







目录
1 前言
本文为2021吴恩达学习笔记deeplearning.ai《深度学习专项课程》篇——“第二课——Week7”章节的课后练习,完整内容参见:
深度学习入门指南——2021吴恩达学习笔记deeplearning.ai《深度学习专项课程》篇-CSDN博客
2 Tensorflow 简单使用
欢迎来到本周的编程作业!到目前为止,你一直使用Numpy来构建神经网络,但本周你将探索一个深度学习框架,它可以让你更轻松地构建神经网络。机器学习框架,如TensorFlow、PaddlePaddle、Torch、Caffe、Keras等,可以显著加快机器学习的发展.
2.1 导包
import h5py
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.python.framework.ops import EagerTensor
from tensorflow.python.ops.resource_variable_ops import ResourceVariable
import timeimprov_utils.py:
import h5py
import numpy as np
import tensorflow as tf
import math
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[1] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((Y.shape[0],m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size : k * mini_batch_size + mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size : k * mini_batch_size + mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size : m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size : m]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)].T
return Y
def predict(X, parameters):
W1 = tf.convert_to_tensor(parameters["W1"])
b1 = tf.convert_to_tensor(parameters["b1"])
W2 = tf.convert_to_tensor(parameters["W2"])
b2 = tf.convert_to_tensor(parameters["b2"])
W3 = tf.convert_to_tensor(parameters["W3"])
b3 = tf.convert_to_tensor(parameters["b3"])
params = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
x = tf.placeholder("float", [12288, 1])
z3 = forward_propagation(x, params)
p = tf.argmax(z3)
with tf.Session() as sess:
prediction = sess.run(p, feed_dict = {x: X})
return prediction
def create_placeholders(n_x, n_y):
"""
Creates the placeholders for the tensorflow session.
Arguments:
n_x -- scalar, size of an image vector (num_px * num_px = 64 * 64 * 3 = 12288)
n_y -- scalar, number of classes (from 0 to 5, so -> 6)
Returns:
X -- placeholder for the data input, of shape [n_x, None] and dtype "float"
Y -- placeholder for the input labels, of shape [n_y, None] and dtype "float"
Tips:
- You will use None because it let's us be flexible on the number of examples you will for the placeholders.
In fact, the number of examples during test/train is different.
"""
### START CODE HERE ### (approx. 2 lines)
X = tf.placeholder("float", [n_x, None])
Y = tf.placeholder("float", [n_y, None])
### END CODE HERE ###
return X, Y
def initialize_parameters():
"""
Initializes parameters to build a neural network with tensorflow. The shapes are:
W1 : [25, 12288]
b1 : [25, 1]
W2 : [12, 25]
b2 : [12, 1]
W3 : [6, 12]
b3 : [6, 1]
Returns:
parameters -- a dictionary of tensors containing W1, b1, W2, b2, W3, b3
"""
tf.set_random_seed(1) # so that your "random" numbers match ours
### START CODE HERE ### (approx. 6 lines of code)
W1 = tf.get_variable("W1", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b1 = tf.get_variable("b1", [25,1], initializer = tf.zeros_initializer())
W2 = tf.get_variable("W2", [12,25], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b2 = tf.get_variable("b2", [12,1], initializer = tf.zeros_initializer())
W3 = tf.get_variable("W3", [6,12], initializer = tf.contrib.layers.xavier_initializer(seed = 1))
b3 = tf.get_variable("b3", [6,1], initializer = tf.zeros_initializer())
### END CODE HERE ###
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parameters
def compute_cost(z3, Y):
"""
Computes the cost
Arguments:
z3 -- output of forward propagation (output of the last LINEAR unit), of shape (10, number of examples)
Y -- "true" labels vector placeholder, same shape as z3
Returns:
cost - Tensor of the cost function
"""
# to fit the tensorflow requirement for tf.nn.softmax_cross_entropy_with_logits()
logits = tf.transpose(z3)
labels = tf.transpose(Y)
### START CODE HERE ### (1 line of code)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels))
### END CODE HERE ###
return cost
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,
num_epochs = 1500, minibatch_size = 32, print_cost = True):
"""
Implements a three-layer tensorflow neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SOFTMAX.
