏补缺吧,哈哈,大家可以选择性浏览);
且吴恩达老师的课程教学基于tensorflow,但学术界目前最常使用的还是pytorch(本人经常用的也是pytoch),因此本笔记仅在实战部分记录一些重要的代码实践(远小于本课程的代码量);
注:本人在学习过程中借鉴了大量@虎幕的笔记,非常感谢这位博主优质笔记的帮助,本人主要是在其基础上记录一些对我而言较为重要的知识点、延申性质的课程补充内容以及部分实战篇。
- 本门课程是吴恩达团队于2022年在Coursera新开设的机器学习课程,不同于之前的老版本,该课程删去了SVM的模块;
- 新版本使用Python;
- 本次课程使用的是tensorflow2;
- 不要看视频本身自带的那个字幕,错误很多,点击b站在音量调节旁边的字幕选项,看那个;
- 神经网络部分是用TensorFlow实现的,现在主流使用的是pytorch,建议看完这个学会原理后,再去看看李沐老师(或者小土堆)的视频,学习用pytorch的代码实现。
2 吴恩达所有课程思维导图:
学习推荐!吴恩达 AI 课程及学习路线最全梳理-CSDN博客
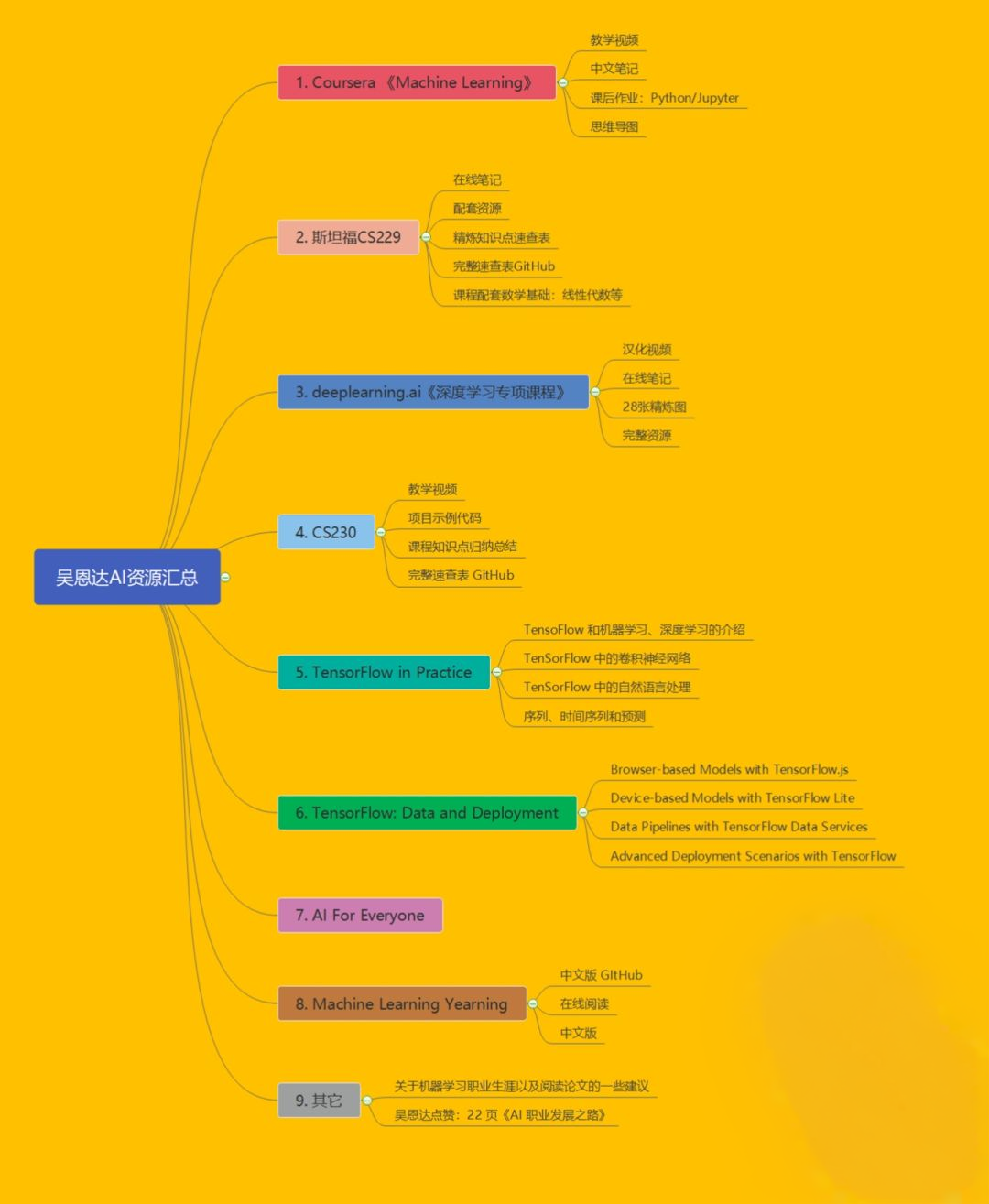
对于想要直接学习deeplearning.ai《深度学习专项课程》部分的同学而言,可以参考下面这篇文章再做决定:
吴恩达的机器学习课程和deeplearning.ai重复多吗? - 知乎 (zhihu.com)
3 课程资料:
教学视频:(强推|双字)最新吴恩达机器学习Deeplearning.ai课程_哔哩哔哩_bilibili
参考资料:kaieye/2022-Machine-Learning-Specialization (github.com)
4 参考笔记:
2022吴恩达机器学习笔记-目录 - 知乎 (zhihu.com)
撒花 | 吴恩达《Machine Learning》精炼笔记完整版发布! - 知乎 (zhihu.com)
【机器学习 吴恩达】2022课程笔记(持续更新)_2022吴恩达机器学习笔记-CSDN博客
5 课程大纲

和国内大部分课程结构不同,本套机器学习课程分为3个Course,每个Course又分为若干个Week,如上图所示。笔记的结构与课程大纲相同,由于每个Week中又包含10~20节不等的讲解视频,所以单篇笔记就包含单个Week的内容。
6 第一课:监督机器学习:回归与分类
目录
0 完整章节内容:
1 优质笔记:
2 重点:
2.1 机器学习的起源:
2.2 学习算法(Learning Algorithm) :
2.3 谈一下有监督学习和无监督学习是什么?
2.4 学习率 α 的选取将会对梯度下降的效率产生巨大影响。