Arguments:
X_train -- training set, of shape (input size = 12288, number of training examples = 1080)
Y_train -- test set, of shape (output size = 6, number of training examples = 1080)
X_test -- training set, of shape (input size = 12288, number of training examples = 120)
Y_test -- test set, of shape (output size = 6, number of test examples = 120)
learning_rate -- learning rate of the optimization
num_epochs -- number of epochs of the optimization loop
minibatch_size -- size of a minibatch
print_cost -- True to print the cost every 100 epochs
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables
tf.set_random_seed(1) # to keep consistent results
seed = 3 # to keep consistent results
(n_x, m) = X_train.shape # (n_x: input size, m : number of examples in the train set)
n_y = Y_train.shape[0] # n_y : output size
costs = [] # To keep track of the cost
# Create Placeholders of shape (n_x, n_y)
### START CODE HERE ### (1 line)
X, Y = create_placeholders(n_x, n_y)
### END CODE HERE ###
# Initialize parameters
### START CODE HERE ### (1 line)
parameters = initialize_parameters()
### END CODE HERE ###
# Forward propagation: Build the forward propagation in the tensorflow graph
### START CODE HERE ### (1 line)
z3 = forward_propagation(X, parameters)
### END CODE HERE ###
# Cost function: Add cost function to tensorflow graph
### START CODE HERE ### (1 line)
cost = compute_cost(z3, Y)
### END CODE HERE ###
# Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer.
### START CODE HERE ### (1 line)
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
### END CODE HERE ###
# Initialize all the variables
init = tf.global_variables_initializer()
# Start the session to compute the tensorflow graph
with tf.Session() as sess:
# Run the initialization
sess.run(init)
# Do the training loop
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
# Select a minibatch
(minibatch_X, minibatch_Y) = minibatch
# IMPORTANT: The line that runs the graph on a minibatch.
# Run the session to execute the optimizer and the cost, the feedict should contain a minibatch for (X,Y).
### START CODE HERE ### (1 line)
_ , temp_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})
### END CODE HERE ###
minibatch_cost += temp_cost / num_minibatches
# Print the cost every epoch
if print_cost == True and epoch % 100 == 0:
print ("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 5 == 0:
costs.append(minibatch_cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# lets save the parameters in a variable
parameters = sess.run(parameters)
print ("Parameters have been trained!")
# Calculate the correct predictions
correct_prediction = tf.equal(tf.argmax(z3), tf.argmax(Y))
# Calculate accuracy on the test set
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Train Accuracy:", accuracy.eval({X: X_train, Y: Y_train}))
print ("Test Accuracy:", accuracy.eval({X: X_test, Y: Y_test}))
return parameterstest_utils.py:
import numpy as np
def datatype_check(expected_output, target_output, error):
success = 0
if isinstance(target_output, dict):
for key in target_output.keys():
try:
success += datatype_check(expected_output[key],
target_output[key], error)
except:
print("Error: {} in variable {}. Got {} but expected type {}".format(error,
key, type(target_output[key]), type(expected_output[key])))
if success == len(target_output.keys()):
return 1
else:
return 0
elif isinstance(target_output, tuple) or isinstance(target_output, list):
for i in range(len(target_output)):
try:
success += datatype_check(expected_output[i],
target_output[i], error)
except:
print("Error: {} in variable {}, expected type: {} but expected type {}".format(error,
i, type(target_output[i]), type(expected_output[i])))
if success == len(target_output):
return 1
else:
return 0
else:
assert isinstance(target_output, type(expected_output))
return 1
def equation_output_check(expected_output, target_output, error):
success = 0
if isinstance(target_output, dict):
for key in target_output.keys():
try:
success += equation_output_check(expected_output[key],
target_output[key], error)
except:
print("Error: {} for variable {}.".format(error,
key))
if success == len(target_output.keys()):
return 1
else:
return 0
elif isinstance(target_output, tuple) or isinstance(target_output, list):
for i in range(len(target_output)):
try:
success += equation_output_check(expected_output[i],
target_output[i], error)
except:
print("Error: {} for variable in position {}.".format(error, i))
if success == len(target_output):
return 1
else:
return 0
else:
if hasattr(target_output, 'shape'):
np.testing.assert_array_almost_equal(
target_output, expected_output)
else:
assert target_output == expected_output
return 1
def shape_check(expected_output, target_output, error):
success = 0
if isinstance(target_output, dict):
for key in target_output.keys():
try:
success += shape_check(expected_output[key],
target_output[key], error)
except:
print("Error: {} for variable {}.".format(error, key))
if success == len(target_output.keys()):
return 1
else:
return 0
elif isinstance(target_output, tuple) or isinstance(target_output, list):
for i in range(len(target_output)):
try:
success += shape_check(expected_output[i],
target_output[i], error)
except:
print("Error: {} for variable {}.".format(error, i))
if success == len(target_output):
return 1
else:
return 0
else:
if hasattr(target_output, 'shape'):
assert target_output.shape == expected_output.shape
return 1
def single_test(test_cases, target):
success = 0
for test_case in test_cases:
try:
if test_case['name'] == "datatype_check":
assert isinstance(target(*test_case['input']),
type(test_case["expected"]))
success += 1
if test_case['name'] == "equation_output_check":
assert np.allclose(test_case["expected"],
target(*test_case['input']))
success += 1
if test_case['name'] == "shape_check":
assert test_case['expected'].shape == target(
*test_case['input']).shape
success += 1
except:
print("Error: " + test_case['error'])
if success == len(test_cases):
print("\033[92m All tests passed.")
else:
print('\033[92m', success, " Tests passed")
print('\033[91m', len(test_cases) - success, " Tests failed")
raise AssertionError(
"Not all tests were passed for {}. Check your equations and avoid using global variables inside the function.".format(target.__name__))
def multiple_test(test_cases, target):
success = 0
for test_case in test_cases:
try:
target_answer = target(*test_case['input'])
if test_case['name'] == "datatype_check":
success += datatype_check(test_case['expected'],
target_answer, test_case['error'])
if test_case['name'] == "equation_output_check":
success += equation_output_check(
test_case['expected'], target_answer, test_case['error'])
if test_case['name'] == "shape_check":
success += shape_check(test_case['expected'],
target_answer, test_case['error'])
except:
print("Error: " + test_case['error'])
if success == len(test_cases):
print("\033[92m All tests passed.")
else:
print('\033[92m', success, " Tests passed")
print('\033[91m', len(test_cases) - success, " Tests failed")
raise AssertionError(
"Not all tests were passed for {}. Check your equations and avoid using global variables inside the function.".format(target.__name__))
tf_utils.py:
import h5py
import numpy as np
import tensorflow as tf
import math
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[1] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((Y.shape[0],m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size : k * mini_batch_size + mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size : k * mini_batch_size + mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size : m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size : m]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)].T
return Y
def predict(X, parameters):
W1 = tf.convert_to_tensor(parameters["W1"])
b1 = tf.convert_to_tensor(parameters["b1"])
W2 = tf.convert_to_tensor(parameters["W2"])
b2 = tf.convert_to_tensor(parameters["b2"])
W3 = tf.convert_to_tensor(parameters["W3"])
b3 = tf.convert_to_tensor(parameters["b3"])
params = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
x = tf.placeholder("float", [12288, 1])
z3 = forward_propagation_for_predict(x, params)
p = tf.argmax(z3)
sess = tf.Session()
prediction = sess.run(p, feed_dict = {x: X})
return prediction
def forward_propagation_for_predict(X, parameters):
"""
Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
# Numpy Equivalents:
Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3
return Z3
2.2 检查 TensorFlow 版本
您将在本次作业中使用v2.3+,以获得最大的速度和效率。
tf.__version__'2.4.0'
2.3 基本优化与梯度计算图
TensorFlow 2的美妙之处在于它的简单。基本上,您所需要做的就是通过计算图实现前向传播。TensorFlow将通过“GradientTape”记录的图形向后移动,为您计算导数。剩下你要做的就是指定你想要使用的代价函数和优化器!