2.5 为什么代价函数尽量要选择凸函数?
2.6 在多元线性回归中,为何要对数据进行向量化?
2.7 什么是正规方程法?有何局限性?
2.8 为啥特征缩放(feature scaling)可以使梯度下降法更快收敛?
2.9 请举出3种常见的特征缩放办法。
2.10 如何判断梯度下降是否收敛?
2.11 如何设置学习率呢?
2.12 特征工程
2.13 介绍一下Sigmod函数。
2.14 逻辑回归为啥可以学习相当复杂的数据集呢?
2.15 损失函数和代价函数的区别在哪?
2.16 逻辑回归的代价函数是什么?其相比于线性回归选取均方误差作为损失函数有何区分?
2.17 逻辑回归进行梯度下降的过程。
2.18 解决过拟合的三种方法。
2.19 介绍一下正则化的本质。
3 补充知识点:
3.1 在线性回归中,采用均方误差作为损失函数得到的代价函数中,其平方项中有一个分母 2 的原因?
3.2 在上述代价函数的优化过程中,我们是通过穷举而确认最佳的w和b的么?
3.3 为啥偏导数取负值的方向可以使得代价函数减小最快?
3.4 在梯度下降的过程中,学习率为啥是由大变小的?
3.5 介绍一下什么是批梯度下降,什么是小批梯度下降,什么是随机梯度下降?
3.6 先拆分数据集还是特征缩放呢?
3.7 逻辑回归名字中带有“回归”二字,但为啥是用于解决分类问题的呢?
3.8 解释一下机器学习中的偏差和方差。
3.9 为什么正则化项加上参数b(偏置)无影响?
3.10 在使用标准化 (StandardScaler()) 时,为什么要在训练集上使用fit_transform(),但是在测试集上使用transform()?
3.11 是先做特征选择还是先划分 训练集-验证集-测试集?
4 实战演练:
4.1 实战一(2-1):
4.2 实战二(2-2):
4.3 实战三(2-3):
4.4 实战四(2-4):
4.5 实战五(2-5):
4.6 实战六(2-8-1):
4.7 实战七(2-8-2):
4.8 实战八(2-9):
7 第二课:进阶的机器学习算法
目录
0 完整章节内容:
1 优质笔记:
2 神经网络发展史:
2.1 最初的提出:1940年代
2.2 第一个周期(1943—1986),感知器时代
2.2.1 第一代终结者:异或问题
2.2.2 《感知器》一书造成的影响
2.3 第二个周期(1986—2012),BP算法时代
2.3.1 具体过程
2.3.2 第二代终结者:收敛速度与泛化问题
2.3.3 造成的影响
2.3.4 前两个周期代表性算法(浅层学习)
2.4 第三个周期(2012年至今),深度学习时代
2.4.1 具体过程
2.4.2 为什么深度学习能战胜“第二代终结者”,取得这么好的成绩呢?