在编写TensorFlow程序时,要使用和转换的主要对象是“tf.Tensor”。这些张量相当于Numpy数组,即给定数据类型的多维数组,也包含有关计算图的信息。
下面,你将使用“tf”。变量’来存储变量的状态。变量只能创建一次,因为它的初始值定义了变量的形状和类型。此外,`tf `中的`dtype`参数。变量'可以设置为允许将数据转换为该类型。但是如果没有指定,如果初始值是张量,则数据类型将被保留,或者‘ convert_to_tensor ’将决定。通常最好是直接指定,这样就不会出错!
在这里,您将调用在HDF5文件上创建的TensorFlow数据集,您可以使用它来代替Numpy数组来存储数据集。你可以把它想象成一个TensorFlow数据生成器!
您将使用手势数据集,该数据集由形状为64x64x3的图像组成。
train_dataset = h5py.File('datasets/train_signs.h5', "r")
test_dataset = h5py.File('datasets/test_signs.h5', "r")
train_dataset["train_set_x"]<HDF5 dataset "train_set_x": shape (1080, 64, 64, 3), type "|u1">
# tf.data.Dataset.from_tensor_slices( list_or_numpy_array ) creates TensorFlow Datasets
x_train = tf.data.Dataset.from_tensor_slices(train_dataset['train_set_x'])
y_train = tf.data.Dataset.from_tensor_slices(train_dataset['train_set_y'])
x_test = tf.data.Dataset.from_tensor_slices(test_dataset['test_set_x'])
y_test = tf.data.Dataset.from_tensor_slices(test_dataset['test_set_y'])
type(x_train)tensorflow.python.data.ops.dataset_ops.TensorSliceDataset
由于TensorFlow数据集是生成器,你不能直接访问内容,除非你在for循环中迭代它们,或者通过使用‘ iter ’显式创建Python迭代器并使用‘ next ’。此外,您可以使用“element_spec”属性检查每个元素的“形状”和“dtype”。
print(x_train.element_spec)
print(next(iter(x_train)))TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None)
tf.Tensor(
[[[227 220 214]
[227 221 215]
[227 222 215]
...
[232 230 224]
[231 229 222]
[230 229 221]][[227 221 214]
[227 221 215]
[228 221 215]
...
[232 230 224]
[231 229 222]
[231 229 221]][[227 221 214]
[227 221 214]
[227 221 215]
...
[232 230 224]
[231 229 223]
[230 229 221]]...
[[119 81 51]
[124 85 55]
[127 87 58]
...
[210 211 211]
[211 212 210]
[210 211 210]][[119 79 51]
[124 84 55]
[126 85 56]
...
[210 211 210]
[210 211 210]
[209 210 209]][[119 81 51]
[123 83 55]
[122 82 54]
...
[209 210 210]
[209 210 209]
[208 209 209]]], shape=(64, 64, 3), dtype=uint8)
for element in x_train:
print(element)
breaktf.Tensor(
[[[227 220 214]
[227 221 215]
[227 222 215]
...
[232 230 224]
[231 229 222]
[230 229 221]][[227 221 214]
[227 221 215]
[228 221 215]
...
[232 230 224]
[231 229 222]
[231 229 221]][[227 221 214]
[227 221 214]
[227 221 215]
...
[232 230 224]
[231 229 223]
[230 229 221]]...
[[119 81 51]
[124 85 55]
[127 87 58]
...
[210 211 211]
[211 212 210]
[210 211 210]][[119 79 51]
[124 84 55]
[126 85 56]
...
[210 211 210]
[210 211 210]
[209 210 209]][[119 81 51]
[123 83 55]
[122 82 54]
...
[209 210 210]
[209 210 209]
[208 209 209]]], shape=(64, 64, 3), dtype=uint8)
TensorFlow数据集和Numpy数组之间还有一个额外的区别:如果您需要转换一个数据集,您将调用‘ map ’方法来将作为参数传递的函数应用于每个元素。
def normalize(image):
image = tf.cast(image, tf.float32) / 256.0
image = tf.reshape(image, [-1,1])
return image
new_train = x_train.map(normalize)
new_test = x_test.map(normalize)
new_train.element_specTensorSpec(shape=(12288, 1), dtype=tf.float32, name=None)
print(next(iter(new_train)))tf.Tensor(
[[0.88671875]
[0.859375 ]
[0.8359375 ]
...
[0.8125 ]
[0.81640625]
[0.81640625]], shape=(12288, 1), dtype=float32)
2.4 线性函数
# GRADED FUNCTION: linear_function
def linear_function():
np.random.seed(1)
X = tf.constant(np.random.randn(3,1))
W = tf.constant(np.random.randn(4,3))
b = tf.constant(np.random.randn(4,1))
Y = tf.add(tf.matmul(W,X),b)
return Yresult = linear_function()
print(result)
assert type(result) == EagerTensor, "Use the TensorFlow API"
assert np.allclose(result, [[-2.15657382], [ 2.95891446], [-1.08926781], [-0.84538042]]), "Error"
print("\033[92mAll test passed")
tf.Tensor(
[[-2.15657382]
[ 2.95891446]
[-1.08926781]
[-0.84538042]], shape=(4, 1), dtype=float64)
All test passed
2.5 计算Sigmoid
# GRADED FUNCTION: sigmoid
def sigmoid(z):
z = tf.cast(z,tf.float32)
a = tf.keras.activations.sigmoid(z)
return aresult = sigmoid(-1)
print ("type: " + str(type(result)))
print ("dtype: " + str(result.dtype))
print ("sigmoid(-1) = " + str(result))
print ("sigmoid(0) = " + str(sigmoid(0.0)))
print ("sigmoid(12) = " + str(sigmoid(12)))
def sigmoid_test(target):
result = target(0)
assert(type(result) == EagerTensor)
assert (result.dtype == tf.float32)
assert sigmoid(0) == 0.5, "Error"
assert sigmoid(-1) == 0.26894143, "Error"
assert sigmoid(12) == 0.9999938, "Error"
print("\033[92mAll test passed")
sigmoid_test(sigmoid)type: <class 'tensorflow.python.framework.ops.EagerTensor'>
dtype: <dtype: 'float32'>
sigmoid(-1) = tf.Tensor(0.26894143, shape=(), dtype=float32)
sigmoid(0) = tf.Tensor(0.5, shape=(), dtype=float32)
sigmoid(12) = tf.Tensor(0.9999938, shape=(), dtype=float32)
All test passed
2.6 使用独热编码
# GRADED FUNCTION: one_hot_matrix
def one_hot_matrix(label, depth=6):
one_hot = tf.one_hot(label,depth,axis=0)
one_hot = tf.reshape(one_hot,[depth,1])
return one_hotdef one_hot_matrix_test(target):
label = tf.constant(1)
depth = 4
result = target(label, depth)
print(result)
assert result.shape[0] == depth, "Use the parameter depth"
assert result.shape[1] == 1, f"Reshape to have only 1 column"
assert np.allclose(result, [[0.], [1.], [0.], [0.]] ), "Wrong output. Use tf.one_hot"
result = target(3, depth)
assert np.allclose(result, [[0.], [0.], [0.], [1.]] ), "Wrong output. Use tf.one_hot"
print("\033[92mAll test passed")
one_hot_matrix_test(one_hot_matrix)tf.Tensor(
[[0.]
[1.]
[0.]