2.4.3 第三个周期代表性算法(深度学习)
2.5 会有第三代终结者么?
3 重点:
3.1 人脑的神经元和现在人工神经网络的关系
3.2 神经网络兴起的真正原因
3.3 关于神经网络的定义知识。
3.4 一个神经网络,输入层和输出层的含义不言而喻,那么其中的隐藏层是干嘛的呢?
3.5 ANI和AGI
3.6 tensorflow中编译compile()和训练fit()的细节。
3.7 介绍一下对数损失、BinaryCrossentropy以及MeanSquareError.
3.8 什么叫做线性激活函数?
3.9 之前的神经网络的隐藏层往往使用sigmod作为激活函数,现在往往使用Relu,为什么?
3.10 如何选择激活函数?
3.11 为什么需要激活函数?或者说隐藏层可以只使用线性激活函数么?
3.12 softmax的独特之处。
3.13 消除舍入误差。
3.14 什么是多标签问题?和多分类问题有何区别?
3.15 Adam优化器。
3.16 非密集型神经网络——卷积神经网络
3.17 有哪些神经网络层类型?
3.18 反向传播的具体过程。
3.19 什么时候进行二拆分合适。
3.20 如何选择合适的正则化参数呢?
3.21 性能评估的基准是什么呢?(和谁作比较才知道效果好不好呢?)
3.22 训练集的样本数量越多越好么?
3.23 如何改进模型?
3.24 神经网络独特的低偏差。
3.25 介绍一下L1正则化、L2正则化、弹性网之间的区别。
3.26 如何进行误差分析?
3.27 增加数据集的办法。
3.28 “迁移学习”的一般步骤及其注意事项
3.29 处理倾斜数据集时,需要哪些评价指标?
3.30 决策树中,哪些指标可以用于衡量“信息的不确定度”?
3.31 如何选择在每个节点使用什么特征进行拆分?
3.32 构建“决策树——二元输入特征”的步骤.
3.33 “构建决策树——多元输入特征”的步骤
3.34 “构建决策树——连续的输入特征”的步骤
3.35 “构建回归树——连续的输出结果”的步骤
3.36 三种常见的构建“决策树集合”的方法。
3.37 何时使用决策树?何时使用神经网络?
4 补充知识点:
4.1 你觉得逻辑回归和神经网络之间有什么联系?
4.2 torch中的tensor与numpy中array区别及用法
4.3 采用批梯度下降、小批梯度下降、随机梯度下降,batch_size分别应该设置为多少?
4.4 常见的损失函数有哪些?
4.5 常见的激活函数有哪些?
4.6 为啥N = 2 时,“Softmax回归”会退化成“逻辑回归”?
4.7 在用测试集验证的时候把梯度更新关掉不就没有训练过程了吗?那我们还需要再设置一个验证集吗?(需要进行三拆分么?)
4.8 简单介绍一下三种集成学习策略,Bagging、Boosting、Stacking。
5 实战演练:
5.1 环境配置过程
5.2 实战一:
5.3 实战二:
5.3 实战三:
8 第三课:无监督学习、推荐系统、强化学习
Course3:无监督学习、推荐系统、强化学习-CSDN博客
目录
0 完整章节内容:
1 优质笔记:
2 重点:
2.1 K-means算法的步骤.
2.2 K-means中,质心的随机初始化需要重复多次,为什么?
2.3 K-means的代价函数。
2.4 如何选择K-means的聚类数量。
2.5 什么是异常检测?异常检测有哪些应用场景?
2.6 “异常检测”算法的完整步骤:
2.7 如何选取阈值epsilon呢?
2.8 无监督学习需要选择恰当的特征
2.9 异常检测与有监督学习对比.
2.10 协同过滤算法——线性回归
2.11 协同过滤算法-逻辑回归
2.12 协同过滤算法——均值归一化
2.13 寻找相似的电影、协同过滤算法的缺点
2.14 “协同过滤”与“基于内容过滤”的 推荐原理 的对比
2.15 基于内容过滤的深度学习方法
2.16 基于内容过滤——实际检索情况:
2.17 主成分分析PCA应用现状:
2.18 PCA算法原理
2.19 强化学习原理:
3 补充知识点:
3.1 KNN和K-means有何不同?
3.2 在k-means或kNN,我们是用欧氏距离来计算最近的邻居之间的距离。为什么不用曼哈顿距离?
3.3 Kmeans中,为何曲线“拐点(肘部)”所对应的 K 就是最佳的聚类数量?
4 实战演练:
4.1 实战一:
4.2 实战二:
4.3 实战三:
4.4 实战四:
4.5 实战五:
4.6 实战六:


















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