[0.]], shape=(4, 1), dtype=float32)
All test passed
new_y_test = y_test.map(one_hot_matrix)
new_y_train = y_train.map(one_hot_matrix)
print(next(iter(new_y_test)))tf.Tensor(
[[1.]
[0.]
[0.]
[0.]
[0.]
[0.]], shape=(6, 1), dtype=float32)
2.7 初始化参数
# GRADED FUNCTION: initialize_parameters
def initialize_parameters():
initializer = tf.keras.initializers.GlorotNormal(seed=1)
W1 = tf.Variable(initializer(shape=(25, 12288)))
b1 = tf.Variable(initializer(shape=(25, 1)))
W2 = tf.Variable(initializer(shape=(12, 25)))
b2 = tf.Variable(initializer(shape=(12, 1)))
W3 = tf.Variable(initializer(shape=(6,12)))
b3 = tf.Variable(initializer(shape=(6, 1)))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parametersdef initialize_parameters_test(target):
parameters = target()
values = {"W1": (25, 12288),
"b1": (25, 1),
"W2": (12, 25),
"b2": (12, 1),
"W3": (6, 12),
"b3": (6, 1)}
for key in parameters:
print(f"{key} shape: {tuple(parameters[key].shape)}")
assert type(parameters[key]) == ResourceVariable, "All parameter must be created using tf.Variable"
assert tuple(parameters[key].shape) == values[key], f"{key}: wrong shape"
assert np.abs(np.mean(parameters[key].numpy())) < 0.5, f"{key}: Use the GlorotNormal initializer"
assert np.std(parameters[key].numpy()) > 0 and np.std(parameters[key].numpy()) < 1, f"{key}: Use the GlorotNormal initializer"
print("\033[92mAll test passed")
initialize_parameters_test(initialize_parameters)W1 shape: (25, 12288)
b1 shape: (25, 1)
W2 shape: (12, 25)
b2 shape: (12, 1)
W3 shape: (6, 12)
b3 shape: (6, 1)
All test passed
parameters = initialize_parameters()2.8 在TensorFlow中构建你的第一个神经网络
实现正向传播
# GRADED FUNCTION: forward_propagation
@tf.function
def forward_propagation(X, parameters):
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
Z1 = tf.add(tf.matmul(W1,X),b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.keras.activations.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2,A1),b2) # Z2 = np.dot(W2, A1) + b2
A2 = tf.keras.activations.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3,A2),b3) # Z3 = np.dot(W3, A2) + b3
return Z3def forward_propagation_test(target, examples):
for batch in examples:
forward_pass = target(batch, parameters)
assert type(forward_pass) == EagerTensor, "Your output is not a tensor"
assert forward_pass.shape == (6, 1), "Last layer must use W3 and b3"
assert np.any(forward_pass < 0), "Don't use a ReLu layer at end of your network"
assert np.allclose(forward_pass,
[[-0.13082162],
[ 0.21228778],
[ 0.7050022 ],
[-1.1224034 ],
[-0.20386729],
[ 0.9526217 ]]), "Output does not match"
print(forward_pass)
break
print("\033[92mAll test passed")
forward_propagation_test(forward_propagation, new_train)tf.Tensor(
[[-0.1308215 ]
[ 0.21228784]
[ 0.7050022 ]
[-1.1224034 ]
[-0.20386738]
[ 0.9526218 ]], shape=(6, 1), dtype=float32)
All test passed
计算代价函数
# GRADED FUNCTION: compute_cost
@tf.function
def compute_cost(logits, labels):
cost = tf.reduce_mean(tf.keras.losses.binary_crossentropy(labels,logits,from_logits=True))
return costdef compute_cost_test(target):
labels = np.array([[0., 1.], [0., 0.], [1., 0.]])
logits = np.array([[0.6, 0.4], [0.4, 0.6], [0.4, 0.6]])
result = compute_cost(logits, labels)
print(result)
assert(type(result) == EagerTensor), "Use the TensorFlow API"
assert (np.abs(result - (0.7752516 + 0.9752516 + 0.7752516) / 3.0) < 1e-7), "Test does not match. Did you get the mean of your cost functions?"
print("\033[92mAll test passed")
compute_cost_test(compute_cost)tf.Tensor(0.8419182681095857, shape=(), dtype=float64)
All test passed
训练模型
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,
num_epochs = 1500, minibatch_size = 32, print_cost = True):
costs = [] # To keep track of the cost
# Initialize your parameters
parameters = initialize_parameters()
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
optimizer = tf.keras.optimizers.SGD(learning_rate)
X_train = X_train.batch(minibatch_size, drop_remainder=True).prefetch(8)# <<< extra step
Y_train = Y_train.batch(minibatch_size, drop_remainder=True).prefetch(8) # loads memory faster
# Do the training loop
for epoch in range(num_epochs):
epoch_cost = 0.
for (minibatch_X, minibatch_Y) in zip(X_train, Y_train):
# Select a minibatch
with tf.GradientTape() as tape:
# 1. predict
Z3 = forward_propagation(minibatch_X, parameters)
# 2. loss
minibatch_cost = compute_cost(Z3, minibatch_Y)
trainable_variables = [W1, b1, W2, b2, W3, b3]
grads = tape.gradient(minibatch_cost, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
epoch_cost += minibatch_cost / minibatch_size
# Print the cost every epoch
if print_cost == True and epoch % 10 == 0:
print ("Cost after epoch %i: %f" % (epoch, epoch_cost))
if print_cost == True and epoch % 5 == 0:
costs.append(epoch_cost)
# Plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per fives)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# Save the parameters in a variable
print ("Parameters have been trained!")
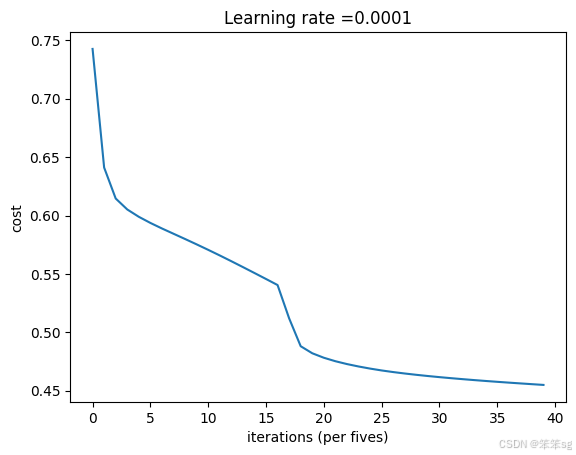
return parametersmodel(new_train, new_y_train, new_test, new_y_test, num_epochs=200)Cost after epoch 0: 0.742591
Cost after epoch 10: 0.614557
Cost after epoch 20: 0.598900
Cost after epoch 30: 0.588907
Cost after epoch 40: 0.579898
Cost after epoch 50: 0.570628
Cost after epoch 60: 0.560898
Cost after epoch 70: 0.550808
Cost after epoch 80: 0.540497
Cost after epoch 90: 0.488141
Cost after epoch 100: 0.478272
Cost after epoch 110: 0.472865
Cost after epoch 120: 0.468991
Cost after epoch 130: 0.466015
Cost after epoch 140: 0.463661
Cost after epoch 150: 0.461677
Cost after epoch 160: 0.459951
Cost after epoch 170: 0.458392
Cost after epoch 180: 0.456970
Cost after epoch 190: 0.455647
祝贺 !你已经完成了这次作业,在TensorFlow 2.4中构建神经网络的惊人工作!
以下是对你刚刚取得的成就的快速回顾:
-用“tf”。变量'来修改变量
-应用TensorFlow装饰器,观察它们如何加速你的代码
-在TensorFlow数据集上训练神经网络
-应用批处理归一化,使网络更健壮


















 2733
2733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









